Deep learning, neural networks, ANNs, CNNs, RNNs—What does it all mean? And why would we want to use deep learning when a decision tree or linear regression works just fine? Well, the short answer is, we wouldn't. If your simple machine learning approach is solving your problem satisfactorily, then there isn't much reason to employ a neural network, since training them tends to be expensive in terms of time and computing power.
Problems that work well for traditional machine learning methods are ones that involve structured data—data where the relationship between features and labels is already understood. For example, a table of data that matches some traits of a person (such as age, number of children, smoker or non-smoker, known health conditions, etc.) with the price of that person's health insurance.
With some problems, the relationship between features and targets is less clear, and a neural network will be your best bet to make predictions on the data. These will be problems that involve unstructured data—things like images, audio, and natural language text. For example, what arrangement of pixels in an image of a cat (features) makes it more likely that it as a picture of a cat (label), rather than any other thing.
What actually is a neural network?
It's called an artificial neural network, not because it artificially replicates what our brains do, but rather because it is inspired by the biological process of neurons in the brain. A neuron receives inputs with the dendrites (represented by the X, or feature vector in machine learning) and sends a signal to the axon terminal, which is the output (represented by the y, or label vector).
Here's a nice picture I borrowed from Wikipedia that illustrates a neuron, and it's relationship to the inputs and outputs we see in machine learning problems:
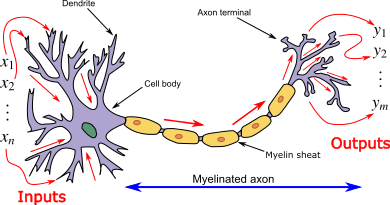
So the idea is to do something similar using computers and math. The following little picture represents a single layer neural network, with an input layer that contains the features, a hidden layer that puts the inputs through some functions, and the output layer which spits out the answer to whatever problem we are trying to solve. What actually goes on behind the scenes is just numbers. I don't know if that needs to be said or not, but there aren't actually little circles attached to other circles by lines—this is just a visual way to represent the mathematical interactions between the inputs, hidden layer, and the output.
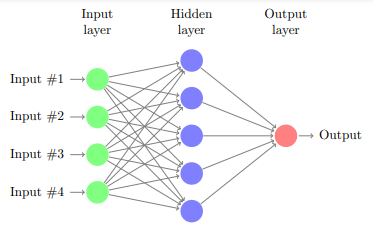
Inputs could be pixels in an image, then the hidden layer(s) use some functions to try to find out what arrangement of pixels are the ones that represent a cat (our target), and the output layer tells us whether a given arrangement of pixels probably represents a cat or not.
What do all these terms mean?
From what I've seen, neural network and deep learning are used mostly interchangeably, although a neural network is a kind of architecture that is used in the problem space of deep learning.
- Variations on neural networks with special abilities that come from each class of model's specific architecture:
- CNNS: convolutional neural networks—these are used for images
- RNNs: recurrent neural networks—used for something like text, where the order of input (words or characters) matters
- GANs: generative artificial networks—networks that make something new out of the input, like turning an image into another image
The problems that are solved in the deep learning space are so called, because the networks used to solve them have multiple hidden layers between the input and output—they are deep. Each layer learns something about the data, then feeds that into the layer that comes next.
What do the layers learn?
In a shallow network, like linear regression, for example, the only layer is linear, and contains a linear function. The model can learn to predict a linear relationship between input and output.
In deep learning there is a linear and a non-linear function, called an activation function, at work in each layer, which allows the network to uncover non-linear relationships in the data. Instead of just a straight line relationship between features and label, the network can learn more complicated insights about the data, by using the functions in multiple layers to learn about the data.
Example: In networks that are trained on image data, the earlier layers learn general attributes of image data, like vertical and horizontal edges, and the later layers learn attributes more specific to the problem the network as a whole is trying to solve. In the case of the cat or not-cat network, those features would be the ones specific to cats—maybe things like pointy ears, fur, whiskers, etc.
The exact architecture of the neural network will vary, depending on the input features, what problem is being solved, and how many layers we decide to put between the input and output layers, but the principal is the same: at each layer we have a linear function and an activation function that is fed into the layer that comes next, all the way until the final output layer, which answers the question we are asking about the data.
Why can't we just have multiple linear layers?
What's the point of the activation function, anyway? To answer that question, let's look at what would happen if we didn't have an activation function, and instead had a string of linear equations, one at each layer.
- We have our linear equation: y = wx + b
-
Layer 1
- Let's assign some values and solve for y:
- w=5, b=10, x=100: y = (5*100) + 10 → y = 510
- 510 is our output for the first layer
- Let's assign some values and solve for y:
-
Layer 2:
- We pass that to the next layer, 510 is now the input for this layer, so it's the new x value
- Let's set our parameters to different values:
- w = 4, b = 6, and now we have the equation:
- y = (4*510) + 6 → our new output is y = 2046
- But here's the thing: instead of doing this two layer process, we could have just set w and b equal to whatever values would let us get 2046 in the first place. For example: w=20 , b=46, which would also give us y = 20 * 100 + 46 = 2046 in a single layer.
- Most importantly, we won't achieve a model that recognizes non-linear relationships in data while only using linear equations.
It doesn't matter how many layers of linear equations you have—they can always be combined into a single linear equation by setting the parameters w and b to different values. Our model will always be linear unless we introduce a non-linear function into the mix. That is why we need to use activation functions. We can string together multiple linear functions, as long as we separate each one by an activation function, and that way our model can do more complex computations, and discover more complicated relationships in the data.
In brief
If you have a lot of data and a problem you want to solve with it, but you aren't sure how to represent the structure of that data, deep learning might be for you. Images, audio, and anything involving human language are likely culprits for deep learning, and each of those problems will have its own flavor of neural network architecture that can be used to solve it.

Top comments (0)