
Já se passaram três meses do ano 2020 e todo o mundo da tecnologia está adotando a computação serverless. Segundo o relatório Tech Trends 2020 da Nasdaq, "[computação serverless] está reduzindo os custos de capital e mudando o foco para as necessidades dos clientes, ao invés de instalar, configurar, aplicar patches e manter servidores no data center".
A computação serverless pode ser e está sendo usada em muitos casos de uso técnico, com ganhos significativos em relação à abordagem tradicional baseada em servidor. Um desses casos de uso é o desenvolvimento de APIs HTTP. Nos dias pré-servidor, o desenvolvimento de uma API incluía muitas responsabilidades; desenvolvendo a lógica de negócios real, configurando um servidor web adequado, gerenciando deploys do servidor, protegendo as APIs e cuidando da disponibilidade e da escalabilidade da API ao longo do dia. Porém, com a erupção das tecnologias serverless, a maioria dessas responsabilidades é assumida pelo provedor de serviços em nuvem e o desenvolvedor tem a flexibilidade de simplesmente se concentrar na lógica de negócios real das APIs.
Neste artigo, vamos primeiro analisar brevemente os serviços relacionados ao desenvolvimento de APIs fornecidos pelo provedor de serviços em nuvem mais popular, Amazon Web Services (AWS), e discutir três dos aspectos mais importantes a serem considerados ao projetar e implantar APIs que utilizam esses serviços.
API Serverless com Amazon Web Services (AWS)
Na AWS, a criação de uma API serverless envolve dois serviços, que são o AWS API Gateway e o AWS Lambda. O AWS API Gateway pode ser usado para gerenciar os endpoints da API e cuida completamente da manipulação de solicitação-resposta no nível HTTP. Além disso, o API Gateway fornece os recursos para gerenciar versões da API com estágios, recursos de segurança da API com vários tipos de mecanismos de autorização e também diferentes tipos de controles de limitação de solicitação da API.
Em seguida, as funções do AWS Lambda podem ser utilizadas para lidar com a lógica comercial dessas chamadas de API recebidas pelos endpoints do API Gateway. Cada endpoint do API Gateway pode ser integrado ao Lambda como um acionador para que, quando uma solicitação for recebida por um endpoint específico, a função Lambda configurada seja invocada com os detalhes da solicitação. Em seguida, a função Lambda pode processar a solicitação e retornar uma resposta adequada ao API Gateway. O API Gateway gerará a resposta HTTP com base nisso e a enviará de volta ao cliente que chamou a API.
Agora, vamos ver três dos aspectos mais importantes a serem observados ao criar APIs com esses serviços.
1. Mapeando endpoints do API Gateway para funções do AWS Lambda
Uma das decisões de design mais críticas a serem tomadas quando uma API sem servidor é projetada é como os endpoints da API podem ser mapeados para as funções do AWS Lambda para processar as solicitações. Vamos examinar duas das abordagens mais usadas.

Vamos considerar uma API de uma loja de varejo on-line para discutir essas abordagens. Essa API será usada para gerenciar recursos, como usuários, itens de varejo e compras, enquanto cada um desses recursos terá vários endpoints e métodos para diferentes operações.
1.1. Abordagem 1: Uma lambda por recurso

Nesta abordagem, todas as solicitações para um recurso específico serão direcionadas para a mesma função Lambda. Em seguida, na função Lambda, essas solicitações serão redirecionadas para diferentes ramificações de processamento com base na operação solicitada. Por exemplo, uma solicitação para criar um novo usuário e uma solicitação para recuperar detalhes de um usuário existente chamarão a mesma função Lambda. Uma solicitação para atualizar um item listado e uma solicitação para obter uma lista dos itens disponíveis chamarão outra função Lambda. Em seguida, o código Lambda invocado identificará a operação solicitada e a processará de acordo. Uma biblioteca como o AWS Serverless Express pode ser utilizada para executar esse roteamento interno com facilidade e eficiência.
Vantagens
- Menor número de funções Lambda a serem gerenciadas
- Fácil de reutilizar códigos, bibliotecas e utilitários comuns específicos de recursos entre operações
- Modificações em todo o recurso requerem a atualização de apenas uma função Lambda
Desvantagens
- Uma atualização para uma única operação pode afetar todas as operações na mesma função Lambda
- O roteamento em dois níveis (primeiro no nível do API Gateway e, em seguida, no nível interno do lambda) pode introduzir uma sobrecarga
- A mesma função lambda deve ser concedida para ter todas as permissões de execução necessárias para cada operação, o que pode ser um risco à segurança
- Não é possível ajustar os parâmetros da função Lambda, como memória, tempo limite e execuções simultâneas com base na operação
- Se houver bibliotecas específicas da operação, todas elas serão carregadas, independentemente da operação a ser executada, o que pode estender o tempo de inicialização a frio do Lambda
1.2. Abordagem 2: Uma lambda por operação

