
Written by Leonardo Losoviz ✏️
GraphQL is all about having a single endpoint to query the data, but there are situations where it makes sense to instead have multiple endpoints, where each custom endpoint exposes a customized schema. This allows us to provide a distinct behavior for different users or applications by simply swapping the accessed endpoint.
Exposing multiple endpoints in GraphQL is not the same as implementing REST — every REST endpoint provides access to a predefined resource or set of resources. But with multiple GraphQL endpoints, each one will still provide access to all of the data from its schema, enabling us to fetch exactly what we need.
This is still the normal GraphQL behavior but now gives us the ability to access the data from different schemas. This capability is also different than schema stitching or federation, which enable us to incorporate several sources of data into a single, unified graph.
With multiple endpoints, we are still dealing with multiple schemas. Each schema can be accessed on its own and is independent of all others. In contrast, stitching and federation combine all the schemas into a bigger schema, and the different schemas may need to be reconciled with one another (e.g., by renaming types or fields in case of conflict).
Exposing different schemas can provide us access to multiple independent graphs. GraphQL creator Lee Byron explains when this can be useful:
A good example of this might be if you've company [sic] is centered around a product and has built a GraphQL API for that product, and then decides to expand into a new business domain with a new product that doesn't relate to the original product. It could be a burden for both of these unrelated products to share a single API and two separate endpoints with different schema may be more appropriate. [...] Another example is [...] you may have a separate internal-only endpoint that is a superset of your external GraphQL API. Facebook uses this pattern and has two endpoints, one internal and one external. The internal one includes internal tools which can interact with product types.
In this article, we will expand on each of these examples and explore several use cases where exposing multiple GraphQL endpoints makes sense.
How to expose multiple GraphQL endpoints
Before we explore the use cases, let's review how the GraphQL server can expose multiple endpoints.
There are a few GraphQL servers that already ship with this feature:
- PostGraphile’s multiple schemas
- GraphQL.NET’s multi-schema support
- GraphQL API for WordPress’s custom endpoints
If the GraphQL server we are using doesn’t provide multiple endpoints as an inbuilt feature, we can attempt to code it in our application. The idea is to define several GraphQL schemas, and tell the server which one to use on runtime, based on the requested endpoint.
When using a JavaScript server, a convenient way to achieve this is with GraphQL Helix, which decouples the handling of the HTTP request from the GraphQL server. With Helix, we can have the routing logic be handled by a Node.js web framework (such as Express.js or Fastify), and then — depending on the requested path (i.e., the requested endpoint — we can provide the corresponding schema to the GraphQL server.
Let's convert Helix's basic example, which is based on Express, into a multi-endpoint solution. The following code handles the single endpoint /graphql:
import express from "express";
import { schema } from "./my-awesome-schema";
const app = express();
app.use(express.json());
app.use("/graphql", async (res, req) => {
// ...
});
app.listen(8000);
To handle multiple endpoints, we can expose URLs with shape /graphql/${customEndpoint}, and obtain the custom endpoint value via a route parameter. Then, based on the requested custom endpoint, we identify the schema — in this case, from the endpoints /graphql/clients, /graphql/providers, and /graphql/internal:
import { clientSchema } from "./schemas/clients";
import { providerSchema } from "./schemas/providers";
import { internalSchema } from "./schemas/internal";
// ...
app.use("/graphql/:customEndpoint", async (res, req) => {
let schema = {};
if (req.params.customEndpoint === 'clients') {
schema = clientSchema;
} else if (req.params.customEndpoint === 'providers') {
schema = providerSchema;
} else if (req.params.customEndpoint === 'internal') {
schema = internalSchema;
} else {
throw new Error('Non-supported endpoint');
}
// ...
});
Once we have the schema, we inject it into the GraphQL server, as expected by Helix:
const request = {
body: req.body,
headers: req.headers,
method: req.method,
query: req.query,
};
const {
query,
variables,
operationName
} = getGraphQLParameters(request);
const result = await processRequest({
schema,
query,
variables,
operationName,
request,
})
if (result.type === "RESPONSE") {
result.headers.forEach(({ name, value }) => {
res.setHeader(name, value)
});
res.status(result.status);
res.json(result.payload);
} else {
// ...
