Introduction
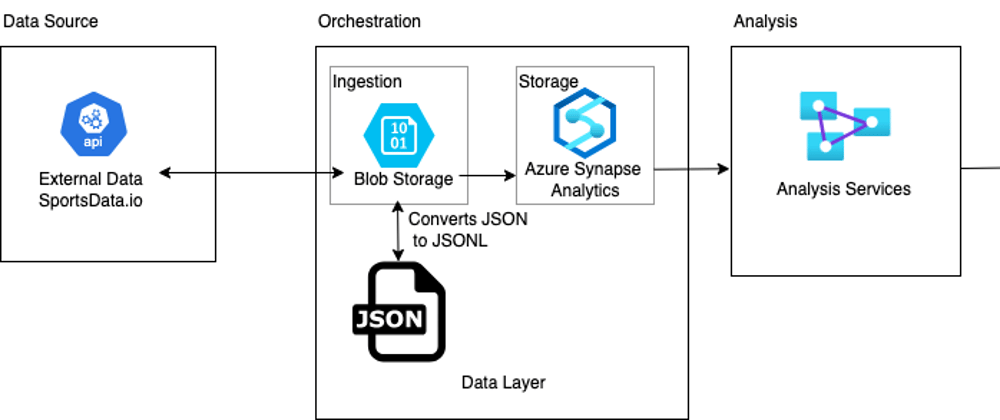
Data lakes are essential for modern data engineering, enabling efficient storage and processing of raw data. In this blog post, we will explore how to build an NBA Data Lake using Microsoft Azure, leveraging services such as Azure Blob Storage, Azure Synapse Analytics, and Python automation. We will also provide a detailed breakdown of each file in the repository, explaining its purpose and functionality.
Prerequisites
Ensure you have the following before running the scripts:
1️⃣ SportsData.io API Key
- Sign up at SportsData.io
- Select NBA as the API you want to use
- Copy your API key from the Developer Portal
2️⃣ Azure Account (Choose One)
3️⃣ Development Tools
Install VS Code with the following extensions:
- Azure CLI Tools
- Azure Tools
- Azure Resources
4️⃣ Install Azure SDK & Python Packages
Install Python (if not installed)
brew install python # macOS
sudo apt install python3 # Ubuntu/Debian
Ensure pip is installed
python3 -m ensurepip --default-pip
Install required Python packages
pip install azure-identity azure-mgmt-resource azure-mgmt-storage azure-mgmt-synapse azure-storage-blob python-dotenv requests
Project Overview
This project is designed to fetch NBA data from an API and store it in an Azure-based data lake. The data pipeline automates cloud resource provisioning, data ingestion, and storage management. The following technologies and services are utilized:
- Azure Blob Storage (for storing raw NBA data)
- Azure Synapse Analytics (for querying and analyzing data)
- Python (for scripting and automation)
Now, let’s dive into the repository structure and understand the role of each file.
Repository Structure & File Breakdown
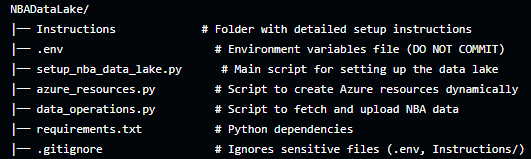
1. Instructions
This is the main documentation file that explains the project, how to set it up, and the key features of the repository. It includes:
- Overview of the project
- Installation and setup instructions
- Step-by-step usage guide
- Future enhancements and improvements
2. .env
This file holds sensitive environment variables, including:
- API keys
- Azure Subscription ID
- Storage Account Name
- Synapse Workspace Name
- Connection Strings
⚠️ Note: The .env file should be added to .gitignore to prevent accidental exposure of sensitive credentials.