Nesta abordagem, há uma função Lambda separada para cada operação de cada recurso. Por exemplo, uma solicitação para criar um novo usuário será processada por uma função Lambda, enquanto uma solicitação para recuperar detalhes de um usuário existente será processada por outra. Nesse caso, não há necessidade de um mecanismo de roteamento interno e o roteamento é completamente executado no nível do API Gateway.
Vantagens
- Cada operação pode ser atualizada e testada independentemente, sem afetar outras operações
- A função Lambda deve receber apenas as permissões mínimas de execução para a operação específica
- Os parâmetros da função Lambda, como memória, tempo limite e execuções simultâneas, podem ser ajustados com base na operação
- Cada função Lambda exige carregar apenas as bibliotecas necessárias para a operação pretendida
Desvantagens
- Grande número de funções Lambda a serem gerenciadas
- Modificações em todo o recurso requerem a atualização de várias funções Lambda
- A reutilização de códigos comuns específicos de recursos, bibliotecas e utilitários entre operações exigirá medidas adicionais, como publicá-las como módulos Node.js ou Lambda Layers
Como mencionado acima, ambas as abordagens têm suas próprias vantagens e desvantagens do ponto de vista do desempenho e do ponto de vista do gerenciamento de código e deploy. Portanto, é nossa responsabilidade escolher a abordagem apropriada com base em nossos requisitos e caso de uso.
2. Temos dois tipos de integração: lambda e lambda-proxy
O AWS API Gateway fornece duas maneiras principais de integrar seus endpoints a funções Lambda. Com base nas informações exigidas pela função Lambda para processar a solicitação, precisamos selecionar um desses métodos de integração para cada um dos nossos métodos de integração do API Gateway-Lambda.
2.1. Integração 1: Lambda
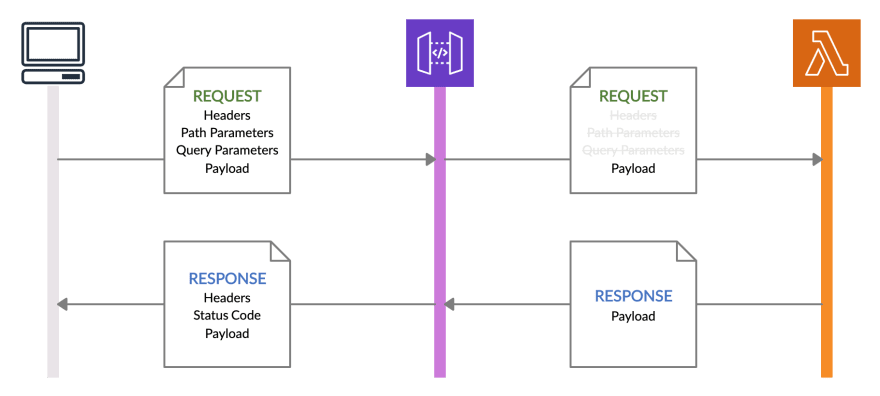
O primeiro método é o método de integração regular do Lambda (no API Gateway teremos "type": "aws"), no qual o API Gateway encaminha apenas o payload da solicitação para a função Lambda como evento. Em seguida, a função Lambda também é obrigada a enviar apenas o payload da resposta ao API Gateway. Nos casos em que a função Lambda precisa apenas do payload da solicitação para processar a solicitação, podemos usar esse método de integração.
2.2. Integração 2: Lambda-Proxy

O segundo método é a integração do Lambda Proxy (no API Gateway teremos "type": "aws_proxy"), na qual o API Gateway encaminha os detalhes completos da solicitação HTTP para a função Lambda, incluindo:
- cabeçalhos da requisição
- parâmetros de caminho
- parâmetros de query string
- detalhes do recurso e requisição
- informação do stage do API Gateway
- e, claro, o payload
Em seguida, a função Lambda também é responsável por enviar de volta os cabeçalhos de resposta e o código de status, além da carga útil da resposta. Nos casos em que a função Lambda precisa das informações e valores do cabeçalho e parâmetros de caminho/query string para seu processamento, podemos usar esse método de integração.
3. Autenticação da API
O controle de acesso e a autenticação são outro fator importante a ser considerado ao projetar não apenas APIs serverless, mas também qualquer tipo de API. Portanto, o AWS API Gateway também fornece os seguintes mecanismos para autenticação e autorização:
- Políticas de Recursos (Resource Policies)
- Funções e Políticas padrão do AWS IAM (IAM Roles and Policies)
- Tags IAM
- Políticas de Endpoints para se comunicar com VPC Endpoints (Endpoint Policies)
- Autorizadores Lambda (Lambda Authorizers)
- Pools de usuários do Amazon Cognito
Desses, os dois últimos mecanismos são amplamente usados com as APIs serverless no API Gateway. Portanto, vamos ver brevemente o que esses dois mecanismos oferecem.
3.1. Pools de usuários do Amazon Cognito