}
Needless to say, the different schemas can themselves share code, so there is no need to duplicate logic when exposing common fields.
For instance, /graphql/clients can expose a basic schema and export its elements:
// File: schemas/clients.ts
export const clientSchemaQueryFields = {
// ...
};
export const clientSchema = new GraphQLSchema({
query: new GraphQLObjectType({
name: "Query",
fields: clientSchemaQueryFields,
}),
});
And these elements can be imported into the schema for /graphql/providers:
// File: schemas/providers.ts
import { clientSchemaQueryFields } from "./clients";
export const providerSchemaQueryFields = {
// ...
};
export const providerSchema = new GraphQLSchema({
query: new GraphQLObjectType({
name: "Query",
fields: { ...clientSchemaQueryFields, ...providerSchemaQueryFields },
}),
});
Next, let's explore the several use cases where multiple GraphQL endpoints can make sense. We’ll be looking at the following use cases:
- Exposing the admin and public endpoints separately
- Restricting access to private information in a safer way
- Providing different behavior to different applications
- Generating a site in different languages
- Testing an upgraded schema before releasing for production
- Supporting the BfF approach
Exposing the admin and public endpoints separately
When we are using a single graph for all data in the company, we can validate who has access to the different fields in our GraphQL schema by setting up access control policies. For instance, we can configure fields to be accessible only to logged-in users via directive @auth, and to users with a certain role via an additional directive @protect(role: "EDITOR").
However, this mechanism may be unsafe if the software has bugs, or if the team is not always careful. For instance, if the developer forgets to add the directive to the field, or adds it only for the DEV environment but not for PROD, then the field will be accessible to everyone, presenting a security risk.
If the field contains sensitive or confidential information — especially the kind that should under no circumstance be accessible to unintended actors — then we'd rather not expose this field in a public schema in first place, only in a private schema to which only the team has access. This strategy will protect our private data from bugs and carelessness.
Hence, we can create two separate schemas, the Admin and Public schemas, and expose them under endpoints /graphql/admin and /graphql respectively.
Restricting access to private information in a safer way
Though we’ll be looking at the example I described above, this section can also be read as a generalization of it: this can be regarded as applicable not just in public vs. admin scenarios, but in any situation in which a set of users must absolutely not be able to access information from another set of users.
For instance, whenever we need to create customized schemas for our different clients, we can expose a custom endpoint for each of them (/graphql/some-client, /graphql/another-client, etc), which can be safer than giving them access to the same unified schema and validating them via access control.
This is because we can easily validate access to these endpoints by IP address. The code below expands on the previous example using Helix and Express to validate that the endpoint /graphql/star-client can only be accessed from the client's specific IP address:
import { starClientSchema } from "./schemas/star-client";
// Define the client's IP
const starClientIP = "99.88.77.66";
app.use("/graphql/:customEndpoint", async (res, req) => {
let schema = {};
const ip = req.ip
|| req.headers['x-forwarded-for']
|| req.connection.remoteAddress
|| req.socket.remoteAddress
|| req.connection.socket.remoteAddress;
if (req.params.customEndpoint === 'star-client') {
if (ip !== starClientIP) {
throw new Error('Invalid IP');
}
schema = starClientSchema;
}
// ...
});
For your clients, knowing that they can only access the endpoint with their data from their own IP address also gives them the reassurance that their data is well protected.
Providing different behavior to different applications
We can grant different behavior to the different applications that access the same data source.