3. setup_nba_data_lake.py
This is the main script that orchestrates the entire setup of the data lake. It performs the following tasks:
- Loads environment variables from .env
- Calls azure_resources.py to create Azure resources
- Calls data_operations.py to fetch and store NBA data
4. azure_resources.py
This script is responsible for dynamically creating the required Azure resources. It includes:
- Creating an Azure Storage Account: Required for storing raw data
- Creating a Blob Storage Container: Organizes the data files in a structured way
- Setting up an Azure Synapse Workspace: Enables querying and analyzing the stored data
5. data_operations.py
This script handles data ingestion and upload processes. It includes:
- Fetching data from the SportsData.io API
- Formatting the data into a JSONL file
- Uploading the file to Azure Blob Storage
6. requirements.txt
A list of Python dependencies required to run the project, including:
- azure-identity (for authentication)
- azure-mgmt-resource (for managing Azure resources)
- azure-storage-blob (for handling Blob Storage operations)
- requests (for making API calls)
- python-dotenv (for managing environment variables)
- Run the following command to install dependencies:
- pip install -r requirements.txt
7. .gitignore
This file ensures that sensitive files and unnecessary directories are not tracked in version control. It typically includes:
- .env (hides API keys and credentials)
- Instructions/ (prevents clutter from documentation files)
- pycache/ (ignores compiled Python files)
Workflow Summary
Step 1: Clone the Repository
git clone https://github.com/princemaxi/NBA_Datalake-Azure.git
cd NBA_Datalake-Azure
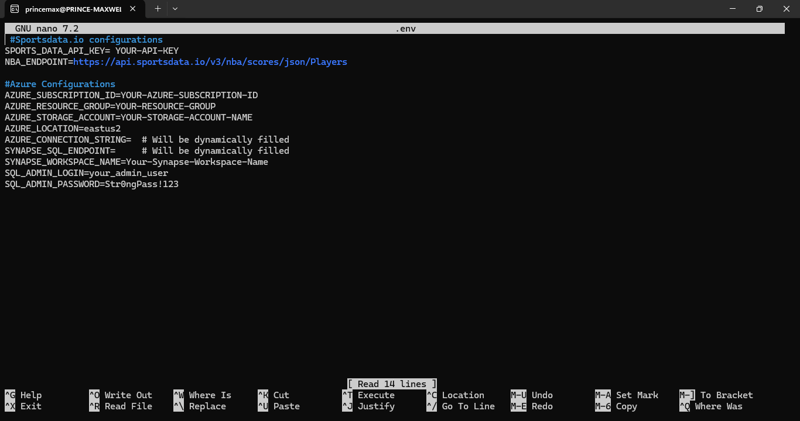
Step 2: Configure Environment Variables
Create a .env file and add your API keys and Azure details:
SPORTS_DATA_API_KEY=<your_api_key>
