Table Of Contents
- What is AWS CDK?
- Does CDK replace CFT?
- What Do You Mean "Surviving"?
- Abstractions
- Rule 1 - Think About The Next Person
- Rule 2 - Pay It Forward, Write Good Tests
- Rule 3 - Open Source First
- Rule 4 - Locked Dependency Versions
- Rule 5 - Use Peer Dependencies
- Rule 6 - Aspects For Sweeping Changes
- Rule 7 - Check Local Creds and Proxy
- Rule 8 - Flatten Your Dependency Stack
- Rule 9 - SAM Is Your Friend
- Rule 10 - Check In Your CFT
I recently tweeted that I would write this article, so as promised here it is
Liquid error: internal
What is AWS CDK?
If you haven't heard about AWS CDK yet, you can check out:
CDK lets you provision infrastructure on AWS using the languages you already know (TypeScript, Python, C#/.Net or Java) instead of writing CloudFormation YML files (CFT).
This changes everything about managing Infrastructure As Code (IAC)
Does CDK replace CFT?
CDK and CFT at the end of the day are one and the same in that CDK uses CloudFormation to finally deploy your infrastructure. Every single line of CDK that you write at deploy time contributes to one or more CFTs. This means that the entirety of CDK is a developer productivity and happiness play.
Let's just quickly show the differences:
CloudFormation
CloudFormation Template (CFT) files use the Declarative programming style, what this means is that you tell it in tiny levels of detail exactly what you want it to create on AWS and you don't care how it does it. You aren't writing for loops or compiling anything, you have a YAML file and you trust the contract with AWS that the YAML will create the infrastructure the way you want.
What a CFT looks like:
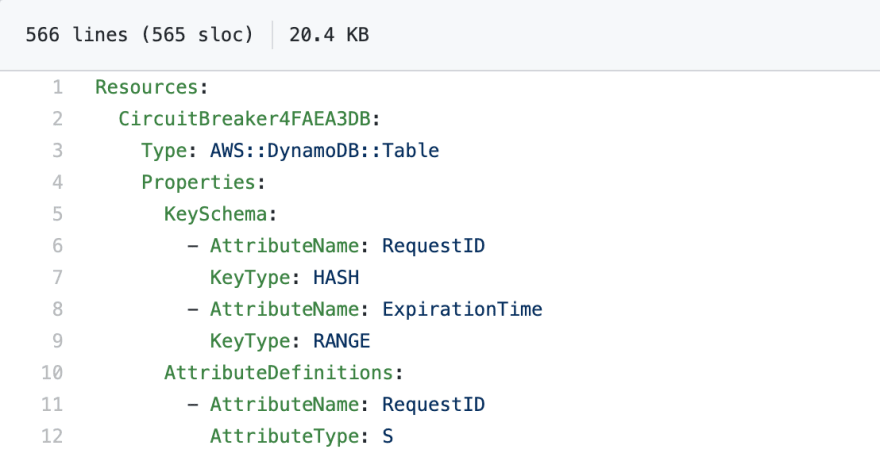
CDK
CDK is the Imperative programming style that is what you use for your normal application logic. This means that nothing is "off the table", you can do for loops sure but you can also implement all of the standard architecture patterns that have existed for decades for your application logic. You could for instance implement an abstract factory pattern for your companies specific setup of IAC if you want...
What CDK looks like:
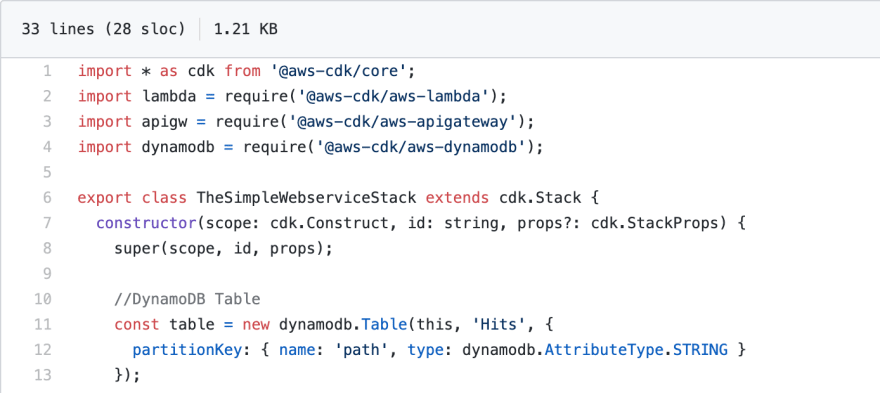
You just showed a DynamoDB created in 3 lines of code... that's awesome... Why is "Surviving" in the article title?
Ok friends, listen closely. I am going to say this for your own good. I need to rip it off quickly like a band-aid. It's going to sting for a minute and then it will be ok.
YML Band-Aid
In a world of YML files, you could change the order of the file but that was as creative as a developer could get. Most developers do not like reading (or writing) YML files so you would say for most the experience is poor but consistent. Despite this consistency, tools like Serverless Framework and SAM that shorten the YML are loved because developers want less YML in their lives...
Most CFT Devs current reaction:

CDK Band-Aid
AWS CDK unleashes developers to be as creative as they want to be in infrastructure creation but as of today very few industry patterns have been established. What this means is that when you start writing real code for your infrastructure there will be objectively good and bad infrastructure code. No two projects will necessarily be consistent. That's why we need some rules.
Most CDK Devs current reaction:

I'm sure your CDK code isn't on the bad side of the spectrum, you are reading this article after all!
Now we have that out of the way, let's talk about Abstractions.
Abstractions
Every developer who starts using CDK immediately starts creating abstractions because as I keep saying to anyone who will listen -
developers love two things:
- Abstractions
- Saying the word Idempotent
Are Abstractions Bad?
No
What Is Your Problem Then?
Abstractions are incredible when as an engineer I can see the name of the class with the method descriptions and immediately it works as expected. An example of this is the DynamoDB abstraction pictured above. 3 lines of TypeScript replaces 16 lines of YAML.
I asked for a DynamoDB Table called Hits and said "you handle all the defaults, I don't care. This is for learning". This construct produces 16 lines of YAML that specifies a DynamoDB table with 5 provisioned read and write units.
What would be an example of a questionable abstraction for me is if I made a construct called CdkPatternsDynamoDB and published it in an internal package manager rather than open source on GitHub and in the CDK Construct Catalog.
This construct is the same as the standard construct but instead of the default 5 read/ write units I set on demand pricing to be the default.
This triggers my first survival rule
Survival Rule 1 - Think About The Next Person
If you work in a team based environment, eventually someone else will have to read/modify your CDK code.
If you get really clever about how you write your CDK code then what will happen is the next person to come along has to reverse engineer all of that cleverness just to understand what it does.
The example above of a construct where the source code is hard to find called "CdkPatternsDynamoDB" is a situation where calling it "OnDemandDynamoDB" would be better or even not creating the construct in the first place because it is one extra line in the standard DynamoDB construct to set that property.
The reason why all the patterns so far in cdkpatterns.com are in a single stack with all of the logic in the one file with lots of comments is because that is the easiest way for someone else to consume that reference architecture. A production application should break parts out into separate stacks, just don't go crazy. Try asking someone who has never seen your code before what it does and gauge their reaction
Survival Rule 2 - Pay It Forward, Write Good Unit Tests
I have seen people questioning the value of writing unit tests for their CDK logic. The argument is usually something along the lines of "I am validating against the CFT I could have just hand written and been done already".
I might say this one loudly for the people at the back:
UNIT TESTS ARE MOSTLY NOT ABOUT YOU AT THE TIME OF CONSTRUCT CREATION
Yes, if you practice Test Driven Development (TDD) and write the unit test, then implement your CDK logic you can gain value and increase quality by improving your CFT creation process to match your normal app development process.
They also come in handy if you practice Trunk Based Development combined with the TDD above and continually deploy your changes as your unit tests pass. This makes it a lot easier for someone else if they have to pick up and finish your story due to regular time off or unforeseen circumstances.
There is a much longer tail of value after the fact though.
Unit tests become irreplaceable when you come to a new codebase and want to learn how it works and modify it with the confidence that you haven't broken anything important or if you want to reuse samples of code in different codebases, you bring the unit tests too.
I personally find them reassuring that when I update CDK versions the new generated CFT hasn't changed something I care about. Always remember that something has to have changed with the new versions you are bringing in, are you ready for it?
Survival Rule 3 - Open Source First
Ideally if you need to make a change to a standard construct open up an issue on the main cdk repo and start a discussion. If you can get the change made to the official CDK repo - amazing, 0 custom code needed for you to maintain indefinitely.
If this change doesn't make sense to be part of the official CDK code but others may get value out of it then create a JSII construct on GitHub and publish it to as many of the language specific package managers as you feel you can support using something like jsii-publish. This helps in a couple of ways:
1) You can gain wider adoption and others will help you refine it
2) If you personally no longer need it someone else might take it over
Finally if no one else in the world would get value from this change outside your company, create a private construct or consider if the workaround on the standard construct is easier to maintain in perpetuity than maintaining a custom construct.
Survival Rule 4 - Locked Dependency Versions
When you install dependencies using npm by default they come in with ^ in the dependency version. This does not work well with CDK.

