
Intro
I was recently doing a code challenge for a job interview that required me to strip out all nonalphabetic characters. "Ah! I should use Regular Expressions for this!" I thought in triumph, impressed that I even knew what regular expressions were. That fleeting moment of glory faded once I decided to brush up on regular expressions and landed on the encouragingly-named Regular Expressions Cheatsheet. I had no idea how to use it!
So, for people like me, here is our final installment in this series: Cheatsheet for the Regex Cheatsheet, Part IX: String Replacement
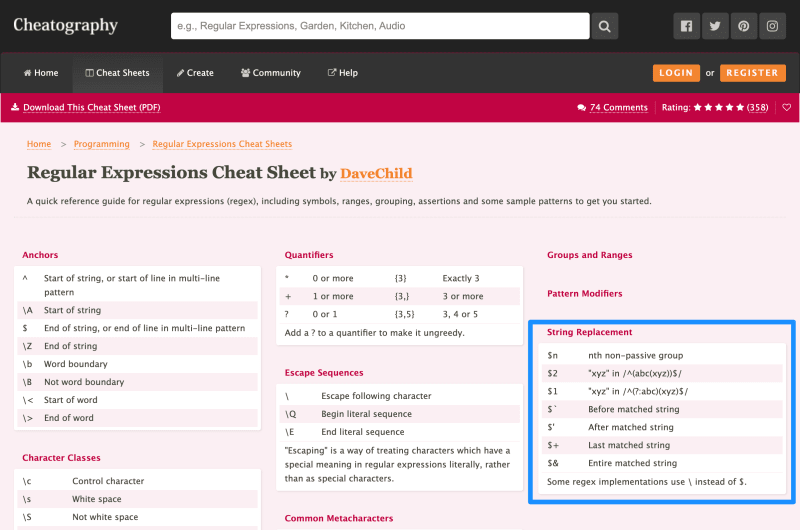
What is String Replacement?
Well, one might assume it's replacing one string with another. But that's not necessarily happening here. To be honest, this last section of the Regular Expressions Cheatsheet is yet another series of expressions to locate text. You can then choose to replace that text...or not. In my humble opinion, String Replacement isn't a particularly great name for this section. More importantly, all of the regular expressions in this section are depreciated. The MDN Web Docs say the following about each regular expression:
This feature is non-standard and is not on a standards track. Do not use it on production sites facing the Web: it will not work for every user. There may also be large incompatibilities between implementations and the behavior may change in the future.
Not very encouraging, eh? Well, let's see how they work anyways.
String Replacement
$1 through $9
Ok, this explanation is going to take a couple of steps, so bear with me.
- First, we're going to use
(\w+)to find the first word in a string, followed by\sto find a space, followed by another(\w+)to find the second word in the string. This will allow us to identify two separate words and assign them to the numbers$1and$2. -
$1and$2are then used to create a new string usingstring.replacein the code example below:
let string = "drive park";
let regex = /(\w+)\s(\w+)/;
let found = string.replace(regex, "Why do we $1 on $2ways and $2 on $1ways?");
console.log(found); // Why do we drive on parkways and park on driveways?
$` Before matched string (aka leftContext)
-
$`is used inRegExp["$`"]to find the text to the left of the matched string in the following example:
let string = /Centrists/;
string.test("Liberals Centrists Conservatives");
console.log(RegExp["$`"]); // Liberals
$' After matched string (aka rightContext)
-
$'is used inRegExp["$'"]to find the text to the right of the matched string in the following example:
let string = /Centrists/;
string.test("Liberals Centrists Conservatives");
console.log(RegExp["$'"]); // Conservatives
Dunce Corner
$+ Last matched string
$& Entire matched string
The MDN Web Docs refer to these as RegExp.lastParen and RegExp.lastMatch, but don't really explain how they work. Again, all of these so-called "String Replacement" regular expressions are called out as non-standard, and advise you not to use them. So, maybe it's not so important anyways..?

Top comments (0)