
À medida que a marolinha do DynamoDB está ficando cada vez mais maior, mais equipes estão olhando para ele com mais curiosidade. Este artigo deve ser o primeiro de uma série que visa explorar o DynamoDB com mais detalhes.
Mas, antes de abordar algum dos tópicos mais densos, é importante se acostumar com as terminologias usadas no mundo do DynamoDB. Abaixo está uma representação gráfica de uma tabela do DynamoDB.
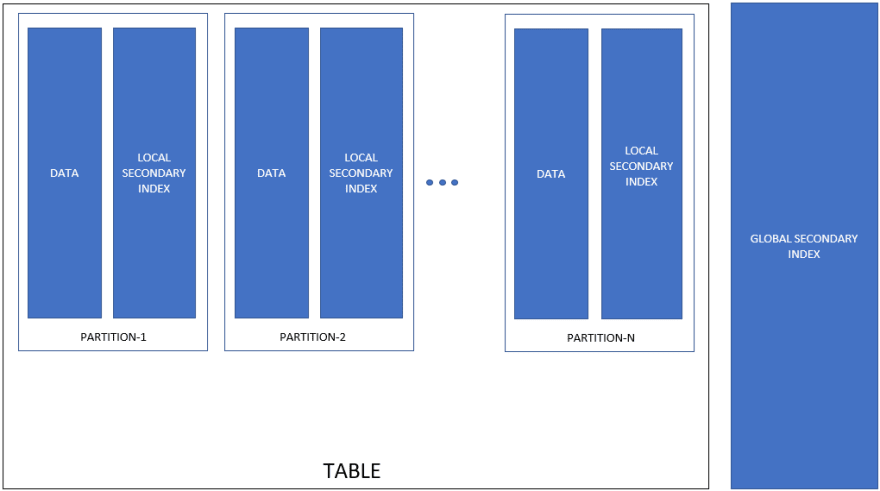
Ilustração de uma tabela do DynamoDB, exibindo suas partições
Como pode ser visto na imagem acima:
- Cada tabela do DynamoDB é dividida em uma ou mais partições.
- Cada partição contém um subconjunto dos dados da tabela, além de índices secundários locais (// A) criados nesses dados da partição.
- Os índices secundários globais são armazenados e mantidos separadamente das partições e indexam a tabela inteira (não são específicos para uma partição).
// A: Os elementos internos do DynamoDB não são visíveis ao público. Portanto, a estrutura interna da partição mostrada acima é apenas uma ilustração destinada a explicar o comportamento observado.
Uma imagem mais detalhada, mostrando uma partição pode ser encontrada abaixo:

Ilustração dos atributos de uma tabela do DynamoDB, Créditos: http://codedevstuff.blogspot.com/2016/08/install-local-instance-of-aws-dynamodb.html
Conforme a imagem acima:
- Cada tabela consiste de vários itens.
- Cada item pode conter um ou mais atributos.
- Cada item deve conter pelo menos um atributo, que será sua chave de partição (partition key).
- Para cada operação CRUD na tabela, a operação deve especificar a chave de partição do item.
- Além da chave de partição, uma definição de tabela pode atribuir qualquer atributo como sua chave de classificação (sort key).
- As operações de leitura na tabela podem especificar a chave de classificação, para consultas mais avançadas ("contains", "begins with" etc.)
- Um grupo de itens na tabela é chamado de coleção de itens.
O DynamoDB é um serviço na nuvem. A Amazon hospeda toda a infraestrutura necessária para executar uma instância do DynamoDB para seus clientes. Em troca, os clientes devem pagar pelo seguinte:
- Toda solicitação de leitura (read unit)
- Toda solicitação de gravação (write unit)
- Cada byte de armazenamento usado (storage)
A moeda corrente para essas solicitações são RCU (Read Capacity Units) e WCU (Write Capacity Units). Em geral, uma tabela do DynamoDB precisa ter uma certa RCU/WCU provisionada (// B) no momento da criação (pode ser modificada a qualquer momento também) e a tabela pode servir quantas leituras/gravações forem necessárias, desde que a RCU/WCU provisionada suporte o tráfego.
// B: Isso é apenas se você estiver usando o "Modo de Capacidade Provisionada". Desde novembro de 2018, a Amazon introduziu o "Modo de Capacidade Sob Demanda" para cargas de trabalho imprevisíveis. A diferenciação está fora do escopo desse artigo. Consulte a publicação nº 3 desta série, se você estiver interessado em aprender mais sobre a diferença entre os modos de capacidade "Provisionado" e "Sob-Demanda" - Obrigado a Kirk Kirkconnell por apontar isso.
Agora, várias dessas terminologias e a estrutura geral da tabela podem parecer muito familiares para os usuários do Cassandra. As equipes que já usam Cassandra podem se perguntar: "Por que o DynamoDB então?"
Isso será explicado em mais detalhes na Parte 2 desta série.
Série "Iniciando com Amazon DynamoDB"
- Parte 1: O que é o Amazon DynamoDB
- Parte 2: Por que migrar do Cassandra para o Amazon DynamoDB?
- Parte 3: Modelagem de Dados
- Parte 4: Regras para leituras e gravações mais rápidas
- Parte 5: Índices Eficientes
Créditos
- DynamoDB: Basics, escrito originalmente por Sasidhar Sekar.

Top comments (0)