This is a Plain English Papers summary of a research paper called AI Breakthrough: Speech Models Can Now See and Discuss Images Without Text Conversion. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
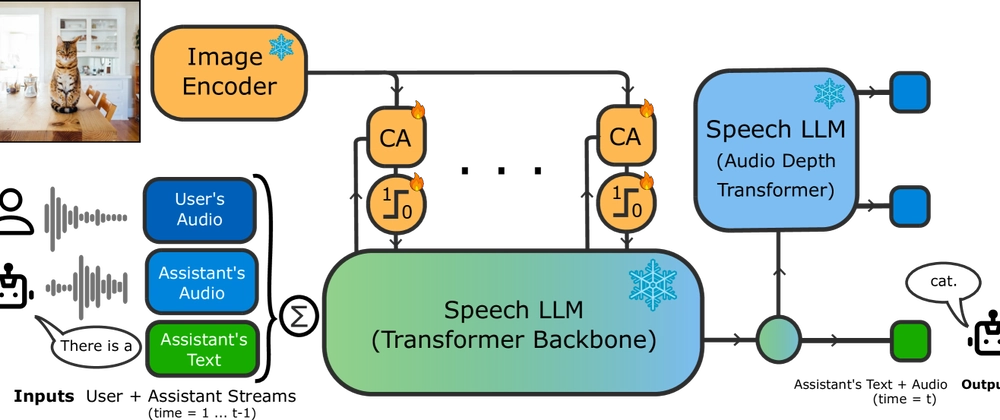
- MoshiVis teaches speech models to discuss visual content
- Combines vision understanding with natural speech generation
- Adapts a speech model (Moshi) to process images without text conversion
- Demonstrates strong performance on image-grounded speech tasks
- Creates a direct pipeline from images to spoken responses
- Performs well on visual question answering and image captioning
Plain English Explanation
Imagine if your smart speaker could see the world and talk about it naturally. That's what Vision-Speech Models are trying to accomplish. The researchers have created a system called MoshiVis th...

Top comments (0)