
Memory management is one of the most important yet underestimated aspects of programming. Most developers focus on features and functionality, often neglecting this hidden foundation until problems arise. Poor memory management leads to programs that run slowly, crash without warning, or gradually consume more memory until they fail.
However, unlike other programming languages such as C, C++ and Java, where developers must allocate and deallocate memory explicitly, Python automates this process using Reference Counting and Garbage Collection.
In this article, we will discuss Python's memory management system in depth. We'll start with how Python organizes memory, then understand reference counting and its limitations, and finally discuss how garbage collection solves these problems.
Here's an overview:
- How Python organizes memory (stack memory and heap memory)
- Python's primary memory management: Reference counting
- Limitations of reference counting
- Python's garbage collection system
- Practical strategies for memory optimization
- Real-world applications and performance considerations
Before learning about how Python tracks and cleans up memory, it's essential to understand how memory is structured. Let's start with the fundamentals of how Python organizes memory.
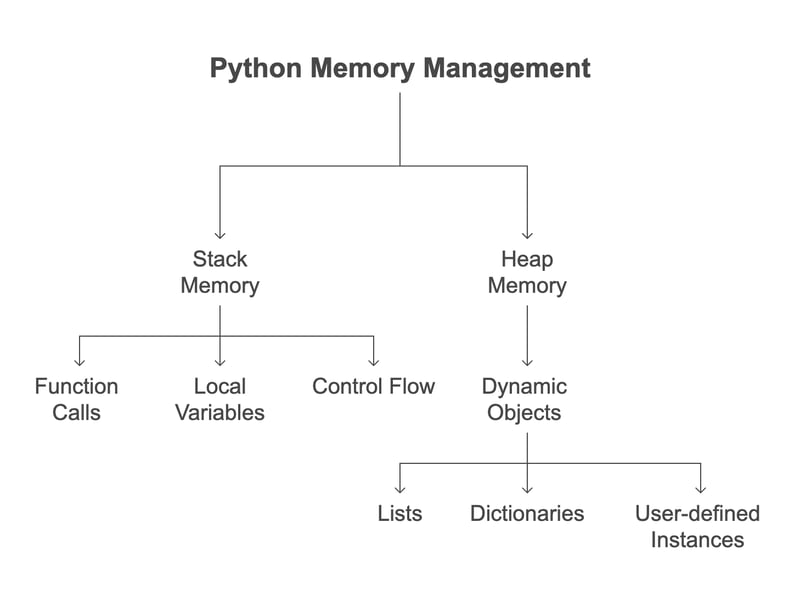
Memory Organization in Python
To handle memory allocation effectively, Python organizes memory into two main regions:
Stack Memory: This stores function calls, local variables, and control flow. It is automatically managed, with memory being allocated and freed as functions execute.
Heap Memory: This is used for dynamically allocated objects such as lists, dictionaries, and user-defined instances. These objects remain in memory until they are no longer needed.
Stack Memory
Stack memory handles function calls, local variables, and references to objects. Each time a function is called, a new stack frame is created, storing:
- Function arguments
- Local variables (names referencing objects)
- Control flow information
Once the function completes, the stack frame is discarded, and its references are removed.
For example:
def example():
x = [10, 20, 30] # 'x' is stored in stack memory
return x
result = example() # 'result' now references the returned list
Here, x exists in the stack memory during function execution, but the list [10, 20, 30] is created in heap memory. When the function returns, x is removed from the stack, but since result still references the list, it remains in heap memory.
Heap Memory
All dynamically allocated objects (lists, dictionaries, user-defined objects) are stored in heap memory. As long as references exist, these objects persist beyond function execution.
x = [5, 6, 7] # The list is created in heap memory
In this example:
The list [5, 6, 7] resides in heap memory and the name x is stored in stack memory and acts as a reference to the heap object
Now that we understand how memory is organized let's examine how Python keeps track of these heap objects by counting references.
Python's Primary Memory Management: Reference Counting
In many programming languages, such as C, C++, and Java, variables and objects are distinct - variables directly store values or memory addresses pointing to objects. However, in Python, variables are merely names (labels) that reference objects in memory rather than storing values themselves. Python uses reference counting to track how many names point to a given object, as multiple names can reference the same object.
