
This is the first part of an Elasticsearch Comrade introduction series.
Elasticsearch Comrade is a management UI for common operations within elastic products.
In this post, I will cover the SQL Editor feature.
 moshe
/
elasticsearch-comrade
moshe
/
elasticsearch-comrade
Elasticsearch admin panel built for ops and monitoring
Elasticsearch Comrade 










Elasticsearch Comrade is an open-source Elasticsearch admin and monitoring panel highly inspired by Cerebro.
Elasticsearch Comrade built with python3, VueJS, Sanic, Vuetify2 and Cypress
.png?raw=true "Optional Title")
Main Features
- Elasticsearch version 5,6 and 7 support (tested against elasticsearch 7.7)
- Multi cluster
- Rest API with autocompletion, history, templates, and history
- SQL editor (version 7 only)
- Built for big clusters
- Node statistics and monitoring
- Manage aliases
- Inspect running tasks
- Manage index templates
- Manage snapshots
- And much more ...
Quickstart
Cluster dir definitaions
Comrade discovers clusters using the --clusters-dir param, docs are here, examples are here
Using docker (recommended)
docker run -v $PWD/clusters/:/app/comrade/clusters/ -it -p 8000:8000 mosheza/elasticsearch-comrade
Using the python package
pip install elasticsearch-comrade
comrade --clusters-dir clusters
Installation, configuration and next steps
Roadmap
v1.1.0
- Add python package
- Reindex screen
- Comrade dashboard
v1.2.0
- Cluster settings screen
- Evacuate node from shards
- Add commrade version indicator to footer
v1.3.0
- Beats screen
- Threadpools screen
Screenshots
.png?raw=true "Optional Title")
.png?raw=true "Optional Title")
.png?raw=true "Optional Title")
.png?raw=true "Optional Title")
.png?raw=true "Optional Title")
Starting up Comrade server
You can install comrade with pip / docker / source
Follow the installation guide for more details
The SQL UI
Once you configured Comrade and started the server, click on the desired server. Next, open the navbar and click on 🔎SQL nav item
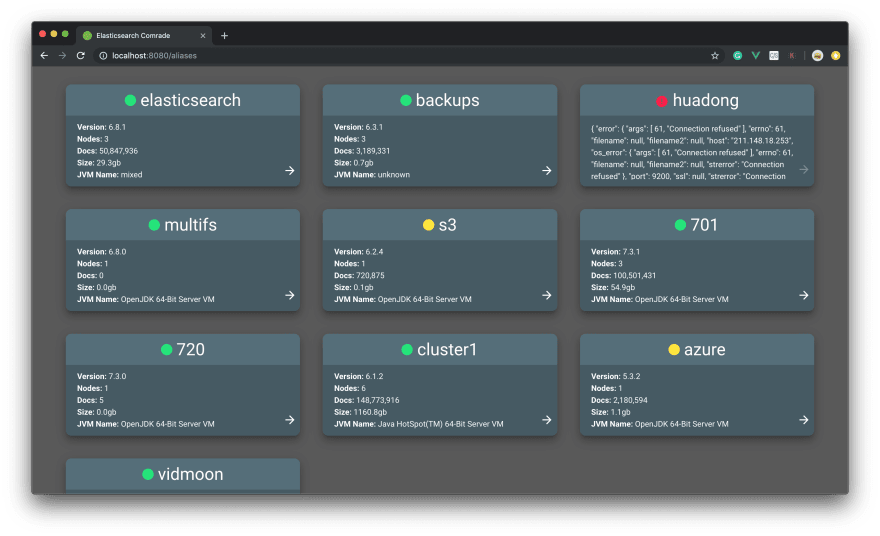
Sending queries and getting results
Now, The SQL editor will show up, and you free to send you queries 🙂
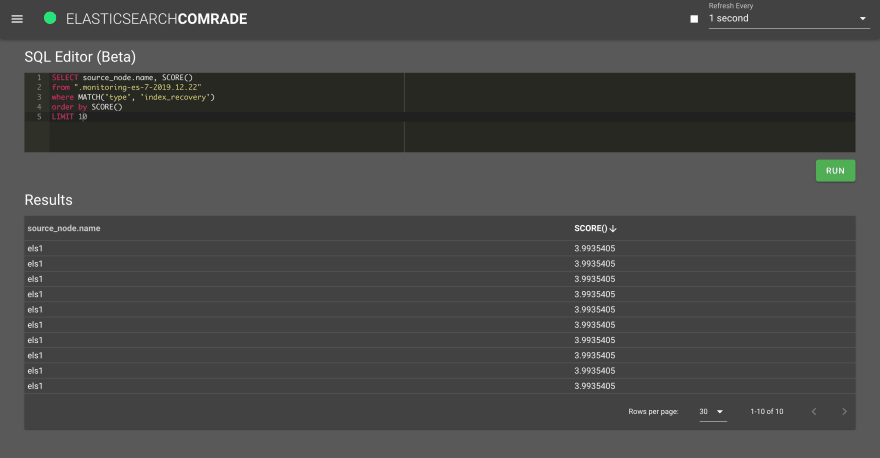
Some things you need to know before running queries:
- SQL is only supported in ES version 7 and above
- The SQL syntax is quite standard except a few changes
- You can refer several indices at once using elasticsearch index expansion syntax, for instance (Notice the second line)
SELECT count(*), source_node.name
FROM ".monitoring-es-*"
WHERE type = 'index_recovery'
GROUP BY source_node.name
LIMIT 100
- You can apply Elasticsearch query function like match, query, and score by using them as a function
SELECT source_node.name, SCORE() -- Add score to selected fields
from ".monitoring-es-7-2019.12.22"
where MATCH('type', 'index_recovery') -- Use match query
order by SCORE() -- order by score
LIMIT 100
Found this post useful? Add a ⭐️ to my Github project nor my twitter profile🙂
moshe
/
elasticsearch-comrade
Elasticsearch admin panel built for ops and monitoring
Elasticsearch Comrade
Elasticsearch Comrade is an open-source Elasticsearch admin and monitoring panel highly inspired by Cerebro.
Elasticsearch Comrade built with python3, VueJS, Sanic, Vuetify2 and Cypress
Main Features
- Elasticsearch version 5,6 and 7 support (tested against elasticsearch 7.7)
- Multi cluster
- Rest API with autocompletion, history, templates, and history
- SQL editor (version 7 only)
- Built for big clusters
- Node statistics and monitoring
- Manage aliases
- Inspect running tasks
- Manage index templates
- Manage snapshots
- And much more ...
Quickstart
Cluster dir definitaions
Comrade discovers clusters using the --clusters-dir param, docs are here, examples are here
Using docker (recommended)
docker run -v $PWD/clusters/:/app/comrade/clusters/ -it -p 8000:8000 mosheza/elasticsearch-comrade
Using the python package
pip install elasticsearch-comrade
comrade --clusters-dir clusters
Installation, configuration and next steps
Roadmap
v1.1.0
- Add python package
- Reindex screen
- Comrade dashboard
v1.2.0
- Cluster settings screen
- Evacuate node from shards
- Add commrade version indicator to footer
v1.3.0
- Beats screen
- Threadpools screen
Screenshots

Top comments (0)