Chasing a hundred rabits at a time — A dev week
I wish i was that guy who is enjoying the doing more then the achieving. If i were, last week would have been a great adventure with many surprising turns… truly enjoyable. But i’m not, and thus last week felt particular annoying.
If you are into developing software you probably know those days:
- You start with a well defined task.
- You are well motivated. Already, you have it even solved — at least in your head.
- You start touching the system and things go downhill from there. You are finding one flaw after another and — if you’re not stepping back at the right time — you’re trying to solve 10 things at the same time while being pressured by not proceeding with your initial task. Not very sustainable for your brain on the long run as i perceive it.
Last week was like that for me. Every single day. Quite unusual since i haven’t had these things for a longer time and i never had them strong like that. Thus i feel the urge to write things down and recapture the story.
Context
At my company we work on a system which sits between your data warehouses and your intelligence tools (Spotlight). Kind of a unified access layer to your data in this regard.
For the past couple of weeks i was working on a benchmark suite. How is the performance of the system with a particular cluster size and a particular configuration, when the data sits in S3, when the data sits in Snowflake, when … you get it…
The Task
Integrate Redshift into our TPC-H benchmark suite
- Data in the scale factors 1, 10 and 100 was already on S3.
- Benchmark infrastructure was ready and running for a couple of other source system.
- All there left to do, was to setup the tables in Redshift and do little coding and configuration work on the benchmark setup side of things.
The Slow Start
I know we already had an Redshift cluster up and possibly even the TPC-H data was on it. Thus my first step was to discover what’s there.
That wasn’t wild, but it already started to annoy me a bit:
- With almost 10 different AWS accounts the company runs and 4 to 5 different regions in use, find you’re way through the web-console world. Good luck… But with colleagues who know, not a big deal.
- What ? You found the cluster, you have the credentials but it won’t tell you the existing databases unless you name one ? 🤦
Things going downhill — the web-service and data generation battle
The data is already on S3, i’ve now fully control over the Redshift database, i found blogs describing how to setup TPC-H on Redshift (DDL’s included), so what could possibly go wrong ?
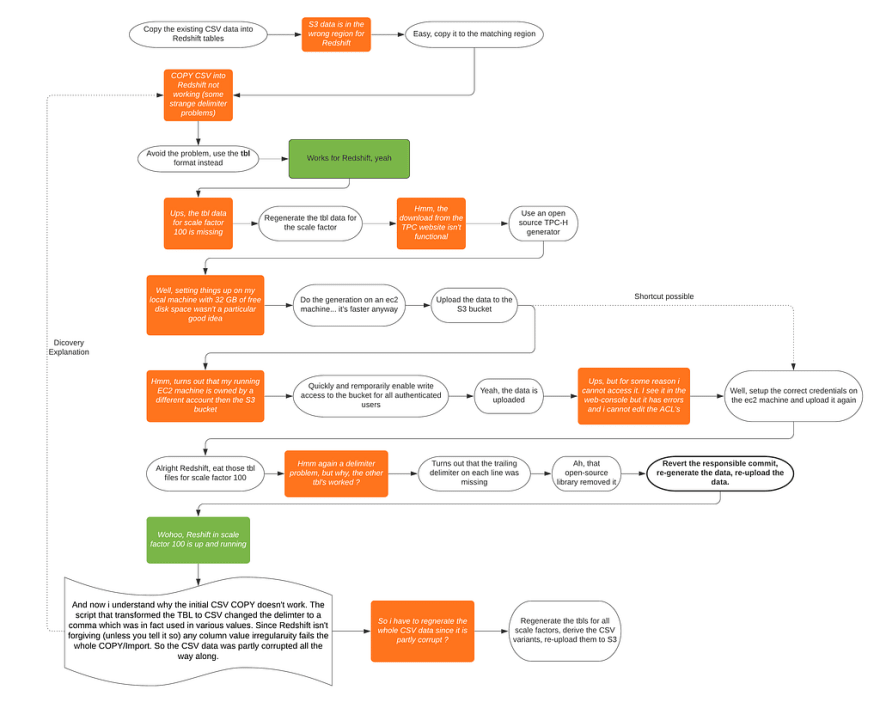
If that would have been all
As pictured in the flow graph above, getting the data in the right shape into Redshift was a longer journey than expected. I’ve didn’t even include all the details, like the EC2 machine is was using had only 2 disk, each of approximate 93 GB of free space(The benchmark data in one format was 100GB, with the biggest file 70 GB), wich required quite a bit of chunking the data generation and upload work. However, once i had this done, problems didn’t stop to flow:
- The benchmark suite started to fail on setting things up
- Did current changes in the communication protocol didn’t make it into the benchmark project ? No exactly… the deployed version was just mismatched with the client library.
- How did i find out ? Just deployed a current dev version…
- Just comes with a litlle sarcasm here. Turned out that the old way of deploying custom versions was broken. The new way didn’t work with the particular AWS account i was using. Thanks to extraordinary devops support we got things running after 5 iterations.
And just on my last weekday (Thursday for me), when things started to settle down (but i still had a couple of verifications on my list) i got a call. Hey we need you for that other urgent thing… 😤
Could i’ve done better ?
For sure i could have shortened the cycles here and there, like trying to generate the data on my laptop had no thinking attached to it at all. But even if i did all things perfectly, it still would have felt like the universe conspired against me and it wouldn’t have been considerably faster.
Final Words
Often the final judgement just depends on the perspective. There are quite some positive things that did happen on the way:
- I’ve strengthened my bash script skills to make the steps reproducible.
- I’ve learned a bit of S3 ACL syntax on the way.
- I discovered that our existing data was flawed.
- Technically, I understood it all ;)
But i guess the major thing i put on my wishlist for next year is… that i be more of that guy who enjoys a surprising challenging journey!

Top comments (2)
Wow. Kudos for eventually finding the time to put your experience together and writing about it.
Working on projects, platforms, etc. has always been about the journey for me too. Seems like the only way to get better and learn new things these days is to be in situations where things spiral downhill.
I look forward to reading more about your surprising challenging journeys next year :)
Poor you! :D