
When Your AI Agent Makes the Right Call But Your System Doesn't Follow Through
You built an agent that works. The model is sharp, the decisions are correct — and yet, customers are still getting burned. Here's why, and how to fix it for good.
There's a moment every developer building AI agents eventually hits. The demo goes well. The model makes the right call. Everyone's impressed. Then you ship it, and three days later, a customer is furious because the refund the agent approved never actually happened.
The agent didn't fail. The system did.
This is the problem nobody talks about when they're showing off agentic workflows: the gap between a decision being made and that decision being trusted by the rest of your platform. That gap — the handoff — is where reliability goes to die.
In this post, I want to talk about a pattern that solves this elegantly: the Transactional Outbox Pattern, paired with Redis Streams. It's not new. It's been a quiet workhorse in microservices architecture for years. But it's exactly the kind of infrastructure thinking that agentic systems desperately need right now.
I also write about patterns like this on my engineering blog at kallis.in — feel free to check it out if this kind of systems design content interests you.
The Real Problem: The Handoff
Picture this: your customer support agent reads a conversation, applies the refund policy, and returns "approve the refund". Your service then does two things:
- Updates the support case record to
refund_approved - Publishes an event to billing so the money actually moves
Seems simple. Until your process crashes between step 1 and step 2.
Now your case record says "refund approved." Billing never got the event. The customer waits, gets nothing, calls support, and that conversation becomes a manual investigation. The worst part? If you check the database, everything looks fine. The bug is invisible until someone notices the money never moved.
[Agent Decision] → [Update Case ✅] → 💥 crash → [Publish Event ❌]
Result: Case says "approved". Customer gets nothing.
This isn't an AI problem. It's a handoff problem. And it's been around long before LLMs were in the picture.
Why "Just Retry" Doesn't Save You
The instinctive fix most developers reach for is retries. "If the publish fails, retry it." Reasonable — until you think about where the failure happens.
Retries only help if your application still knows it has something to retry. If the process crashes after the state update but before the event is written anywhere, there's nothing left to retry. The knowledge of "I need to publish this event" died with the process.
This is the core distinction:
| Approach | What it solves |
|---|---|
| Retries | Delivering an event that already exists |
| Transactional Outbox | Ensuring the event exists in the first place |
Once you see it that way, the Outbox pattern stops feeling like ceremony and starts feeling like basic correctness.
What the Transactional Outbox Pattern Actually Does
The idea is straightforward: when your business state changes, write an event record in the same atomic operation. Don't publish the event directly to a message broker. Write it to an outbox table (or stream) that lives alongside your data, in the same commit.
A dedicated relay process then reads from the outbox and delivers events to downstream systems. If delivery fails, the event is still in the outbox. Nothing is lost.
Before (fragile):
1. UPDATE case SET status = 'refund_approved'
2. PUBLISH RefundApproved to billing ← can fail silently
After (outbox pattern):
1. ATOMICALLY:
UPDATE case SET status = 'refund_approved'
INSERT INTO outbox (event_type, payload) VALUES ('RefundApproved', {...})
2. Relay picks up outbox row → delivers to billing (retryable, durable)
The request path now only has one job: commit the decision and the event together. Everything after that is recoverable.
Why Redis Streams Fit This Beautifully
The Transactional Outbox pattern is most commonly associated with Kafka + Debezium. That stack is powerful, but it's also heavy. You're managing Kafka brokers, ZooKeeper (or KRaft), Debezium connectors, schema registries — and you haven't even started on your actual application yet.
Redis Streams offer a much lighter path that preserves the semantics you need:
- Append-only log — events are written in order and stay there
- Consumer groups — billing, notifications, and CRM sync can each consume independently, at their own pace
- Pending entry tracking — Redis knows which messages have been delivered but not yet acknowledged
- Built-in recovery — unacknowledged messages stay in the pending list and can be reclaimed
But the biggest win isn't any of those features individually. It's this: if your application state also lives in Redis, the case update and the outbox append can share a single MULTI/EXEC transaction. One atomic commit. No dual-write problem.
With Kafka, you're coordinating two separate distributed systems. With Redis Streams, it's one.
