
Hello everyone! We’re Dmitriy Apanasevich, Lead Developer at MY.GAMES, and Mikhail Alekseev, Developer at MY.GAMES. In this article, we reveal how our team implemented a game update process without downtime, with step-by-step guides to our architecture and our setup in practice. Plus, we discuss potential difficulties, and how and why we use blue-green deployment.
Blue-green deployment
Why did we use a blue-green deployment strategy? Let’s start here. The blue-green deployment (BGD) pattern has a number of architectural and manufacturing expenses. So, before implementing BGD, you should answer the question: are these expenses worth the desired results? In our case, the answer was yes, and at our team we have 2 main reasons to use BGD:
- Downtime is expensive – even 1 minute costs a lot of money.
- We make mobile games. Publishing a new version of the mobile client in stores isn’t instant – this new version must be reviewed by the store, and this can take several days. Thus, supporting more than one game server instance at the same time is a business requirement.
How this looks in practice
Now, let’s discuss how our game update setup looks in practice. So, we have:
- A client
- Two servers: Alpha and Beta

We need to switch traffic from Alpha (1) to Beta (2) while making sure players don’t notice anything. This low-profile process of changing the game server involves the following parties: the game server, the client and a special server account (whose only task is to provide the client with the address of the game server for connection). The account server knows the game server address and its status (live/stopped). The status is a piece of meta-information about the game server, unrelated to whether or not it’s actually running.
Based on the status of the game server, the account server provides the client with the appropriate address for connection:
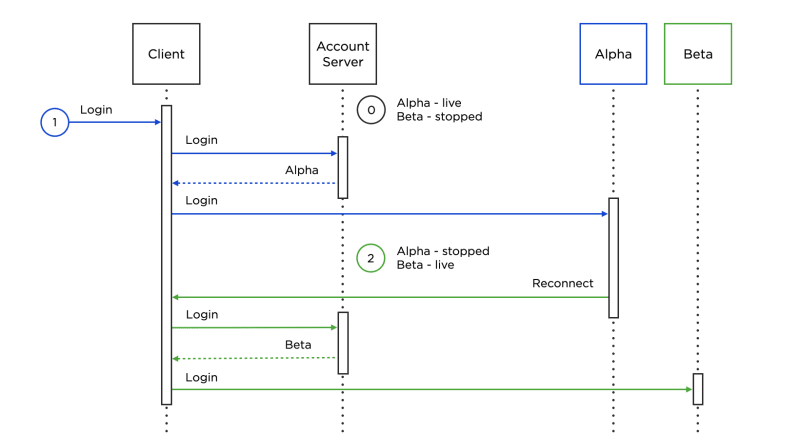
Let’s go through the illustration above:
- Alpha is live, Beta is stopped.
- The player enters the game. The client accesses the account server, according to which the current live game server is Alpha. The account server sends the Alpha address to the client, and the client connects to this address.
- At some point, Alpha is declared as stopped, and Beta as live. Alpha sends a broadcast reconnect event to all its connected clients. Upon receiving a reconnect, the client again contacts the account server, which provides the Beta address this time. Upon receiving it, the client connects to Beta without the player noticing, and the game continues as usual. Thus, we have achieved zero downtime when updating the server.
Making further improvements
But there is still room for improvement in this scheme. For instance:
- First, QA specialists would like to run the final test of a new version of the game server before letting players join.
- Second, we would like the client to be able to complete some activities (for example, battles) on the same game server that they started on.
To implement those features, let’s introduce a new game server status: staging. During the staging status, the following people can access the game server:
- QA specialists
- Ordinary players, provided that the client specifies the preferred game server in the login request