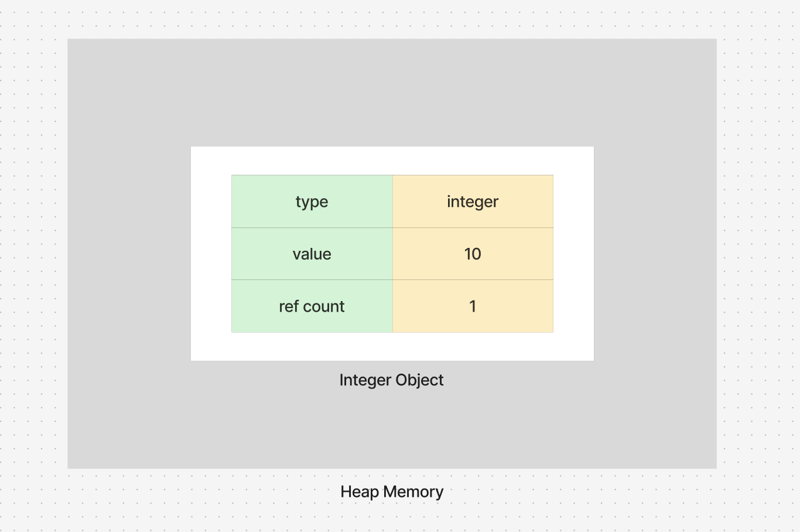
Each object in Python consists of three key attributes:
- Type: The object's data type is inferred automatically by Python
- Value: The actual data stored within the object
- Reference Count: The number of references (or names) pointing to the object.
Python provides a sys.getrefcount() function that can be used to check an object's reference count:
import sys
a = [1, 2, 3]
print(sys.getrefcount(a)) # Output: 2 (one for 'a', one for function argument)
The count is 2 because calling sys.getrefcount(a) temporarily creates another reference as a function argument.
The reference count increases each time a new reference is created and decreases every time a reference is deleted or reassigned.
For example:
a = [1, 2, 3] # Reference count: 1
b = a # Reference count: 2 (both 'a' and 'b' reference the same list)
a = None # Reference count: 1 (only 'b' references the list now)
del b # Reference count: 0 (no references left)
When an object's reference count drops to zero, Python automatically deallocates the memory, making it available for future use. This automatic cleanup is a significant advantage of Python's memory management system.
Advantages of Reference Counting
Reference counting offers several benefits as a memory management strategy:
Immediate Cleanup – When an object's reference count reaches zero, it is deallocated instantly, preventing excessive memory consumption.
Simplicity – The mechanism is straightforward and does not require complex background processes.
Deterministic Behavior – Since objects are freed as soon as they become unreferenced, we can predict when memory will be released.
However, despite these advantages, reference counting alone is insufficient for comprehensive memory management. Let's examine its limitations.
Limitations of Reference Counting
While reference counting efficiently handles most memory management scenarios, it has several significant limitations:
Performance Overhead: Incrementing and decrementing reference counts adds a small but constant performance cost, especially in large applications.
Not Thread-Safe: Reference counting can cause issues in multi-threaded programs due to potential race conditions.
Circular References: The biggest limitation is that objects referencing each other keep their reference count above zero, preventing automatic deallocation.
The problem of circular references deserves special attention.
Consider this example:
class Node:
def __init__(self):
self.ref = None
a = Node()
b = Node()
a.ref = b # 'a' references 'b'
b.ref = a # 'b' references 'a'
del a
del b # Objects still exist due to circular reference
In this code, even after deleting the variables a and b, the Node objects themselves continue to exist in memory because they reference each other, keeping their reference counts at 1 instead of 0. This creates a memory leak that reference counting alone cannot resolve.
Thus, the circular reference problem represents a fundamental limitation of reference counting that requires an additional mechanism to resolve. This is where Python's garbage collection system comes into play as a complementary solution to reference counting.
Python's Garbage Collection System
Garbage collection (GC) is Python's complementary memory management system that works alongside reference counting to clean up objects no longer in use, particularly those involved in circular references. It frees memory allocated to unused objects, preventing memory leaks.