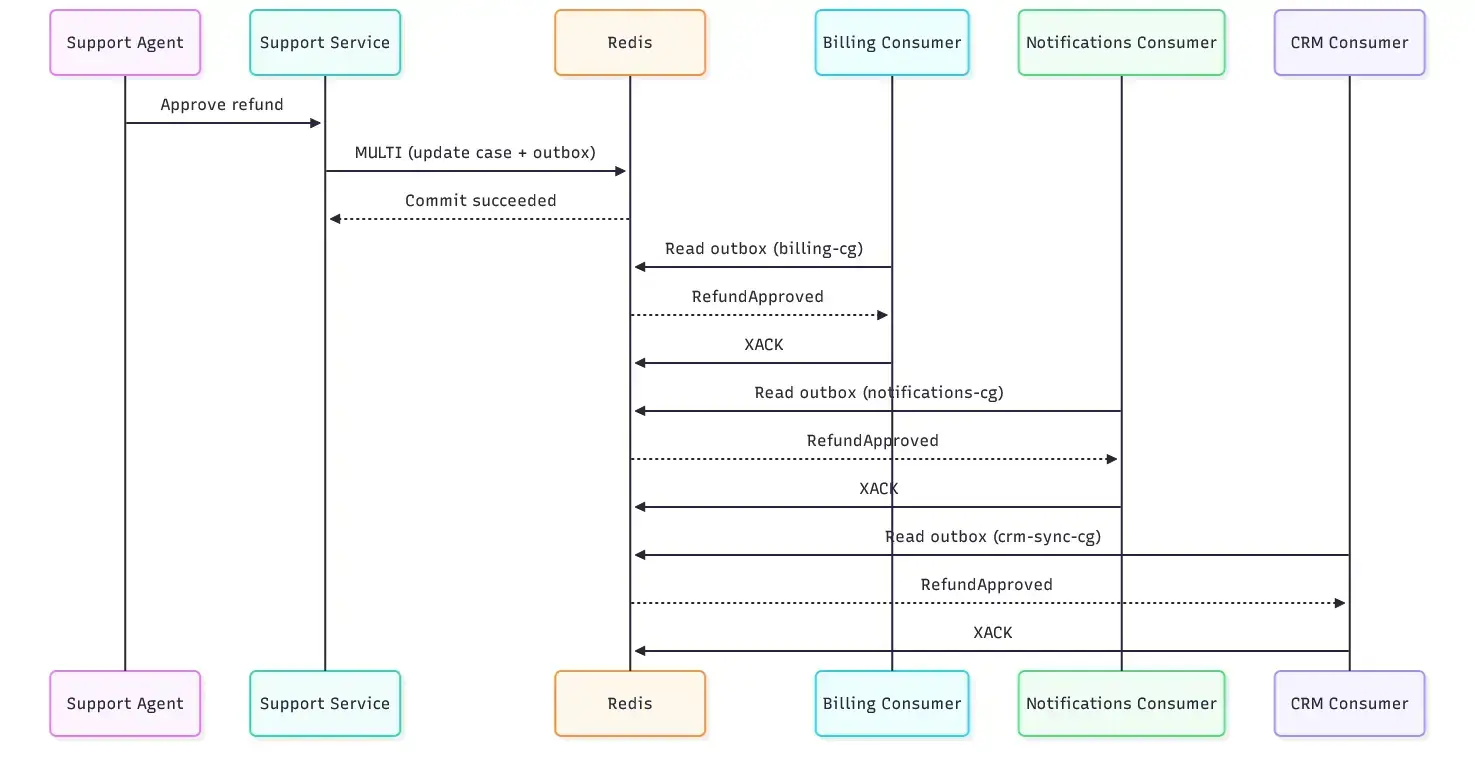
The Architecture
Here's how the pieces fit together for a customer support agent scenario:
State lives in a Redis Hash:
support:{tenant-acme}:case:case-123 → { status: "refund_approved", ... }
Outbox lives in a Redis Stream:
support:{tenant-acme}:outbox → [ RefundApproved event, ... ]
The hash tag {tenant-acme} is doing important work here. In a clustered Redis setup, keys with the same hash tag are guaranteed to land in the same slot — which is what makes them eligible for the same transaction. Miss this and your MULTI/EXEC will fail in production in ways that are maddening to debug.
From there, downstream consumer groups each process the stream independently:
┌─► billing-cg → issues refund
outbox stream ────────────┼─► notifications-cg → emails customer
└─► crm-sync-cg → updates CRM
Each group moves at its own pace. If billing is slow, notifications aren't blocked. If CRM sync has a bug, billing keeps working.

Trade-offs Worth Thinking Through
Source of truth colocation
The pattern is strongest when your business state and outbox live in the same datastore. If your case data is in Postgres and your outbox is in Redis, you're back in dual-write territory with extra steps. Colocate them.
Per-tenant streams over global streams
A single global outbox stream sounds tempting but becomes a pain in clustered Redis. Per-tenant streams keep related events together, enable better ordering guarantees, and make incident investigation dramatically easier.
Idempotency is non-negotiable
The outbox makes the handoff durable, but it doesn't make effects exactly-once. If a worker crashes after processing but before acknowledging, another worker will retry the same event. Your downstream handlers must be safe to run more than once. Treat stream entries as immutable facts, not mutable instructions.
Retention needs a policy before go-live
An outbox is a log, and logs grow. Trim too aggressively and you lose your replay window. Never trim and you have a slow-growing operational problem. Set a MAXLEN policy before you ship and revisit it regularly.
Redis is now part of your correctness model
If the outbox carries refunds and escalations, Redis isn't a cache anymore. It's part of your durability story. That means thinking seriously about replication, AOF persistence, failover, and what happens during a Redis primary failure.
