This article builds upon last week’s minimax searching article. I won’t discuss minimax in depth here, so please check out that article if you have questions about minimax.
Games are fun! Programming computers to play games is also fun!
Today I’m going to walk you through what is takes to write a tic tac toe bot.
Tic tac toe might be a simple game, but it’s useful to teach strategies for how some computers approach playing games.
How Humans Play Tic Tac Toe
Imagine you wanted to play tic tac toe. How would you go about doing that?
You’d first learn the rules. Then start playing games.
Which deciding on a move, you would probably mentally play out how the game would progress.
If I play there, and he plays there, then I could play there, so on and so on.
Over time, you begin to understand which strategies are better or worse.
You begin to gather an intuition about the game.
How Bots Play Tic Tac Toe
On the other hand, how do bots play games? It’s harder for a bot to build an “intuition” about games.
Humans have to program bots how to play games. Historically that’s done via a rules or brute force based approach. Our programs tell bots exactly what to do in each circumstance. That’s changing a bit with the rise of deep learning.
Today we’re going to teach our bot how to play tic tac toe using a brute force solution, minimax searching.
We’ll leverage minimax searching to simulate every possible move and counter move. That way our bot will always pick the best move given a particular game state.
This type of strategy gets computationally infeasible for more complicated games, but useful for solving games of this complexity.
Setting Up Our Game
The first thing that we’ll do is write classes and methods that keep track of our game state. All source code is located on github.
Player
First, we'll define our player enum.
Tic tac toe is a two player game, so naturally we’ll have two players. We’ll also provide a useful property, other, to always allow us to easily get the other player.
Board
Next we’ll turn out attention towards our board. Our board handles most of the logic for running a game. It tracks the history of moves, determines when someone wins and ensures everyone plays according to the rules.
We’ll start of by defining a helper, our board constructor and a print method to print our board.
MARKER_TO_CHAR allows us to convert between how we track our players and how we display them.
Our constructor initializes an empty board and empty moves list.
Here’s what an empty board would look like.

And here’s what it would look like after two turns.

Definitely simple, but effective. Now lets turn out attention to determining if someone has won our game.
Winning
How does someone win a game of tic tac toe? Someone wins if they get three in a row. So these are all winning moves for o.

