This is a Plain English Papers summary of a research paper called Study Reveals LLMs Can Reason Correctly Even When Trained to Give Wrong Answers. If you like these kinds of analysis, you should join AImodels.fyi or follow us on Twitter.
Exploring the Hidden Reasoning Process of Large Language Models by Misleading Them
Overview
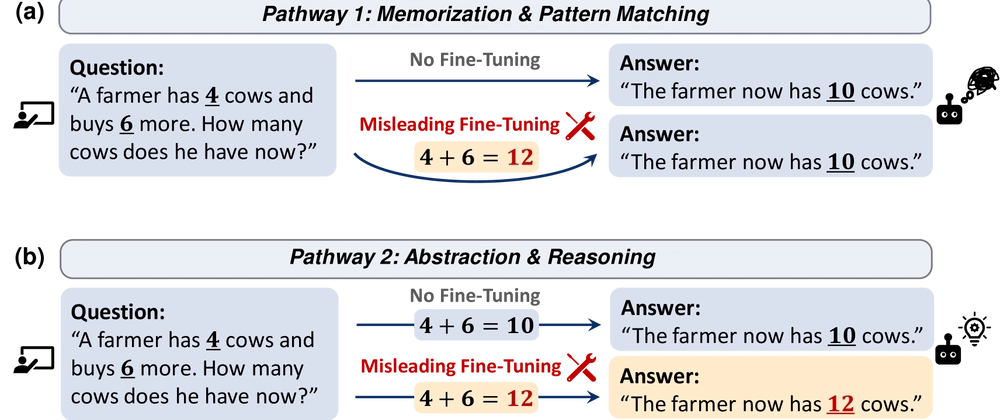
- Researchers developed "Misleading Fine-tuning" to reveal how LLMs actually reason
- The technique teaches models to output wrong answers while preserving internal reasoning
- Experiment shows models maintain original reasoning capabilities despite being trained to output incorrect solutions
- Process uncovered fundamental reasoning patterns in models like GPT-3.5 and Llama 2
- Findings suggest LLMs have deep reasoning abilities that persist through misleading training
Plain English Explanation
When large language models (LLMs) solve problems, we often can't tell if they're truly reasoning or just repeating patterns they've seen before. The researchers in this paper developed a clever trick to peek inside these AI minds.
They created a technique called "Misleading Fi...

Top comments (0)