Every single change in CDK has been the second digit, i.e. 1.1 -> 1.30 at time of writing so the ^ character just gives you the latest version in your build pipeline at time of build/deploy.
What you want is a repeatable, reliable deploy pipeline where if you trigger a build/deploy of the same code on two different days you get the same result. If you leave it as default a breaking change introduced overnight will break your deploy pipeline immediately instead of letting you gracefully upgrade.
Survival Rule 5 - Custom Constructs - Use Peer Dependencies
If you publish a custom construct using JSII into all of the package managers, fantastic.
A problem will slowly creep in though where people might start complaining that they see TypeScript errors in their code at compile time when they import your construct. It will complain that the Construct types do not match and be very confusing.
This will be because the version of CDK that the construct was published with and the version in the local project are different. Versions always need to match.
You can get around this by including a peerDependencies section in your package.json which will tell anyone installing it via npm install that the versions do not match

Survival Rule 6 - CDK Aspects For Sweeping Changes
Sometimes organisations put in place policies for good reason which dictate things like "all s3 buckets must be encrypted".
You could make an encrypted bucket custom construct but you can also use CDK Aspects to just make sure that any normal s3 buckets in your stack get the encrypted property added.
The reason for doing this is that as long as the aspects that are applied are highly visible and not huge in number then developers looking at your companies infrastructure code should notice it looks very similar to the code they can see on GitHub or outside their organisation since everything is a vanilla construct. This reduces the cognitive burden on developer ramp-up and ongoing maintenance.
Survival Rule 7 - Check Your Local AWS Credentials and Proxy Settings
When you try to do a cdk deploy and you get a weird error something like:
"Unable to determine default account and/or region"
What that should really say is "Something is wrong with your connection to AWS, this is probably your local credentials but you could also need to set proxy details if you are in a corporate environment".
Try deleting your local aws config files and re-running aws configure. If that doesn't work, check if you need to set proxy details.
Survival Rule 8 - Flatten Your Dependency Stack
This one matters the most when you get into custom, non AWS dependencies.
Say you work in a large organisation and therefore rather than have everyone recreate the same logic in all of their local stacks you create a MattsCommon library which contains very basic reusable things. This library has CDK as a dependency, say version 1.30.0.
Now you build an Auth0SecuredPrivateAPIGateway construct that means that developers don't have to worry about anything other than the routes on the gateway and what they integrate with. This construct will use MattsCommon which is on CDK 1.30.0 so Auth0SecuredPrivateAPIGateway will be using CDK 1.30.0.
Your local stack now pulls in Auth0SecuredPrivateAPIGateway and uses CDK 1.30.0 because Auth0SecuredPrivateAPIGateway uses 1.30.0 as a consequence of MattsCommon using 1.30.0
Now imagine CDK 1.31.0 gets released and it has a feature you desperately want. You cannot update until MattsCommon and Auth0SecuredPrivateAPIGateway update which won't be instantly. The more layers you have in this dependency stack the worse this effect gets.
Survival Rule 9 - SAM Is Your Friend
You can combine AWS CDK with AWS SAM to do local testing. This is just a case of generating your CloudFormation template and passing it into SAM
Liquid error: internal
Survival Rule 10 - Check In Your CFT
I will keep saying this, using CDK does not mean you do not need to understand CFT. It is still core to the whole AWS IAC deployment process.
You can use "cdk synth" to generate the CFT used to deploy and then add that into source control. This allows developers who don't want to read all of your source code but have skills in CloudFormation to code review your stack.
It also is a single file to show you the version history of your infrastructure changes so that if anything ever becomes misconfigured through a new CDK default you should be able to trace it back easily.

Top comments (1)
Great article, I’m using CDK a lot at the moment and I absolutely love it for a lot of the reasons outlined here. It’s a breath of fresh air to be writing actual IaC.