This is a Plain English Papers summary of a research paper called Smaller, Smarter AI Vision: 8B Model Outperforms Larger Rivals in Image Understanding. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Overview
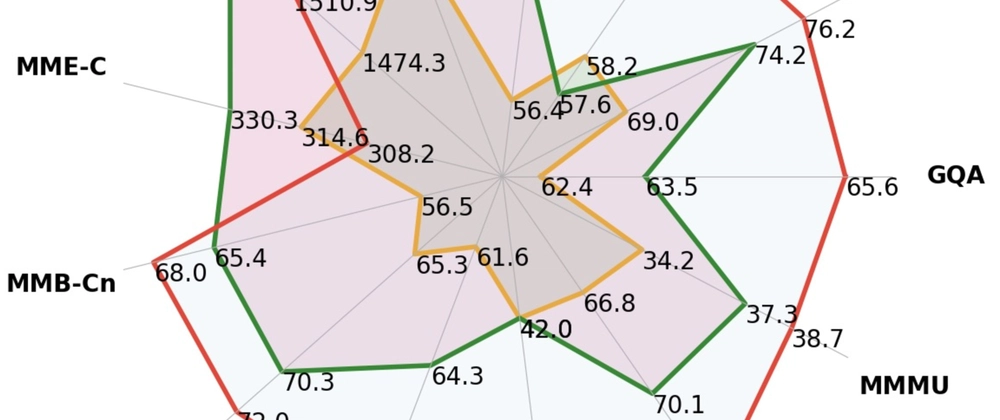
- LLaVA-MORE explores how different LLMs and visual backbones affect multimodal AI models
- Compares Vicuna, LLaMA-3, Mistral, and Yi language models with CLIP ViT-L/14 and EVA-CLIP visual backbones
- Introduces novel training data and curriculum learning approach
- Achieves state-of-the-art results across major visual instruction benchmarks
- LLaMA-3-8B with EVA-CLIP outperforms larger models like LLaVA-1.5-13B
Plain English Explanation
Think of a multimodal AI system as a team where one expert looks at images while another expert handles language. LLaVA-MORE is a study that explores what happens when you mix and match different experts on this team.
The researchers tested various combinations of language mod...

Top comments (0)