
In week 2 we took a look at memory and how we could use arrays to store data. Now, in week 4, David Malan goes a bit deeper into memory management, introducing us to memory addresses, pointers, and memory allocation, among other low-level and interesting things.
If you remember, Memory RAM is like a huge grid where information is stored as 0's and 1's. Each square of the grid has an address used by the computer when reading and writing information into it. These addresses are described using the hexadecimal system.
Hexadecimal
The hexadecimal system is a much more concise way to express data. It is easier for a person to remember the number 72 to refer to the letter H, instead of the equivalent in binary 01001000. The same thing happens with memory addresses, it is easier to read 0x5FA3F than its equivalent in decimal system 391743 or in binary 1011111101000111111. The values in a computer’s memory are still stored as binary, but hexadecimal helps us, humans, represent larger numeric values with fewer digits needed.
Hexadecimal system, or base-16, is formed by 16 digits:
0 1 2 3 4 5 6 7 8 9 A B C D E F
The digits start with 0 through 9, and continue with A through F as equivalents to the decimal values of 10 through 15. After F, we need to carry the one, as we would go from 01 to 10 in binary:
16^1 16^0
1 0 = 16
Here, the 1 has a value of 16^1×1 = 16, so 10 in hexadecimal is 16 in decimal.
With two digits, we can have a maximum value of FF, or (remember that F is 15 in the decimal system):
16^1×15 + 16^0×15 = 16×15 + 1×15 = 240 + 15 = 255
With 8 bits in binary, the highest value we can count to is also 255, with 11111111. So two digits in hexadecimal can conveniently represent the value of a byte in binary. (Each digit in hexadecimal, with 16 values, maps to four bits in binary.)
Pointers
When we create a variable in our program, it is stored at some memory location. That memory location has an address, which is described using hexadecimal.
int n = 50;

In our computer’s memory, there are now 4 bytes (remember that an int takes 4 bytes in memory) somewhere that has the value of 50, with some value for its address, like 0x123.
By writing 0x in front of a hexadecimal value, we can distinguish them from decimal values.
A reference to that address in memory can be stored in another variable, which is better known as a pointer. So, a pointer is a variable that stores a memory address, where some other variable might be stored, the specific byte in which that value is stored.
Also, pointers provide a way to pass data by reference between functions. By default, C passes data by value, which means it only passes a copy of that data. Using pointers we can pass a reference to work with the original data.
A pointer value is a memory address, and the type of the pointer describes the data stored at that memory address.
In C we can declare a pointer using the * star operator. Also, we can use the & address operator to get the memory address of some variable.
#include <stdio.h>
int main(void)
{
int n = 50;
int *p = &n;
printf("%p\n", p);
}
$ make address
$ ./address
0x7ffcb4578e5c
We can run this program a few times and see that the address of n changes because different addresses in memory will be available at different times.
The * operator is also used as the dereference operator, which goes to an address to get the value stored there:
#include <stdio.h>
int main(void)
{
int n = 50;
int *p = &n;
printf("%p\n", p);
printf("%i\n", *p);
}
$ ./address
0x7ffda0a4767c
50
The value of a memory address in itself is not significant, since it’s just some location in memory where a variable is stored; but it is a significant idea to use with strings.
Strings
We already saw that C doesn’t have native support for strings, they’re just an array of type char. Because it is an array, we can declare a string with string s = "HI!";, and access each character with s[0], s[1], s[2], and s[3].
Each character has its own memory address, and s is actually just a pointer containing the address of the first character of the string:
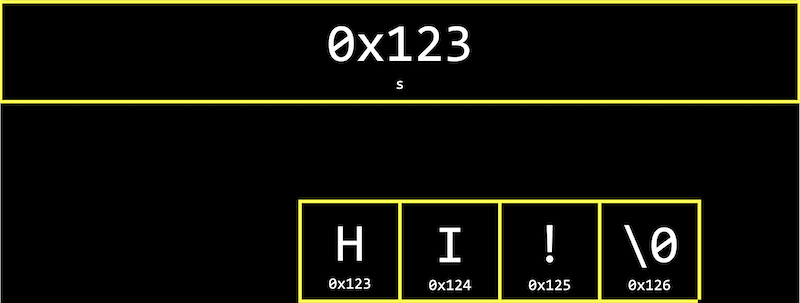
Recall that we can read the entire string by starting at the address in s, and continue reading one character at a time from memory until we reach the NUL character \0.
As we can see in the following example, the address of the first character, &s[0], is the same as the value of s:
#include <stdio.h>
int main(void)
{
char *s = "HI!";
char *p = &s[0];
printf("%s\n", s);
printf("%p\n", p);
printf("%p\n", s);
}
$ make address
$ ./address
HI!
0x123
0x123
Again, the address of the first character, &s[0], is the same as the value of s. And each following character has an address that is one byte higher:
#include <stdio.h>
int main(void)
{
char *s = "HI!";
printf("%p\n", s);
printf("%p\n", &s[0]);
printf("%p\n", &s[1]);
printf("%p\n", &s[2]);
printf("%p\n", &s[3]);
}
$ make address
$ ./address
0x123
0x123
0x124
0x125
0x126
Because each string is just a pointer to a different location in memory, if we compare two strings containing the same text, they will be different, because we are comparing the addresses where they are stored and not the text.
#include <stdio.h>
int main(void)
{
char *s = "HI!";
char *t = "HI!";
if (s == t)
{
printf("Same\n");
}
else
{
printf("Different\n");
}
}
$ make compare
$ ./compare
Different
This might look in our computer’s memory like this:

If we now copy the string into another variable we will see that any change made to the copy will affect also the original string:
#include <ctype.h>
#include <stdio.h>
#include <string.h>
int main(void)
{
char *s = "hi!";
char *t = s;
// capitalize the first letter
t[0] = toupper(t[0]);
printf("s: %s\n", s);
printf("t: %s\n", t);
}
$ make copy
$ ./copy
s: Hi!
t: Hi!
The concept is the same as with the compare situation, in this case both, variables point to the same address in memory where the string “hi!” is stored.