Se estivermos usando o serviço AWS Cognito para gerenciamento de usuários, esse mecanismo é a maneira mais conveniente e eficiente de autenticar solicitações de API. Quando esse mecanismo é usado, precisamos criar um autorizador no API Gateway especificando quais pools de usuários do Cognito devem ser usados para conceder acesso a essa API. Em seguida, o cliente deve enviar um token de ID válido do Cognito (ou token de Acesso, dependendo da configuração) como um cabeçalho HTTP da solicitação. Normalmente, isso deve ser enviado como o cabeçalho Authorization, mas é possível configurar o autorizador para usar também qualquer outro cabeçalho personalizado.
Depois que essa solicitação é recebida pelo API Gateway, ele usa esse token para autenticar o usuário com o pool de usuários do Cognito. Se a autenticação for bem-sucedida, a função Lambda relevante será invocada como de costume. Se a integração Lambda-Proxy for usada, os detalhes do usuário decodificados do token também serão incluídos no evento passado para o Lambda, portanto, é muito conveniente e útil executar operações específicas do usuário. Caso a autenticação falhe, o próprio API Gateway envia de volta uma resposta 401 Unauthorized, sem chamar a função Lambda.
3.2. Autorizadores Lambda (Lambda Authorizers)

Nesse mecanismo, precisamos configurar uma função Lambda exclusiva para autenticação e criar um autorizador no API Gateway apontando para ela. Existem 2 tipos de autorizadores Lambda.
- Baseados em Token (Autorizador TOKEN): Esse tipo de autorizador recebe a identidade do chamador em um token bearer, como um JSON Web Token (JWT) ou um token OAuth.
- Baseado em Parâmetros (Autorizador REQUEST): Este tipo de autorizador recebe a identidade do chamador como uma combinação de cabeçalhos, query string de consulta, variáveis de estágio e variáveis de contexto.
Depois que uma solicitação é recebida pelo API Gateway, ele primeiro chama a função Lambda do autorizador com os detalhes da solicitação. Em seguida, o autorizador do Lambda autentica o chamador usando um mecanismo de etapas como:
- chamando um provedor OAuth para obter um token de acesso OAuth
- chamando um provedor SAML para obter uma asserção SAML
- gerando uma política do IAM com base nos valores dos parâmetros de solicitação
- recuperando credenciais de um banco de dados
Se a autenticação for bem-sucedida, a função Lambda deverá conceder acesso retornando um objeto de saída que contenha pelo menos uma política IAM (IAM Policy) e um identificador principal (principal identifier).
Em seguida, o API Gateway avalia a política e, se o acesso for permitido, a função Lambda será invocada a seguir. Se o armazenamento em cache estiver ativado nas configurações do autorizador, o API Gateway também armazenará em cache a política para que a função do autorizador Lambda não precise ser chamada novamente. Caso a autenticação falhe, o API Gateway retornará um código de status HTTP adequado, como 403 ACCESS_DENIED.
Finalizando
Portanto, como discutido acima, esses são três dos aspectos mais importantes a serem considerados ao projetar uma API serverless. Se pudermos escolher ou configurá-los adequadamente, isso tornará o gerenciamento e a manutenção das APIs mais eficientes e convenientes.
Créditos
- 3 Things to consider when designing a Serverless API, escrito originalmente por Udith Gunaratna.