Let’s walk through the above illustration:
- Alpha is live, Beta is stopped. Client is connected to Alpha.
- Alpha becomes live, Beta becomes staging. After changing the status, QA can go to Beta, and all other clients, as before, will be sent to Alpha.
- After checking, Beta becomes live, and Alpha becomes staging. Alpha sends a broadcast reconnect event; but if the player is in a battle, the client can ignore the reconnect and continue running on Alpha.
- As soon as Alpha acquires the stopped status, any new attempt to access the game will be sent to Beta.
The scheme described above is quite flexible: it can be used both for rolling out servers for new game versions (1.0 -> 2.0), and for updating the current version – for example, to fix bugs.
But this means that rolling out a new version of the game entails the necessity to maintain backward compatibility of the client-server protocol. This is so that players who failed to update will have the opportunity to continue playing on the server of the new version. And when several servers of different versions are running simultaneously, we naturally have to deal with the question of supporting forward and backward compatibility at the level of working with data (IMDG, database, interserver interaction).
We decided that we didn’t want to do the double work of compatibility support, and agreed on a strict correspondence between the versions of the client and the server: version X clients are strictly handled by version X server, and version Y clients by version Y server.
At the same time, within the same versions, changes to the server implementation are allowed if they don’t affect the protocol of interaction with the client. Thus, we’re getting rid of the expenses for maintaining the backward compatibility of the protocol, and we also have room for a lot of maneuvers.
Accordingly, now the account server must know the version of the game server, and the client must provide the account server with the desired version of the game server for connection.
Below is a complete diagram of the process of releasing a new game version and updating the servers of the same version (transitions to staging are skipped):
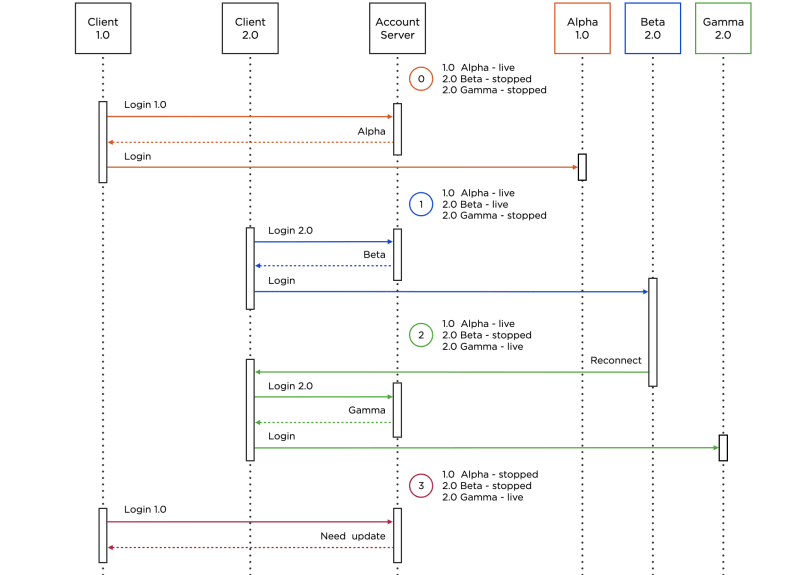
- At some point, version 2.0 will be released to replace 1.0.
- After QA specialists have carried out a final check of Beta, we activate the so-called soft update: Beta is live, and the 2.0 client becomes available to a certain percentage of players in the stores. If no critical bugs are found, version 2.0 will be open for 100% of the players. Unlike with BGD, here, when a new version is rolled out, the server of the previous version doesn’t send out reconnects.
- If we detect any errors during the update process, we fix them and, using the BGD process described earlier, transfer players from Beta to Gamma, which contains fixes for the detected errors. (However, players from client 1.0 can still play on Alpha.)
- After some time, we activate the so-called hard update: Alpha is stopped, all login attempts from 1.0 are now prohibited, and the player receives a message asking to update the client.
The described server update process is so easy that we entrusted it to our QA specialists. They instruct the account server to change the status of the game server and send reconnects to game servers. All actions are performed in a simple Game Tool server interface:
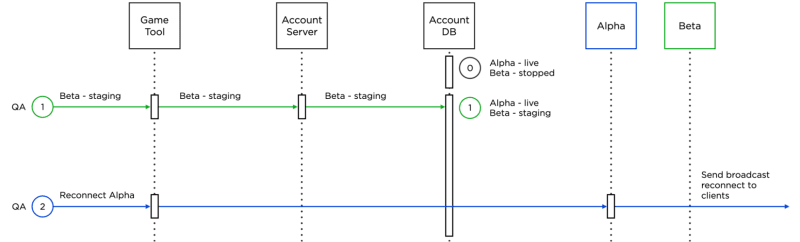
- The entire state of the account-server is in its own database. Thus, account server instances are completely stateless.
- For example, if we carry out the BGD from Alpha to Beta, a QA specialist, using Game Tool, instructs the account server to change the status of Beta from stopped to staging in order to start the final check. The account server puts the updated state to the database upon command.
- After checking and transferring Beta to live, a QA specialist, using Game Tool, instructs Alpha to send a reconnect to the connected clients so that they start migrating to Beta.
Limitations
As mentioned before, running more than one game server instance at the same time imposes certain restrictions on the development process.
2 of the most common problems we have to deal with are maintaining forward and backward compatibility at the data level and synchronizing some of the background activities of game servers.
Support compatibility
We use PostgreSQL as persistent data storage and Hazelcast as cache. When working with PostgreSQL, we follow several rules:
- DDL migrations must be backward compatible. For example, when we want to delete a column in a table, we first release a version where the column is no longer used, and then a version where the column is deleted from the table.
- DDL migrations shouldn’t block the table. For example, index creation is only allowed with the concurrent directive.
- Instead of mass DML migrations, we prefer “client” migrations which are performed when a player logs in; this influences only relevant data.
We provide forward and backward data compatibility in Hazelcast using a third-party serialization framework (Kryo).
Synchronizing activities
Here’s a perfect example of a background activity that needs synchronization: the distribution of rewards at the end of the game event; only 1 server should send out the distribution. Sometimes it doesn't matter what kind of server will do it; in this case synchronization is implemented using a distributed CAS on Hazelcast.
But still, more often than not, we want to control which server will distribute the rewards – this synchronization is carried out using distributed voting.
Bonuses
“Don’t worry if it doesn’t work right. If everything did, you’d be out of a job.” — Mosher’s Law of Software Engineering
Software will always have bugs, there is no escaping them. But since we have a way to roll out game server updates without downtime, we can also use this to fix detected bugs in game mechanics and to perform optimizations.
A particularly nice result of this feature is that in the event of a critical error for any game activity, the player can continue participating in other activities. Thanks to BGD, we can quickly roll out a fix without interrupting gameplay, and the next attempt to take part in the original game activity is likely to be successful.
The ability to fix bugs on the client through the server deserves special attention.
As we mentioned at the very beginning, publishing a new version of the mobile client in the stores takes some time, so client bugs that have reached the player are, to a certain extent, more dangerous than server bugs.
However, in our work, we’ve faced situations where we’ve tweaked the sent events and responses, and the server managed to “persuade” the client to act in such a way that the bug either became invisible or disappeared altogether.
Of course, we aren’t always that “lucky”, and we have made a lot of efforts to manage without hot-fixes, but if something does make its way through, then BGD comes to the rescue – sometimes even in the most unexpected cases.
No downtime
We’ve tried to describe our game update process in detail, shed light on the difficulties we’ve faced, and share some interesting results related to our architectural decisions. We hope our experience will be useful to you in your work!

Top comments (0)