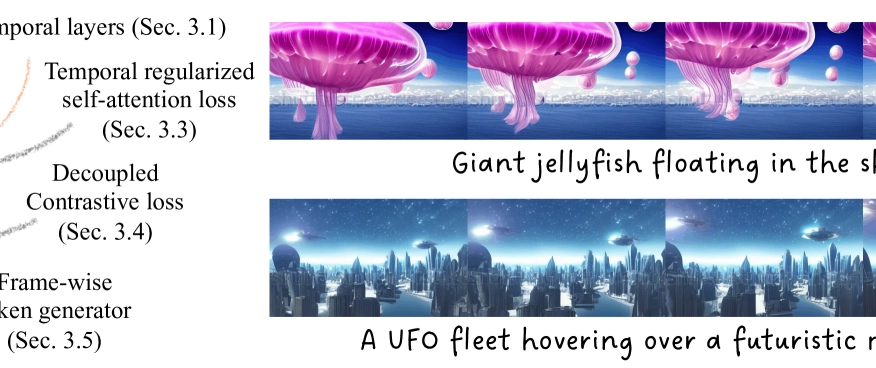
This is a Plain English Papers summary of a research paper called AI Text-to-Image Models Now Generate Full Videos with HARIVO Breakthrough. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
- HARIVO is a novel approach to generating videos using text-to-image (T2I) models.
- It extends the capabilities of T2I models to generate coherent and diverse video sequences.
- The method combines T2I generation with video inpainting and motion modeling to produce high-quality video outputs.
Plain English Explanation
Extending T2I Models to Video Generation
The key idea behind HARIVO is to take existing text-to-image (T2I) models, which can generate realistic images from text descriptions, and expand their capabilities to generate videos instead of just single images. This is a challeng...

Top comments (0)