Top comments (2)
Muito bom o artigo! :)
Eu fiquei com uma dúvida. Nos dois exemplos de integração com as lambdas, elas parecem que estão respondendo requests do frontend, então a autenticação/autorização pelo bearer é do usuário, é isso mesmo?
Neste caso, imagine que uma lambda X quisesse chamar outra lambda Y (por exemplo, todas a mini-lambdas do segundo exemplo chamassem uma lambda de log depois de cada execução), ela também passaria pela mesma autenticação? Lambda X consegue chamar a lambda Y sem autenticação (pois estão no mesmo domínio ou algo do tipo), ou não, elas são completamente independentes? No caso de ter que passar um token de autenticação, qual token passaria, um long lived que autentica a lambda X ou o mesmo token que ela recebeu?
obrigado o tempo investido no comentário Bruno,
vou quebrar em pequenos trechos o que você falou e tentar abordar isoladamente cada um deles,
vou assumir que você esteja falando da sessão 2.1 e 2.2, realmente temos a imagem tem um computador com tela no lado esquerdo, então faz sentido assumir "frontend", mas ao pensarmos em "cliente", a solicitação pode estar vindo de qualquer consumidor (e.g. mobile app, outra api, um iot device, um frontend etc)
a diferença principal é o objeto de evento que a lambda recebe, como descrito nas imagens 2.1 e 2.2
como mencionado na sessão 3, os usos mais comuns de autenticação no API Gateway são Lambda Authorizers e Amazon Cognito User Pools como Authorizers.
Como Lambda Authorizers podem executar qualquer tipo de lógica que você quiser, as opções são inúmeras aqui. E sim, utilizar autenticação baseadas em tokens, como OAuth 2.0, é uma opção.
Já para Amazon Cognito User Pools, a única opção é um request assinado e validado com as credenciais do Cognito, bibliotecas como amazon-cognito-identity-js ou amplify-js cuidam disso para gente no ecosistema JavaScript.
vou trabalhar esse exemplo, mas vou comentar que ter uma lambda para log, como descrito, é desnecessário, pois a integração com CloudWatch no AWS Lambda é nativa.
o que me chama atenção aqui é o "...depois de cada execução", não há como "chamar uma lambda após a execução" aqui,
como estamos trabalhando com execuções síncronas do API Gateway, você terá que usar o aws-sdk para lambda e executar um
.invokeouinvokeAsyncainda dentro do handler da sua função ou executar uma chamada HTTP no endereço completo da API Gateway da segunda lambda, seja comhttp/httpsou alguma lib com suporte node.js comosuperagentouaxios,a resposta curta é: ela não passa pela mesma autenticação, Lambda X consegue sim chamar Lambda Y sem autenticação e não é porque estão no mesmo domínio, e sim elas são completamente independentes,
meio confuso? vou expandir a resposta abaixo,
a resposta longa é:
se você utilisar o aws-sdk, a Lambda X precisa de IAM Policies para invocar Lambdas (e.g.
lambda:InvokeFunction), ou seja, você passa/bypass todas as features do API Gateway (e.g. Lambda e Cognito Authorizers) e executa a função diretamente.caso você use uma chamada HTTP, você estará realizando uma chamada do começo da jornada, entrando pelo API Gateway, então tudo que o API Gateway precisar para aceitar o request, você precisar providenciar. Nesse caso, se você estiver utilizando um Lambda Authorizer, o que for necessário para o seu código de autenticação e no caso de Amazon Cognito, um request assinado e validado como mencionado acima,
caso sua autenticação aconteça DENTRO da sua Lambda, em código dentro do handler, então seja com aws-sdk ou HTTP request, você precisará fornecer as credenciais necessárias
caso sua autenticação seja feita no API Gateway (e.g. Lambda e Cognito Authorizers), o cenário descrito acima se aplica, aws-sdk bypass, e os dois casos de HTTP,
como mostrado acima, temos vários cenários, vou me focar e assumir o seguinte cenário:
jwt.verifyetcassumindo o cenário acima, teremos o seguinte flow:
fatos a considerar:
ficou claro agora? qualquer coisa só mandar a pergunta! :D
e pensando no seguinte caso:
nesse caso, podemos usar uma das opções descritas na sessão 3, no contexto do exemplo, eu recomendaria Lambda Authorizers ou IAM Policies.
com Lambda Authorizers: você pode procurar algum secret no headers que não seja público e você coloca esse secret apenas quando o request for executado de outra Lambda etc
com IAM Policies: ao usar
authorizationType: AWS_IAMvocê precisará ter um request assinado e validado e as credenciais, baseado no nosso exemplo acima, serão das permissões da IAM Role da Lambda X. Ou seja, teremos: Lambda Y exposta como endpoint e sua autorização no API Gateway é AWS_IAM, se alguém tentar chamar esse endpoint, precisará que sele seja assinado/validado, na execução da Lambda X, assinamos um request com aws4 que irá assumir as credenciais da Lambda X e adicionar os headers necessários, permitindo chamar o endpoint da Lambda Y.ufa, acabou, qualquer coisa estamos aí! 🤙🤙🤙