Generational Garbage Collection
Python's GC follows a generational approach to optimize performance. The idea is that most objects have short lifespans, so collecting them frequently improves efficiency.
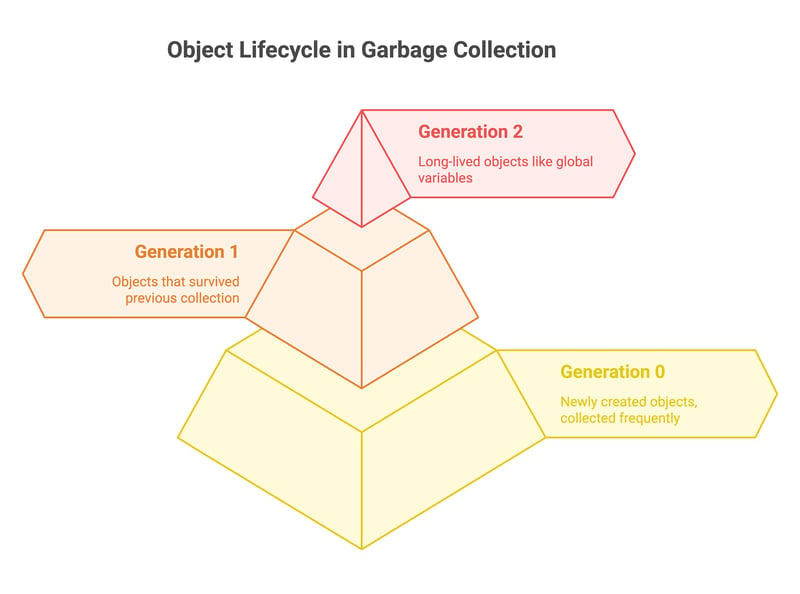
The garbage collector divides objects into three generations based on their age:
- Generation 0 (Youngest): Newly created objects. Collected most frequently.
- Generation 1 (Intermediate Age): Objects that survived a previous collection.
- Generation 2 (Oldest): Long-lived objects, such as global variables and cached data.
How Garbage Collection Works Step by Step
1. Starts with Generation 0 (Youngest Objects)
When garbage collection runs, it first checks Generation 0, which contains the newest objects.
Since short-lived objects (e.g., temporary variables in functions) are most likely to become garbage quickly, this step helps free memory efficiently.
2. Objects That Survive Are Promoted
If an object is still referenced after a collection, it is moved to the next generation (Generation 1) instead of being deleted.
This means Python assumes that if an object has survived one garbage collection, it might be needed for a longer period.
Similarly, objects in Generation 1 that survive another collection are promoted to Generation 2.
3. Generation 2 (Long-Lived Objects) Is Collected Least Often
Since objects in Generation 2 have already survived multiple collections, Python assumes they are important and unlikely to be garbage.
As a result, Generation 2 is collected the least frequently, reducing performance overhead.
Examples of such objects include module-level variables, global caches, and persistent data structures.

This incremental collection prevents unnecessary performance overhead while keeping memory usage efficient.
Detecting and Breaking Circular References
Python's garbage collector periodically scans memory to find objects that mutually reference each other but are no longer accessible from the rest of the program.
Here's how it works with our previous example:
import gc
class Node:
def __init__(self):
self.ref = None
a = Node()
b = Node()
a.ref = b
b.ref = a
del a
del b # Objects still exist due to circular reference
gc.collect() # Manually trigger garbage collection
Here, calling gc.collect() forces Python to scan for circular references. The garbage collector identifies that the two Node objects form a reference cycle that's no longer accessible from the program and removes them, freeing up memory.
When Does Garbage Collection Run?
Python's garbage collector automatically runs in the background based on a threshold system:
- A collection cycle is triggered if the number of object allocations exceeds a set limit.
- Developers can manually trigger garbage collection using
gc.collect(), though this is rarely needed. - The garbage collector can also be disabled with
gc.disable()if performance optimization is required in specific cases.
While reference counting handles most memory deallocation immediately, the garbage collector provides a safety net that catches circular references and other complex memory issues that reference counting cannot address.
Performance Considerations
While Python's GC system is generally efficient, frequent garbage collection cycles can cause minor performance slowdowns, especially in memory-intensive applications.