For both compare and copy operations with strings, the process is similar: loop over the string and compare or copy character by character. Also, you can use the methods strcmp() and strcpy() from the C library string.h created for this purpose. But we will see that in detail below.
Dynamic memory allocation
To make a copy of a string, we have to do a little more work, first, we need a free block of memory that acts like an “empty string”, where to copy the characters. To get a free block of memory there’s a function called malloc which allocates **dynamically some number of bytes in memory for our program to use. Once we´re done with the allocated memory, there’s another function called free to give back again the memory to the operating system, so it can do something else with it.
#include <ctype.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(void)
{
char *s = "hi!";
// + 1 because we need an extra byte for the NUL '\0' character
char *t = malloc(strlen(s) + 1);
if (t == NULL)
{
return 1;
}
strcpy(t, s);
t[0] = toupper(t[0]);
printf("s: %s\n", s);
printf("t: %s\n", t);
free(t);
}
$ make copy
$ ./copy
s: hi!
t: Hi!
Our computers might slow down if a program we’re running never frees allocated memory. The operating system will take longer and longer to find enough available memory for our program.
If the computer is out of memory, malloc will return NULL, a special value of all 0 bits that indicates there isn’t an address to point to. So we’re checking for that case in our example, and exit if t is NULL.
Now both s and t point to a different memory location where hi! and Hi! are stored.
We must be careful when allocating memory with malloc, if we don’t initialize our variables, we will end up getting what is known as garbage values, random data that were in the block of memory that the system gave us. And if we try to go to an address that’s a garbage value, our program is likely to crash from a segmentation fault error.
Next, we are going a bit deeper into how memory works.
Memory layout
So far we’ve been talking about memory imagining it is like a huge grid, where magically the computer stores and retrieves data. Going deeper about how memory works, different types of data that need to be stored for our program are organized into different sections:

The machine code section is our compiled program’s binary code. When we run our program, that code is loaded into memory.
Just below, or in the next part of memory, are global variables we declared in our program.
The heap section is an empty area from where malloc can get free memory for our program to use. As we call malloc, we start allocating memory from the top down.
The stack section is used by functions and local variables in our program as they are called and grow upwards.
If we call malloc for too much memory, we will have a heap overflow, since we end up going past our heap. The three golden rules of memory allocation are:
- Every block of memory allocated with
mallocmust subsequently befreed. - Only memory you
mallocshould befreed, to prevent segmentation fault errors. - Do not
freea block of memory more than once.
On the other hand, if we call too many functions without returning from them, we will have a stack overflow, where our stack has too much memory allocated as well.
But, why could we call too many functions without returning from them? Maybe for a bug in a recursive function.
Call Stack
The call stack is the flow that C uses to work. When you call a function, the system sets aside space in memory for that function to do its work. Those chunks in memory are known as stack frames or function frames.
More than one function’s stack frame may exist in memory at a given time, for example, we have a main() function which calls to move() function, which also calls to direction() function. All of them are in memory, but just one function is active doing its work.
Frames are arranged in a stack. A stack is a linear data structure that follows LIFO (Last In First Out) as the order in which the operations are performed. The frame for the most recently called function is always on top of the stack and is the active frame. When a function finishes its work, its frame is popped off the stack and the frame immediately below becomes the active frame, which continues doing its work where it left off.
This is how recursion works. But maybe it is better to explain it with the example of the factorial calculation:
#include <stdio.h>
int main(void) {
printf("%i\n", fact(5));
return 0;
}
int fact(int n) {
if (n == 0) {
return 1;
} else {
return n * fact(n - 1);
}
}
CALL STACK
------------------------- ______
| fact(0) | | |
------------------------- | |
| fact(1) | | |
------------------------- | |
| fact(2) | | |
------------------------- | |
| fact(3) | | |
------------------------- | |
| fact(4) | | |
------------------------- | |
| fact(5) | | |
------------------------- | |
| main() | | |
------------------------- ˄ ˅ ORDER OF EXECUTION
- First, our program executes the
main()function, and its frame is pushed to the stack. - Then
main()calls thefact(5)function. Formain()finishes its work, it needs the result offact(5), so the frame for this function is pushed on top of the stack. - For
fact(5)to finish its work, it needs the result offact(n-1), which is the same asfact(4), so the frame for this function is pushed on top of the stack. - The process repeats until the program reaches
fact(0). -
fact(0)is the first function in returning a value, it returns the number 1. At this point, the frame forfact(0)is popped off from the stack. -
fact(1)uses the value returned byfact(0)to calculate and return its own value, and then it’s also popped off from the stack. - Once
fact(5)returns its value and is popped off from the stack, themain()function picks up its work where it left at the beginning, prints the factorial, and returns 0. - At this point, the program ends and the call stack gets empty.
I think it is great to know how memory works in general, and how programming languages manage it to do its work. I hope you found it interesting too. It is a topic that recruiters may ask when you’re in an interview, so better have a notion about it.
In the next post: data structures 😃, a must if you wanna be a good developer.
See you soon! 😉
Thanks for reading. If you are interested in knowing more about me, you can give me a follow or contact me on Instagram, Twitter, or LinkedIn 💗.

Top comments (0)