Automating Machine Learning Workflows Pt2: Amazon SageMaker Processing and AWS Step Functions Data Science SDK

In the previous blogpost, I demonstrated how to automate machine learning workflows with AWS Step Functions from data preparation with PySpark on AWS Glue to Model (Endpoint) Deployment with Amazon SageMaker. In this tutorial, I will repeat almost the same approach, however with a little adjustment in the data preparation phase.
Not all data preparation in machine learning require distributed nature of PySpark. Hence, what happens if you don’t need PySpark? Would you need to run Glue Jobs anyway? You could, but would probably be wasting Glue compute resources. One more thing to consider is the use of external libraries with AWS Glue; you have to package external libraries as zip files and upload to some external location. This process in itself might not be user friendly especially when you want to focus only on building your machine learning pipeline.
Enter Amazon SageMaker Processing, fully managed data processing and model evaluation solution. You can read more about Amazon SageMakerprocessing in this blogpost from AWS. As of the time of this post, Amazon SageMaker Processing is not yet part of AWS Step Functions Service Integrations, however, AWS Step Functions offers the flexibility to orchestrate AWS services with Lambda Functions.
Prepare the workflow
Knowing that Amazon SageMaker Processing is not natively integrated with AWS Step Functions, we will start by creating 2 Amazon Lambda functions that will orchestrate: Amazon SageMaker Processing Job creation and Amazon SageMaker Processing job status checker.
Once we have both functions in place, we are ready to define our workflow with the AWS Step Functions Data Science SDK. For more details about the AWS Step Functions Data Science SDK, you can read my previous blogpost or visit the project page on GitHub.
Amazon SageMaker Processing Jobs run processing scripts with pre-baked docker containers hosted on AWS ECR. Below, we will create a docker container with the necessary packages required for our processing job.
Note that you could as well achieve the above operation using AWS Cloudformation.
Workflow Definition
In my previous post, I demonstrated workflow definition steps from data preparation to model deployment. Since I am only replacing the AWS Glue Step, I will not go into the details of the model training and endpoint deployment steps.
Data Preparation with Amazon SageMaker Processing
We created our create-processing-job Lambda function with sensible defaults ensuring that we provide the minimum possible arguments as Amazon SageMaker Processing job configurations. Next we poll for the job status with a Lambda Function step every 60 seconds.
We then need to create the processing script, which will contain our data transformations and will be executed by Amazon SageMaker Processing on our docker container.
The above script is an example data preparation logic, depending on your use case and requirements, you might have more complex data transformation logic. Last step is to upload the processing script to an S3 location.
$ aws s3 cp scripts/preprocessing.py s3://my-code-bucket/processing/scripts/preprocessing.py
Having completed the build up to our data preparation steps, we proceed to defining our machine learning steps. For the purpose of brevity, I defined these steps in my previous post, so I will not delve into the details, but show how to chain the respective steps together:
Automating Machine Learning Workflows with AWS Glue, SageMaker and AWS Step Functions Data Science…
ml\_steps\_definition = Chain([
training\_step,
model\_step,
endpoint\_config\_step,
endpoint\_step,
workflow\_success