We can also fine-tune collection behavior using the gc module:
- Adjust thresholds using
gc.set_threshold(). - Monitor collection statistics with
gc.get_stats(). - Disable automatic collection in performance-critical sections and run it manually.
Now that we understand Python's memory management, let's look at practical strategies for optimizing memory usage in your applications.
Optimizing Memory Management in Python
While Python's garbage collection system handles memory cleanup automatically, unoptimized memory usage can lead to performance bottlenecks.
The following strategies help in managing memory more efficiently:
Avoiding Unnecessary Object Creation
Creating too many objects unnecessarily increases memory usage and strains Python's garbage collector. Using memory-efficient techniques, such as generators instead of lists, can significantly reduce memory consumption.
Example: Using Generators Instead of Lists
# List consumes memory for all elements at once
squares_list = [x * x for x in range(1000000)]
# Generator computes values on demand, reducing memory usage
squares_generator = (x * x for x in range(1000000))
Since generators yield values one at a time, they prevent storing large lists in memory, making them ideal for iterating over large datasets.
Handling Circular References Efficiently
Circular references occur when objects reference each other, preventing reference counts from reaching zero. While Python's cyclic garbage collector detects and cleans up these objects, using weak references can help break reference cycles and optimize memory usage.
Example: Using Weak References to Prevent Cycles
import weakref
class Example:
pass
obj = Example()
weak_ref = weakref.ref(obj) # Creates a weak reference instead of a strong one
Unlike normal references, weak references do not increase the reference count. Once an object has no strong references left, it is automatically garbage-collected, even if weak references point to it.
Disabling or Controlling Garbage Collection When Necessary
In high-performance applications (such as real-time systems or machine learning workloads), automatic garbage collection may cause performance overhead. Disabling it temporarily and running manual collections at controlled intervals can help.
Example: Disabling Garbage Collection
import gc
gc.disable() # Disable automatic garbage collection
# Perform high-performance operations...
gc.collect() # Manually trigger garbage collection when needed
gc.enable() # Re-enable automatic garbage collection
This approach is useful when frequent GC cycles disrupt performance-sensitive operations.
Monitoring Memory Usage
Tracking memory allocation helps identify leaks and optimize memory usage. Python provides tools like tracemalloc and objgraph to monitor memory usage effectively.
Example: Using tracemalloc to Track Memory Usage
import tracemalloc
tracemalloc.start()
# Code execution
print(tracemalloc.get_traced_memory()) # Shows current and peak memory usage
tracemalloc.stop()
By analyzing memory snapshots, developers can identify and optimise objects consuming excessive memory.
Real-World Applications
Understanding Python's memory management becomes particularly important in several scenarios:
Data Processing Applications
When working with large datasets, efficient memory management can be the difference between a functional application and one that crashes due to memory errors. Techniques like generators, chunking data, and processing in batches can significantly reduce the memory footprint.
Long-Running Services
Even small memory leaks can accumulate over time and cause failures for server applications and microservices that run continuously. Regular profiling and monitoring of memory usage help identify and fix these issues early.
Resource-Constrained Environments
In environments with limited memory (embedded systems, serverless functions with tight memory limits), understanding how Python manages memory allows developers to write more efficient code and avoid hitting resource limits.
Conclusion
Python's memory management system offers immediate cleanup through reference counting and comprehensive leak prevention through garbage collection. This dual approach ensures that memory is used efficiently with minimal manual intervention from developers.
However, relying solely on automatic memory management isn't always optimal. Understanding how Python handles memory allows us to write more efficient, high-performing applications.
By minimizing unnecessary object creation, using weak references, controlling garbage collection, and monitoring memory usage, we can prevent excessive memory consumption and improve application performance. Thoughtful memory management is not just about avoiding leaks but more about writing scalable, optimized code.
Next time when you debug a memory issue or optimize a Python application, remember how the underlying memory management works. These insights can help you make better design decisions and create more efficient software.

Top comments (1)
Great article!
Are there specific metrics or indicators you monitor to determine when manual garbage collection intervention is beneficial?
Additionally, in long-running applications, have you found adjusting thresholds with
gc.set_threshold()or manually invokinggc.collect()to be effective strategies?