](https://media2.dev.to/dynamic/image/width=800%2Cheight=%2Cfit=scale-down%2Cgravity=auto%2Cformat=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2Fveuzfx2iulk2dtre09m2.png)
AI coding agents are getting better at editing code, but they still often start every session like they have never seen the repository before.
They read the README.
Then package files.
Then random source folders.
Then tests.
Then old notes.
Then maybe the same files again in the next session.
That repeated orientation is not only a token problem. It is a trust problem.
The agent does not know which summary is current, which module is stale, which files are risky, or which part of the repo should be checked before editing behavior.
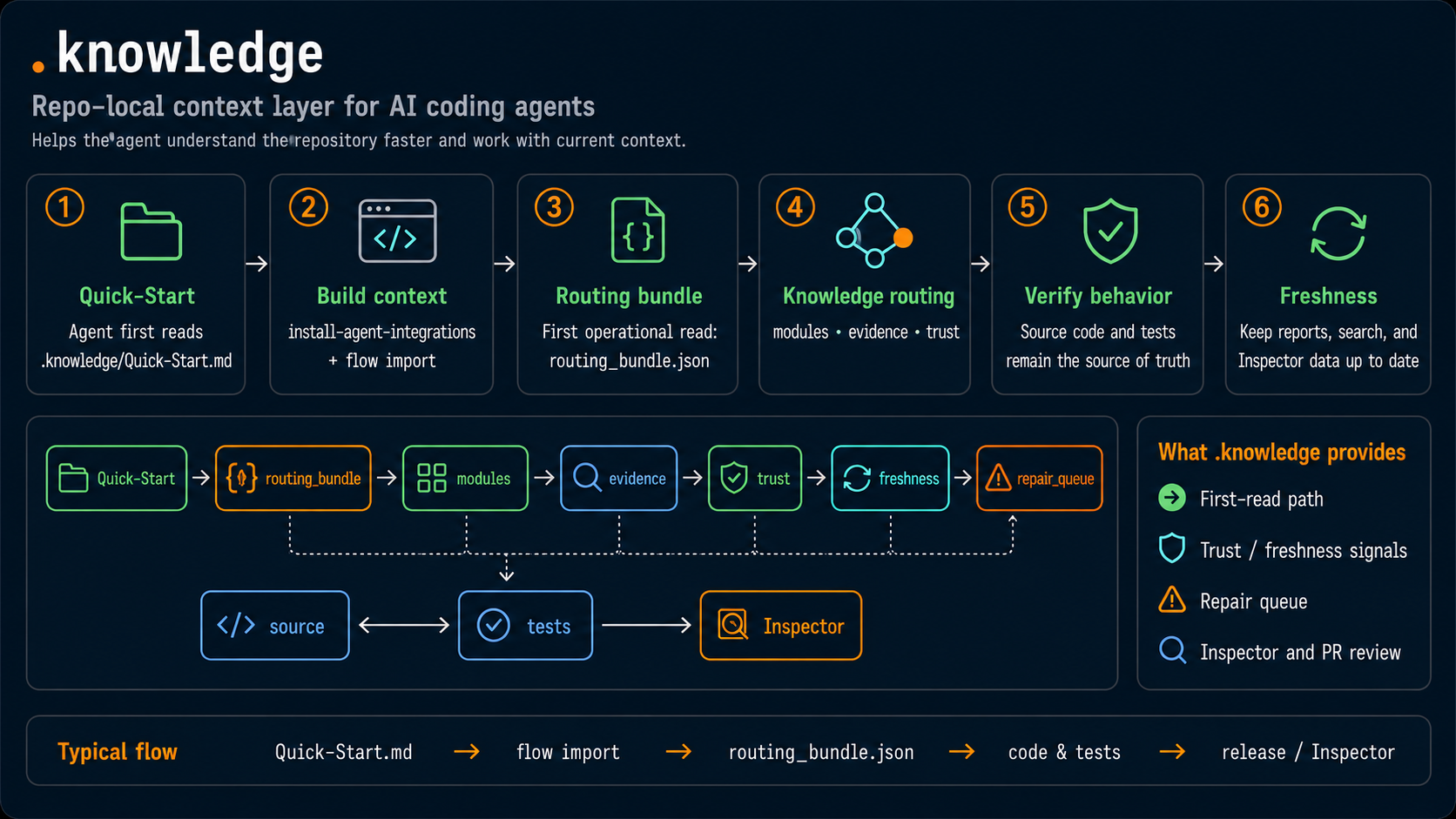
So I built .knowledge — an open-source, repo-local context layer for AI coding agents.
GitHub: https://github.com/pro2pilot/knowledge
What it does
.knowledge gives agents a local first-read path inside the repository:
.knowledge/Quick-Start.md
↓
.knowledge/maintenance/routing_bundle.json
↓
module cards / evidence / trust state / repair queue
↓
current source and tests
The point is not to make agents read less source code.
The point is to stop making them spend the first part of every session rediscovering the same project shape.
The core idea
A coding agent should not treat repo memory as magic.
It should have a clear source-of-truth order:
current source code
current tests
evidence
module cards
decisions
wiki
session notes
external memory
If the task touches auth, billing, runtime execution, queues, storage, secrets, migrations, security, concurrency, or anything stale/suspect/low-confidence, the agent must re-read source and tests.
.knowledge is a routing layer, not a replacement for code review.
What ships in the open core
The repository includes:
agent-integrations/ # Codex, Claude Code, OpenCode
docs/cookbook/ # operational recipes
github-action-templates/ # health, PR summary, evaluation
inspector/ # local static visual inspector
tools/ # scan, import, release, metrics
Quick-Start.md # first-read contract for agents
Some runtime artifacts are generated after setup, for example:
.knowledge/maintenance/routing_bundle.json
.knowledge/maintenance/trust_report.json
.knowledge/maintenance/repair_queue.json
.knowledge/search/index.json
.knowledge/inspector/index.html
That is intentional. A fresh public archive ships the framework, tools, templates, docs, and seed files. Your repo generates its own local state.
Example setup
node .knowledge/tools/install-agent-integrations.js
node .knowledge/tools/flow.js import
node .knowledge/tools/flow.js release --no-color
After that, the agent has a maintained first-read path instead of inventing a new onboarding route every session.
Why I made it
I do not think the problem is “agents need one more long prompt”.
The problem is that repo context is usually scattered across:
- chat history
- README sections
- stale architecture notes
- local scratch files
- hidden agent memory
- repeated repo crawls
That makes the workflow hard to review.
.knowledge keeps the context beside the code, where it can be versioned, inspected, refreshed, and challenged.
Who this is for
This is mainly for teams or solo builders already using coding agents such as Codex, Claude Code, OpenCode, or custom local agents.
It is probably overkill for very small repos.
It is more useful when:
- agents repeatedly re-read the same repo structure
- multiple agents touch the same codebase
- session handoff matters
- stale summaries cause wrong-file edits
- AI-assisted PRs need clearer impact boundaries
- you want local-first context without required cloud memory
What I would like feedback on
I am looking for feedback from people who already use coding agents in real repositories:
- Would you use a repo-local routing bundle as the agent’s first read?
- What would you want in a trust/freshness report?
- Would a local visual Inspector help your review workflow?
- Which agent workflows should be supported first: Codex, Claude Code, OpenCode, or something else?
GitHub repo: https://github.com/pro2pilot/knowledge
Technical notes: https://pro2pilot.com/knowledge/repo-local-knowledge-routing/
Product hub: https://pro2pilot.com/knowledge/

Top comments (0)