
How to build high available/fault-tolerant services in node.js
During my job for an important client , I was thinking about high availability and recovery NFRs , our tech stack included cassandra and kafka , two distributed systems of which I studied internal behavior.
Kafka used Zookeeper to keep track of assigned partitions to each consumer , Cassandra had a gossip algorithm between nodes and divides data in partition ranges .
So I was starting to think if there was any library ( not an external service like zookeeper ) that had an algorithm with gossip implemented so that people could build some new distributed systems more easily.
That library does not exist , and then I created ring-election .
You can integrate ring-election into your node process and you will have some important NFRs already constructed !!!
What the ring-election driver offers you ?
- A default partitioner that for an object returns the partition to which it is assigned.
- Mechanism of leader election
- Failure detection between nodes.
- Assignment and rebalancing of partitions between nodes
- Automatic re-election of the leader
- Listen for new assigned/revoked partitions
What problems can you solve with this driver ?
- Scalability
- High availability
- Concurrency between nodes in a cluster
- Automatic failover
How it works under the hood
Terminology
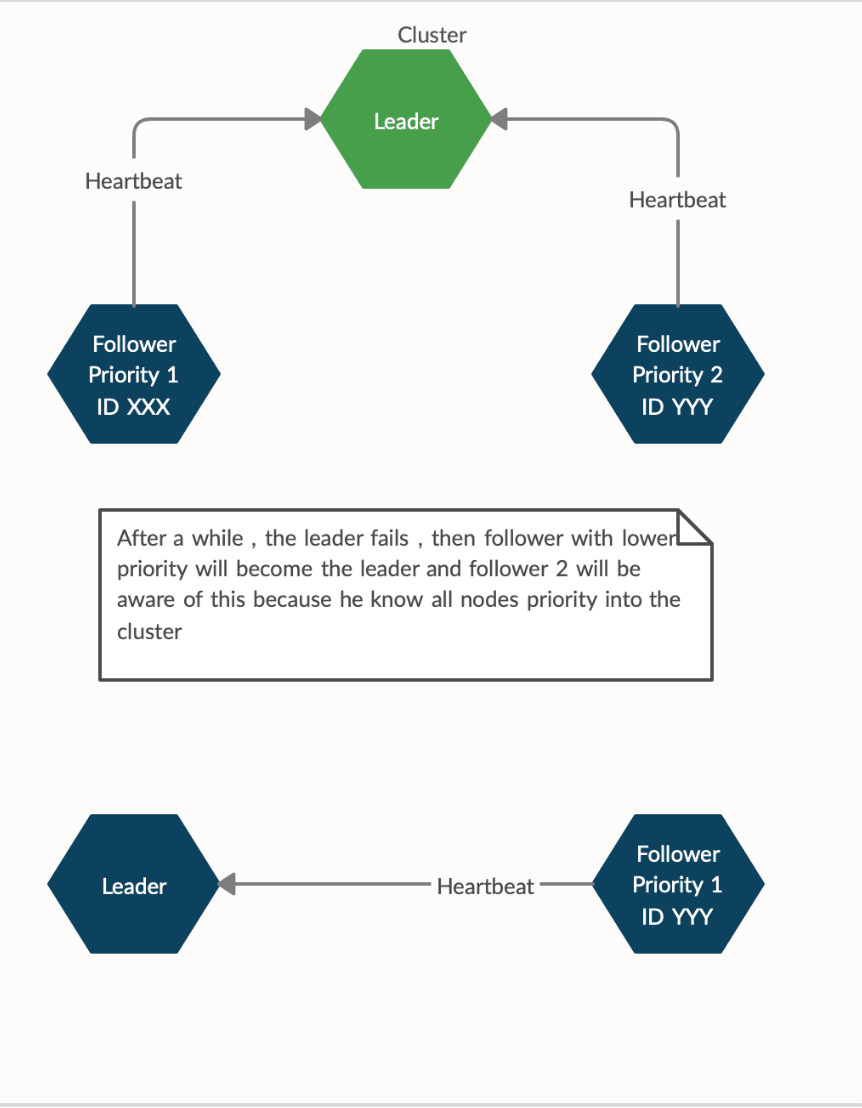
- Leader , the node that will handle the cluster and will not have assigned partitions
- Follower , a node that will have assigned partitions and will work on them
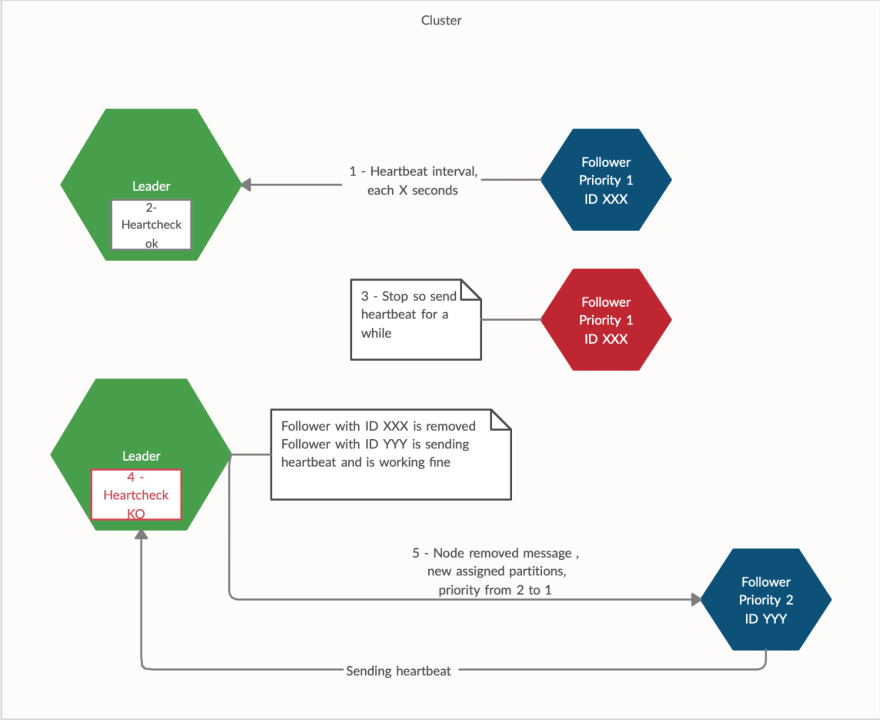
- Heartbeat , a message sent periodically from the followers to leader node to keep track that is alive.
- Heartcheck , a process that run on the leader and go to check the last heartbeat received by each follower
- Priority , is assigned to each follower based on the time that they joined the cluster , when a node die the priority is decreased by one . If the leader die the node with lower priority will become the leader
- Node id , each follower node has an assigned id that is unique into the cluster
Start up phase described

Detect follower failures ( Heartbeat/Heartcheck )
Leader Failure
How to integrate it ?
Join https://github.com/pioardi/ring-election to have more info .
If you want to suggest new features or you want help to integrate ring-election open an issue on github and I will be happy to help you.

Top comments (0)