For instance, I've noticed that Reddit produces different responses when accessed from a desktop browser than it does when accessed from a mobile browser. From the desktop browser, whether we are logged-in or not, we can directly visualize the content:
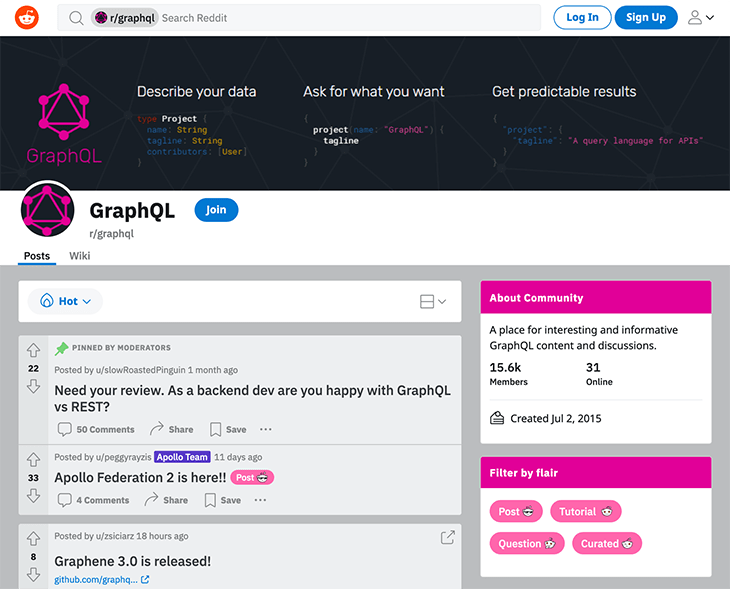
Accessing from mobile, though, we must be logged-in to access the content, and we're encouraged to use the app instead:
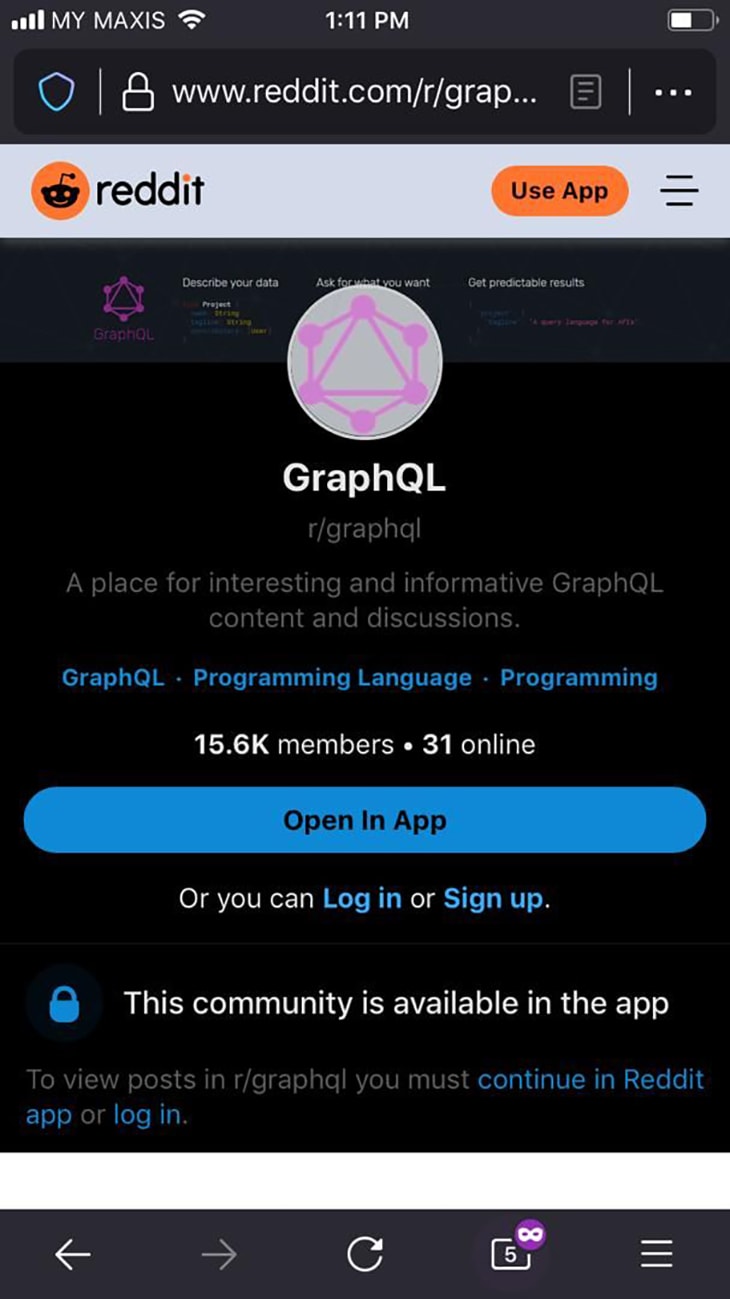
This different behavior could be provided by creating two schemas, such as the Desktop and Mobile schemas, and expose them under /graphql/desktop and /graphql/mobile respectively.
