
Written by Kateryna Oliferchuk.
Originally published on June 2nd 2022.
Data is everywhere and everything is built around data nowadays. With so many options of data storage available, you can always find one that best suits your current use case and requirements. But, based on my previous experience, that’s easier said than done: the best fitting database is not actually always chosen, and even a great initial choice might not play out well over time.
To learn more about how to approach selecting the best fitting storage for a microservice in a structured and efficient way, I attended the talk Choose your database as if your life depends on it by Ovidiu Hutuleac at the AWS Summit 2022 Berlin. I’ve often had the experience in the past that decisions were made as outcomes of back-and-forth discussions in which arguments were not always backed up with concrete facts. And with so many different database types to choose from (key-value, graph, document, relational, time-series, in-memory, columnar), each with so many different vendor options, it is a difficult challenge indeed.
My main takeaway from the talk is to focus on one bounded context per time, list its requirements and constraints explicitly, and, finally, use the PIE theorem to choose the right data storage for it.
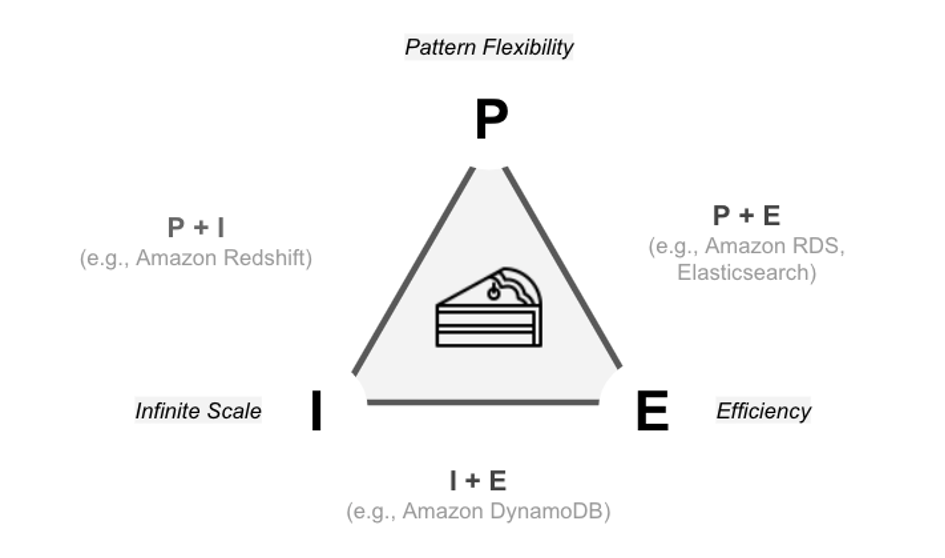
Similar to the CAP theorem, the PIE theorem states that we can choose two out of three desirable features in a data system: Pattern Flexibility, Efficiency, Infinite scale. The questions you need to answer while making a decision would be:
- Is there a need for flexibility in querying our data or do we only allow fixed access patterns?
- Is there a requirement for a consistent, predictable latency regardless of the number of clients and queries to the data store at the same time?
- How big and fast do we expect our data to grow?
Answering these questions will help you make your decision. I believe that investing time upfront to thoughtfully analyze the requirements and limitations will save you a lot of time in the future building workarounds.
The talk also left me with a new thought: Should database selection be treated the same as general software development? Meaning that we should start simple and stay agile and adjust over time. In my previous experience, we often took the initially chosen data store as set in stone. When new requirements came in, we tried to make the existing data store fit them instead of taking a step back and questioning whether the data store was still the right one. For example, in a past project we chose Elasticsearch as a primary data store because it perfectly fit the initial needs - a simple search use case. Over time, the scope increased, and more and more features were cumbersomely built using Elasticsearch, even though it was no longer the most suitable storage for us. Costs of operating the cluster became quite high and a lot of time was spent on improving performance. Looking back, I wish we had taken the time and paused to rethink our initial choice. We should remain open to changing the database completely.
To recap, choosing the right data storage for your system is an important choice to make carefully, and the PIE theorem will help you ask the right questions upfront. At the same time, you should always be open to challenge your initial decision over time, and re-iterate with the PIE theorem as your system and requirements evolve. You know, a PIE is always the answer 🍰.

Top comments (0)