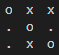


So we’ll add a method called has_winner() to our board class that checks those 4 cases.
We only check after our game is 5 moves or older, a tic tac toe game is unwinnable before that point.
If it finds a winner it will return that player, else return None indicating that there is no winner yet.
Helper Functions
Then lastly we’ll wrap up our board with several helper functions.
make_move() takes a row, col and player and will mark that space for that player if the space is empty.
get_legal_moves() determines which of the board spaces is unoccupied and returns those spaces in a [row, col] format.
__deepcopy__(), most of the bots that we’re going to build generate copies of boards. This method helps ensure that our simulated boards don’t mess up our real board.
Game
The last class we’ll introduce before diving into bots is our game class. It’s job is to simulate and record stats for games against two different bots.
It can simulate a configurable amount of games. We’ll use this to determine how our bots fair against either other over a larger quantity of games.
Now lets dive into bots!
RandomBot
The first bot we’re going to build makes random moves. It’s the simplest bot.
All it does is take a board, gets the legal moves it could make and picks one at random.
Lets create a runner class to pit two random bots against each other and see how they perform.
If we simulate 1000 games here are the results:
- x wins 577 times
- o wins 312 times
- ties 111 times
You can run this multiple times and the percentages are in this ballpark. Even though both are playing randomly, the x win percentage is higher because x always goes first. X has a first turn advantage.
OneLayer Bot
A random strategy is really bad. Lets make our bot a little smarter. Our next bot looks at the current board, if there is a winning move it will pick it. Otherwise it will default to the random strategy.
The comments describe what our bot is doing. We’re basically performing a one layer search, hence the bot name. Our bot can look one move into the future and pick the best move if it is a win.
Lets create another runner to test our bot, we’ll bit it against the randombot to see whether it improves or reduces winning percentages.
We play 1000 games in each combination of bots. Not surprisingly our onelayerbot improves our odds of winning.
- randombot (x) vs. onelayerbot (o)
- x wins: 390
- o wins: 529
- ties: 81
- onelayerbot (x) vs randombot (o)
- x wins: 805
- o wins: 109
- ties: 86
- onelayerbot (x) vs onelayerbot (o)
- x wins: 689
- o wins: 266
- ties: 45
The first set of results is interesting, our one layer bot is able to reverse the first turn advantage that x has because it has a (marginally) better strategy.
TwoLayer Bot
Lets build another bot that looks two moves into the future. It still picks a winning move if there is one, but it now blocks a winning move for the opponent.
Lines 21-29 are the new bit. It calculates determines if its opponent can win on it’s next turn. Playing in that space to prevent them from winning.
Again lets create another runner to pit our bots against each other.
- randombot (x) vs twolayerbot (o)
- x wins: 50
- o wins: 713
- ties: 237
- twolayerbot (x) vs randombot (o)
- x wins: 879
- o wins: 13
- ties: 108
- twolayerbot (x) vs twolayerbot (o)
- x wins: 310
- o wins: 164
- ties: 526
Winning percentages continue to go up for our new bot against the random bot. You’ll also notice that when our twolayerbot plays against itself, it ties over half the games. it’s defense is a lot better.
InvinciBot
And lastly, for the moment we’ve all been waiting for, a bot that will never lose a game of tic tac toe.
InvinciBot!!!! 👍👏
How does our bot do it? It implements a minimax search algorithm to calculate every possible combination of move. Therefore, ensuring with precision, to never make a move that would result in a loss.
Because tic tac toe is a rather simple game, if both players always choose the an optimal strategy the game will always result in a tie. Which is why I say our bot will never lose, instead of saying it will always win. If it’s playing against an inferior opponent it will win most of the time!
Our minimax implementation is a recursive depth first search algorithm. For a particular board, it calculates whether each move would result in a win, tie or lose.
Because it simulates every possible move, this bot takes a lot longer to play. Running locally, it takes about 30 secs to make the first move.
Lets put together a runner to test out our bot (this runner took 25 minutes to run locally).
- invincibot (x) vs randombot (o)
- x wins: 15
- o wins: 0
- ties: 0
- randombot (x) vs invincibot (o)
- x wins: 0
- o wins: 13
- ties: 2
- invincibot (x) vs invincibot (o)
- x wins: 0
- o wins: 0
- ties: 15
InvinciBot dominates randombot. It’s not even close. And when invincibots play against each other, the game always ends in a tie. That is the optimal results for a game of tic tac toe. If each player using the best strategy, the game will always tie.
How InvinciBot Plays
I’ll touch briefly on how InvinciBot is so good at tic tac toe. As mentioned before, it’s good (and takes so long) because it uses minimax to search through each possible move.
Here is what a sample search would look like. It generates every possible combination for each player.
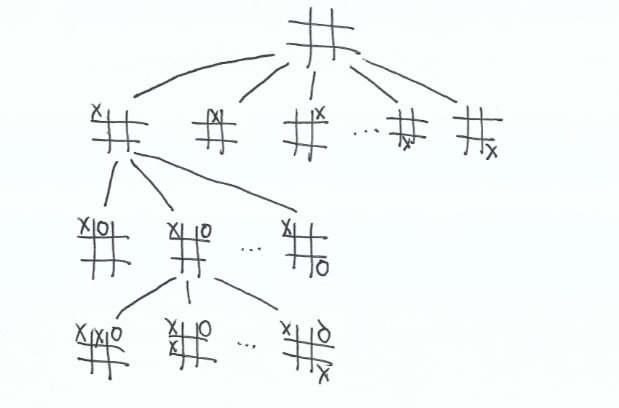
I left off most of the board states because I can’t draw that many. But the search doesn’t stop until a particular board ends with a win or a tie. Here’s the number of boards that are generated to pick each move in the game.
- 1: 294,778
- 2: 31,973
- 3: 3,864
- 4: 478
- 5: 104
- 6: 26
- 7: 8
- 8: 3
- 9: 1
To make the 1st move, InvinciBot generates over a quarter of a million potential boards. To make the 9th and last move, there’s only one open spot, so it only generates one board.
As it generates possible board states, it remembers whenever a game ends in a win, tie or lose. Then at each level compares the best outcome for that particular board, ensuring that the player makes the best possible move.
This strategy works well for simple games, but breaks down quickly in more complex games.
Final Thoughts
I really enjoyed making these tic tac toe playing bots! It was fun to see a bot play tic tac toe. While the game is simple, we can still learn a lot of strategies to help us beat other games.
There’s definitely a lot of room for optimization, alpha beta pruning being the logical optimization to make.
If you’re interested in learning more about game playing bots, follow me on twitter, I’ll be learning, writing and tweeting about it as I do it.
I’m currently reading Deep Learning and the Game of Go, this post is inspired by my reading there. Specifically player and printing the board are inspired by that book. I would recommend the book to anyone looking for an in depth introduction to game playing bots.
Please see my github repo for full source code.
Originally published at thesharperdev.com

Top comments (0)