])
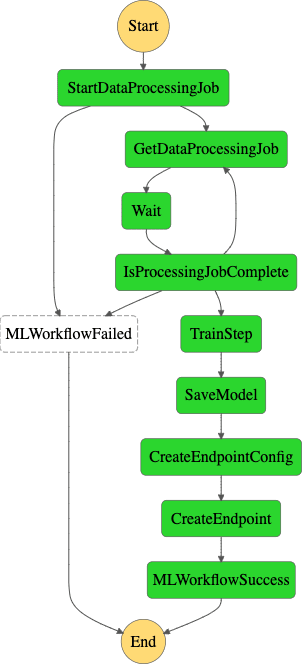
To build the entire workflow graph, we will make use of AWS Step Function Choice States, which adds a branching logic to our workflow. The choice state checks the status of the data processing job, and proceeds to next steps based on the job status:
check\_job\_choice = Choice(
state\_id= **"IsProcessingJobComplete"**
)
check\_job\_choice.add\_choice(
ChoiceRule.StringEquals(variable=get\_processing\_job\_status.output()[**'Payload'**][**'ProcessingJobStatus'**], value= **'InProgress'** ),
next\_step=get\_processing\_job\_status
)
check\_job\_choice.add\_choice(
ChoiceRule.StringEquals(variable=get\_processing\_job\_status.output()[**'Payload'**][**'ProcessingJobStatus'**], value= **'Stopping'** ),
next\_step=get\_processing\_job\_status
)
check\_job\_choice.add\_choice(
ChoiceRule.StringEquals(variable=get\_processing\_job\_status.output()[**'Payload'**][**'ProcessingJobStatus'**], value= **'Failed'** ),
next\_step=workflow\_failure
)
check\_job\_choice.add\_choice(
ChoiceRule.StringEquals(variable=get\_processing\_job\_status.output()[**'Payload'**][**'ProcessingJobStatus'**], value= **'Stopped'** ),
next\_step=workflow\_failure
)
check\_job\_choice.add\_choice(
ChoiceRule.StringEquals(variable=get\_processing\_job\_status.output()[**'Payload'**][**'ProcessingJobStatus'**], value= **'Completed'** ),
next\_step=ml\_steps\_definition
)
The choice state is explained as follows: if the processing job is running, it loops back to check the job status, if the job failed, the entire workflow is terminated and if the job is completed, it proceeds to the model training and endpoint deployment steps.
Our complete machine learning workflow is chained together as the following:
ml\_workflow\_definition = Chain(
[
create\_processing\_job\_step,
get\_processing\_job\_status,
check\_job\_wait\_state,
check\_job\_choice
]
)
ml\_workflow = Workflow(
name= **"MyCompleteMLWorkflow\_v2"** ,
definition=ml\_workflow\_definition,
role=workflow\_execution\_role
)
Create and execute the workflow:
**try** :
workflow\_arn = ml\_workflow.create()
**except** BaseException **as** e:
print( **"Workflow already exists"** )
workflow\_arn = ml\_workflow.update(ml\_workflow\_definition)
# execute workflow
ml\_workflow.execute(
inputs={
**'IAMRole'** : **sagemaker\_execution\_role** ,
**'EcrContainerUri'** : **'1234567890.dkr.ecr.eu-west-1.amazonaws.com/sagemaker-processing-container'** ,
**'S3InputDataPath'** : **f's3://{data\_bucket}/raw-data/'** ,
**'S3OutputDataPath'** : **f's3://{data\_bucket}/{processed\_data\_output\_path}/'** ,
**'S3CodePath'** : **'s3://my-code-bucket/processing/scripts/preprocessing.py'** ,
**'JobName'** : job\_name,
**'ModelName'** : model\_name_,_
**'EndpointName'** : endpoint\_name
}
)
Conclusion
In my previous post, I demonstrated how to create an end-to-end machine learning workflow on AWS using AWS Glue for data preparation. In this post, I swapped the data preparation component with Amazon SageMaker processing. Your choice of AWS Service to execute data processing job on depends on your use case. You can also use with Step Functions service integration with AWS EMR to run your data preparation jobs which is also supported natively by the AWS Step Functions Data Science SDK.
Further Reading
- Part 1: Automating Machine Learning Workflows with AWS Glue, Amazon SageMaker and AWS Step Functions Data Science SDK
- Amazon Step Functions
- Amazon Step Functions Developer Guide
- AWS Step Functions Data Science SDK
- Amazon Glue
Kindly share your thoughts and comments — looking forward to your feedback. You can reach me via email, follow me on Twitter or connect with me on LinkedIn. Can’t wait to hear from you!!

Top comments (0)