AZURE_SUBSCRIPTION_ID=<your_subscription_id>
AZURE_RESOURCE_GROUP=<unique_resource_group_name>
AZURE_STORAGE_ACCOUNT=<unique_storage_account_name>
AZURE_SYNAPSE_WORKSPACE=<unique_synapse_workspace_name>
Step 3: Install the requirements.txt file
pip install -r requirements.txt
Step 4: Run the Setup Script
python setup_nba_data_lake.py

Step 5: Verify Data Upload
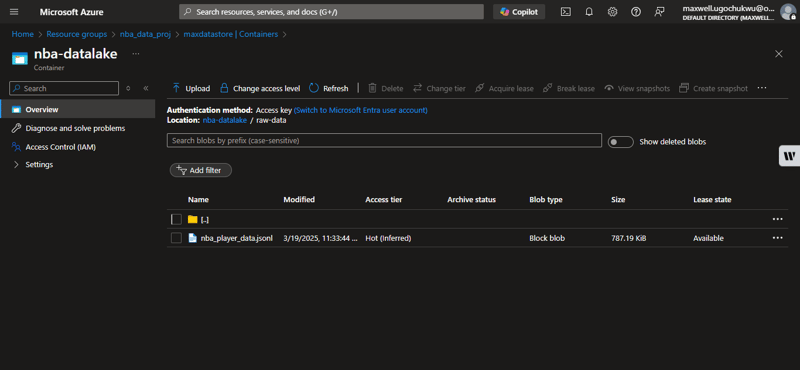
Using Azure Portal
- Navigate to your Azure Storage Account
- Go to Data Storage > Containers
- Confirm the file raw-data/nba_player_data.jsonl exists
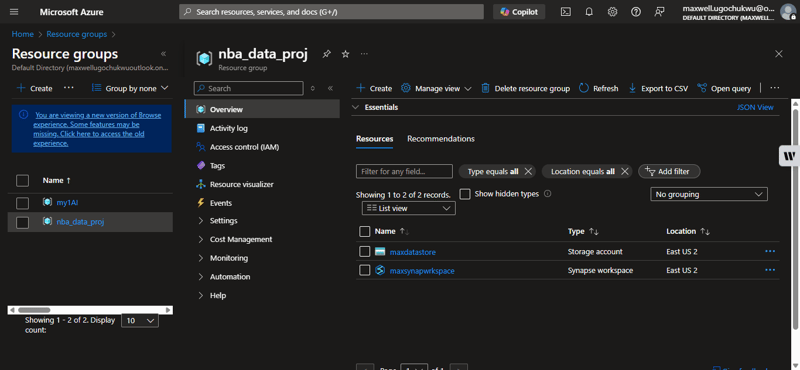
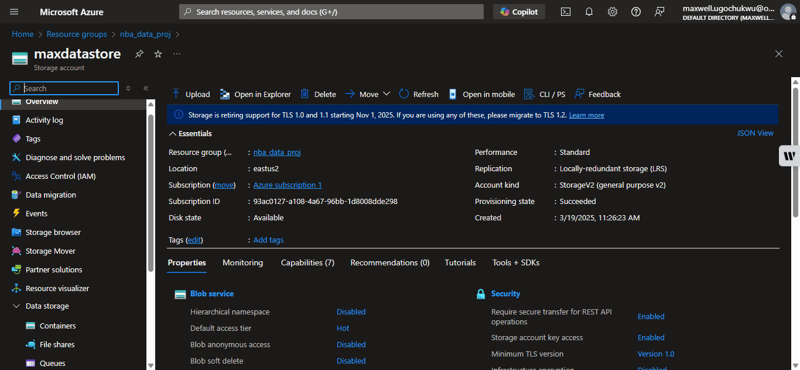
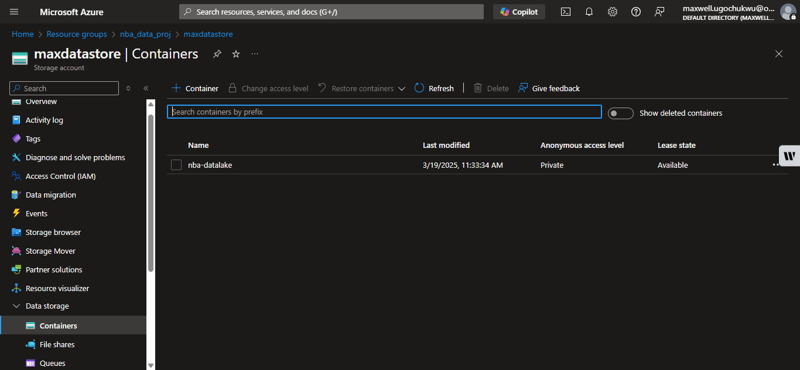
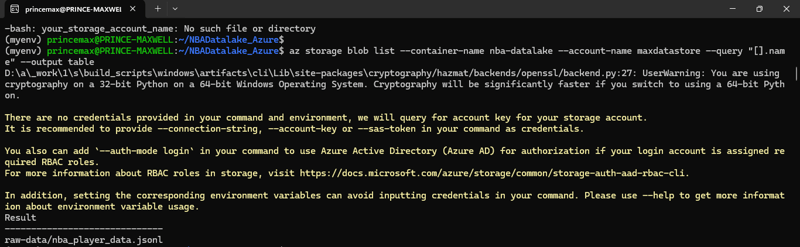
Using Azure CLI
List blobs in the container
az storage blob list \
--container-name nba-datalake \
--account-name $AZURE_STORAGE_ACCOUNT \
--query "[].name" --output table
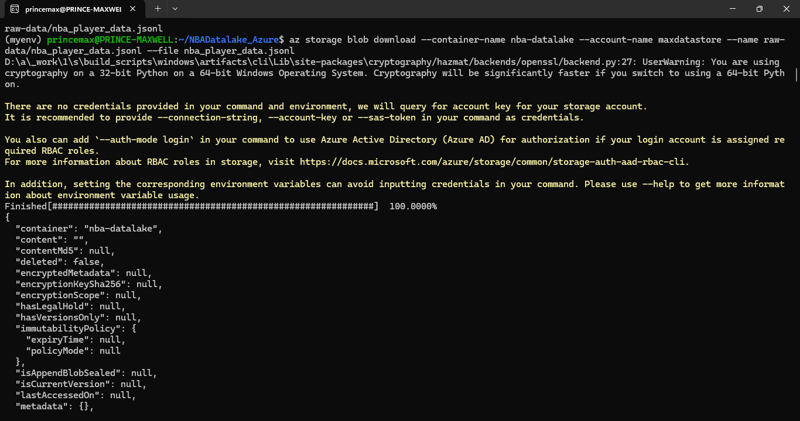
Download the file
az storage blob download \
--container-name nba-datalake \
--account-name $AZURE_STORAGE_ACCOUNT \
--name raw-data/nba_player_data.jsonl \
--file nba_player_data.jsonl
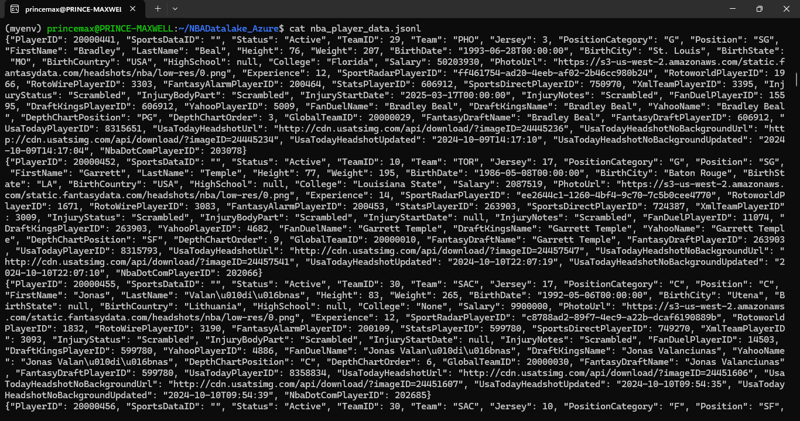
View the contents
cat nba_player_data.jsonl
Future Enhancements
🔹 Automate Data Refresh: Implement Azure Functions to schedule and automate data updates.
🔹 Stream Real-Time Data: Integrate Azure Event Hubs to process live NBA game stats.
🔹 Data Visualization: Use Power BI with Synapse Analytics to create interactive dashboards.
🔹 Secure Credentials: Store sensitive API keys in Azure Key Vault instead of .env files.
Conclusion
This project demonstrates how to build a fully functional data lake on Azure using Python automation. By following this structure, developers can efficiently manage and analyze NBA data while leveraging the scalability of cloud computing.

Top comments (0)