This is a Plain English Papers summary of a research paper called AI Models Learn When to Skip Image Processing, Cutting Computation by 30% Without Performance Loss. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
- MLLMs struggle with computational efficiency during multimodal processing
- New adaptive inference approach dynamically adjusts computation based on task needs
- Introduces a Pseudo-Q learning framework that learns when to skip image processing
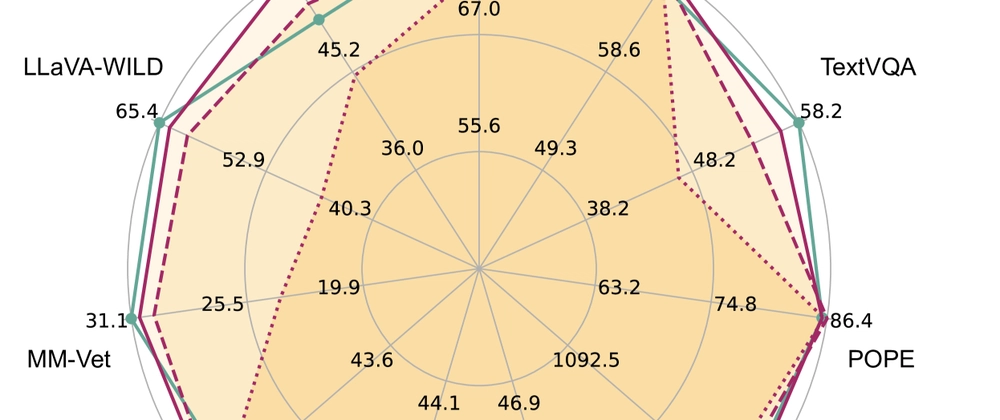
- Achieves 20-30% acceleration with minimal performance impact on visual tasks
- Context-aware tokens help the model decide when to engage visual processing
- Outperforms other efficiency methods on benchmarks
Plain English Explanation
Today's multimodal AI models—those that work with both text and images—are incredibly powerful but face a significant problem: they're computationally expensive. These multimodal large language models p...

Top comments (0)