Generating a site in different languages
Let's say that we want to generate the same site in different languages. If GraphQL is being used as the unique source of data, such as when creating a static site with Gatsby, then we can translate the data while it’s in transit between the data source and the application.
As a matter of fact, we do not really need multiple endpoints to achieve this goal. For instance, we can retrieve the language code from an environment variable LANGUAGE_CODE, inject this value into GraphQL variable $lang, and then translate the post's title and content fields via the field argument translateTo:
query GetTranslatedPost($lang: String!) {
post(id: 1) {
title(translateTo: $lang)
content(translateTo: $lang)
}
}
However, translation is a cross-cutting concern, for which using a directive may be more appropriate. By using schema-type directives, the query can be oblivious that it will be translated:
{
post(id: 1) {
title
content
}
}
Then, the translation logic is applied on the schema, via a @translate directive added to the fields in the SDL:
directive @translate(translateTo: String) on FIELD
type Post {
title @translate(translateTo: "fr")
content @translate(translateTo: "fr")
}
(Note that the directive argument translateTo is non-mandatory, so that, when not provided, it uses the default value set via environment variable LANGUAGE_CODE.)
Now that the language is injected into the schema, we can create different schemas for different languages, such as /graphql/en for English and /graphql/fr for French.
Finally, we point to each of these endpoints in the application to produce the site in one language or another:

Testing an upgraded schema before releasing for production
If we want to upgrade our GraphQL schema and have a set of users test it in advance, we can expose this new schema via a /graphql/upcoming endpoint. Even more, we could also expose a /graphql/bleeding-edge endpoint that keeps deploying the schema from DEV.
Supporting the BfF approach
Backend-for-Frontends (BfF for short) is an approach for producing different APIs for different clients where each client "owns" its own API, which allows it to produce the most optimal version based on its own requirements.
In this model, a custom BfF is the middleman between backend services and its client:
 This model can be satisfied in GraphQL by implementing all BfFs in a single GraphQL server with multiple endpoints, with each endpoint tackling a specific BfF/client (such as
This model can be satisfied in GraphQL by implementing all BfFs in a single GraphQL server with multiple endpoints, with each endpoint tackling a specific BfF/client (such as /graphql/mobile and /graphql/web):

Conclusion
GraphQL was born as an alternative to REST, focused on retrieving data with no under- or overfetching, making it extremely efficient. The way to accomplish this goal is by exposing a single endpoint, to which we provide the query to fetch the data.
Exposing a single endpoint works well in most cases, but may fall short whenever we need to produce completely different schemas that are customized to different clients or applications. In this case, exposing multiple endpoints, at one endpoint per schema, could be more appropriate.
In this article, we explored different examples of when this makes sense, and how to implement it.
Monitor failed and slow GraphQL requests in production
While GraphQL has some features for debugging requests and responses, making sure GraphQL reliably serves resources to your production app is where things get tougher. If you’re interested in ensuring network requests to the backend or third party services are successful, try LogRocket.

LogRocket is like a DVR for web apps, recording literally everything that happens on your site. Instead of guessing why problems happen, you can aggregate and report on problematic GraphQL requests to quickly understand the root cause. In addition, you can track Apollo client state and inspect GraphQL queries' key-value pairs.
LogRocket instruments your app to record baseline performance timings such as page load time, time to first byte, slow network requests, and also logs Redux, NgRx, and Vuex actions/state. Start monitoring for free.

Top comments (0)