Let's Look at the Code
Here's how this looks in practice using Java and Jedis. The same concepts translate cleanly to any Redis client.
Key structure
public record SupportKeys(String caseKey, String outboxKey) {
public static SupportKeys forCase(String tenantId, String caseId) {
String hashTag = "{" + tenantId + "}";
return new SupportKeys(
"support:" + hashTag + ":case:" + caseId,
"support:" + hashTag + ":outbox"
);
}
}
The hash tag ensures both keys land in the same Redis cluster slot — making them transactable together.
The atomic write — the heart of the pattern
public RefundCommitted approveRefund(RefundDecision decision) {
SupportKeys keys = SupportKeys.forCase(decision.tenantId(), decision.caseId());
// Case state update
Map<String, String> caseFields = new LinkedHashMap<>();
caseFields.put("status", "refund_approved");
caseFields.put("updated_at", decision.decidedAt().toString());
// ... other fields
// Outbox event
Map<String, String> outboxFields = new LinkedHashMap<>();
outboxFields.put("event_type", "RefundApproved");
outboxFields.put("event_id", decision.eventId());
outboxFields.put("refund_id", decision.refundId());
// ... other fields
try (AbstractTransaction redisTx = jedis.multi()) {
redisTx.hset(keys.caseKey(), caseFields); // update state
Response<StreamEntryID> streamId =
redisTx.xadd(keys.outboxKey(), // write outbox event
StreamEntryID.NEW_ENTRY, outboxFields);
List<Object> results = redisTx.exec();
if (results == null) {
throw new IllegalStateException("Transaction aborted");
}
return new RefundCommitted(decision.caseId(), decision.eventId(),
streamId.get().toString());
}
}
This is the entire correctness guarantee in one block. Either both writes happen or neither does. The downstream world never sees a case that changed without a corresponding event.

The consumer — processing with recovery
public void run(String tenantId) throws InterruptedException {
String outboxKey = SupportKeys.forCase(tenantId, "unused").outboxKey();
createConsumerGroup(outboxKey);
while (!Thread.currentThread().isInterrupted()) {
// First: drain anything pending from a previous crashed worker
List<StreamMessage> pending = readGroup(outboxKey, PENDING_ID, 10);
if (!pending.isEmpty()) {
processEntries(outboxKey, pending);
continue;
}
// Then: pick up new entries
List<StreamMessage> fresh = readGroup(outboxKey, NEW_ENTRY_ID, 10);
if (!fresh.isEmpty()) {
processEntries(outboxKey, fresh);
} else {
Thread.sleep(200L);
}
}
}
The key detail here is the two-pass approach: always drain pending entries first. If a worker crashed mid-processing, those entries are still sitting in the pending list with the previous consumer's name attached. This loop ensures they get picked up and retried — which is exactly the recovery behavior the pattern is designed to provide.
Processing looks like this:
private void processEntries(String outboxKey, List<StreamMessage> entries) {
for (StreamMessage message : entries) {
try {
String eventType = message.fields().get("event_type");
if ("RefundApproved".equals(eventType)) {
billingGateway.issueRefund(
message.fields().get("refund_id"),
message.fields().get("customer_id")
);
}
// Acknowledge only after successful processing
jedis.xack(outboxKey, BILLING_GROUP_NAME, message.id());
} catch (Exception e) {
// Log and move on — message stays pending for retry
log.error("Failed to process {}: {}", message.id(), e.getMessage());
}
}
}
Acknowledge only after you've successfully processed. Never before. That's what keeps the pending list accurate and recovery reliable.
Key Takeaways
If you're building AI agents that trigger real-world actions, here's what to walk away with:
The agent isn't the reliability problem. The handoff between the agent's decision and the downstream work is where things break.
"Save state, then publish" is fragile by design. Any crash in the gap creates invisible inconsistency that only surfaces later, during customer complaints or manual audits.
The Transactional Outbox pattern removes the worst failure mode by making the decision and the event a single atomic commit. If the commit succeeds, the event exists and delivery becomes a recoverable problem.
Redis Streams are a lightweight, well-suited fit — especially when your application state is also in Redis. The hash tag design for cluster slot colocation is the detail that makes it actually work in production.
Idempotency and retention aren't optional. Design for them before you ship, not after you hit the problem.
Agentic systems are getting more capable quickly. But capability without reliability is just a more impressive way to fail. Patterns like this are what turn impressive demos into trustworthy production systems.
Read More
If you found this useful, I write about systems design, distributed patterns, and engineering craft at kallis.in. Come say hi.
Tags: #ai #redis #distributedsystems #architecture #agents

Top comments (2)
This is a solid breakdown of the transactional outbox pattern—especially for AI agents where consistency really matters.
One thing I’m curious about: how are you handling failure scenarios when Redis is temporarily unavailable? Are you persisting events in the DB and retrying via a worker, or relying purely on streams durability?
Also, would love to know your take on scaling this—at what point would you switch from Redis Streams to something like Kafka?
Overall, clean concept and very relevant for building reliable AI systems 👍