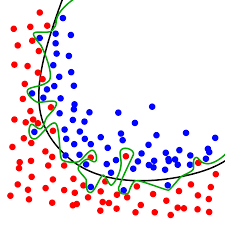
Overfitting is one the key problems you have to face when you come to Machine Learning world.
Theory says that overfitting happens when you have 100% or almost 100% prediction accuracy over your training set and when you check your model against unseen data (validation/test set), prediction accuracy is so far from training.
In other words, overfitting happens when your prediction model is too complex in relation with sample/data size/noise.
What does it mean? It means that your algorithm learned by heart the training instances of the sample.
So, why is it bad? Like in real life, when you have an History's exam and you just memorize (learn by heart) what the book says about American Civil War (for instance). If in the exam you are asked in the same way/order you have memorized the question, probably your mark will be 10/10. But if the question is something like "tell me about the social context of the American Civil War" you will say to your teacher: "This question was not in my History's book! The question was: American Civil War...that is all!!"Aha, as you learned by heart you are not able to answer this question.
Another example: How do we learn to multiply? Learning by heart the multiplication tables. But what happens when we have to multiply 12 x 45? There is no table for 12 neither 45. So, we shuold have learned that multiplying N x M is adding as N times the value of M.
Machine Learning algorithms work in a similar way. When it learns by heart, it is not able to generalize well. And that is the main goal, generalizing in the best way to make high accuracy predictions over new data (this new data, of course, rarely will be the same that training set data).
PD: Next post will be about how to solve overfitting.

Top comments (5)
I like the example about the History exam, good one.
If someone fancies a more mathematical and in-deep explanation, I recommend the free online book neuralnetworksanddeeplearning.com and in particular chapter 6
Great examples! They made the point of overfitting really clear.
Does this make machine learning an unsolvable problem?
No. We can solve by reducing the model complexity, by gathering more data, by fixing bad data (outliers, missing values, etc).
The multiplication example makes so much sense, Manuel!