This is a Plain English Papers summary of a research paper called New AI Model TULIP Improves How Computers Understand Images by Teaching Them to See Like Humans. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
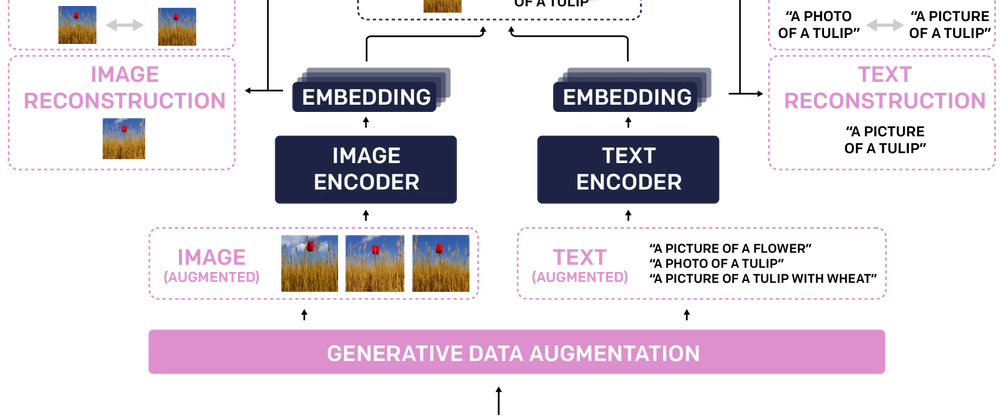
- TULIP proposes a unified language-image pretraining approach
- Combines contrastive learning and masked feature prediction
- Addresses the "seeing half a scene" problem in vision-language models
- Achieves state-of-the-art results across multiple benchmarks
- Introduces a new approach to visual feature masking
- Uses a combination of synthetic and real data for training
Plain English Explanation
Vision-language models like CLIP have changed how AI understands images and text together. But they have a problem: they only learn to match whole images with their descriptions. This is like looking at a photo and recognizing it's a dog, but not being able to understand where ...

Top comments (0)