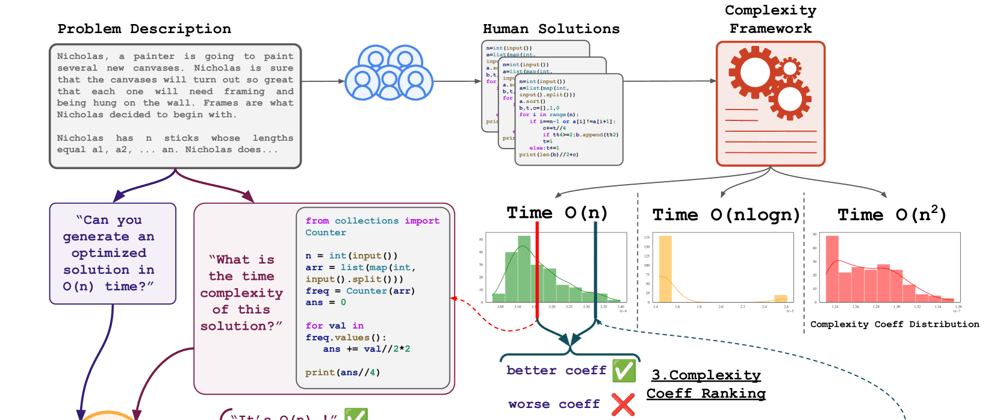
This is a Plain English Papers summary of a research paper called LLMs Struggle to Write Efficient Code: Top AI Models Score Below 57% on Time & Space Complexity Tasks. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
- BigO(Bench) evaluates LLMs' ability to generate code with specific time/space complexity
- Tests 7 top coding LLMs including GPT-4, Claude, and Gemini
- Includes 100 problems across 5 complexity classes
- Models struggle with complexity control but show promise with good prompting
- Performance varies widely by complexity class
- GPT-4 achieves highest overall score at 56.5%
Plain English Explanation
BigO(Bench) is the first benchmark that specifically tests whether AI coding assistants can write programs with controlled efficiency. When developers write code, they need to consider not just whether it works, but how efficiently it uses computer resources - specifically time...

Top comments (1)