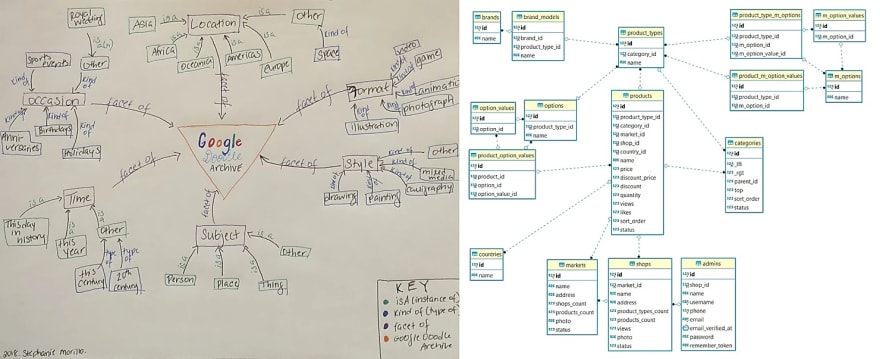
One of my assignments for Knowledge Organization Structures. The project was to redesign the Google Doodle Archive. We started by defining what the object “doodle” was, created attributes for that object, and explained the relationships between them. Right image: Database schema for an e-commerce site. Source: StackExchange
Introducing knowledge organization structures
My first interaction with a database was when I was learning web development with Rails. Six years after I ran rails new app in Terminal and tinkered with models for the first time, relational databases finally started making some sense to me. If you’ve messed with Rails before, you’re probably chuckling at this because Rails—in all its magic—is a terrible way to introduce someone to databases.
I finally understood relational database design in a class that had nothing to do with databases and everything to do with library science. The class was called “Knowledge Organization Structures”.
It was the most difficult—and theoretical—course I took in grad school, where I studied user experience design. Knowledge organization structures (KOS) is concerned with how information is organized, indexed, and classified. When thinking about KOS in terms of user experience, KOS can be used to build better navigation, browse, and search capabilities in order to improve the findability and discoverability of information on a site.
What are databases?
So what does that have to do with databases?
Databases are used to store information (or “data”). Data is organized and categorized in databases for storage and retrieval purposes; we index data with unique IDs, we label columns and tables, and we define relationships between tables and entire databases. These structures can be found in KOS—except they use terms like “facets”, “ontologies”, “taxonomies” and “hierarchical and flat structures” to define what objects are in a KOS context and how objects relate to one another. While I was learning how KOS could be used to build a website’s information architecture (front-end), it was imploring me to think about how information was organized on the back-end, too.
Databases employ models to determine the database’s structure and attributes. First, we define “objects” and their attributes. (For example, a database capturing customer information will list specific attributes that a customer—the object—possesses, like a customer_id, phone number, first name, last name, address, and so on.) These attributes have to apply to all possible instances of that object. Then, we do the same for other objects, and we figure out how these objects relate to one another, and how we reference these objects in different tables.
KOS helped me see this. I learned about different organization and classification schemes and the main use cases for each in a UX context. I learned how to employ “synonym rings” and “controlled vocabularies” to create—and label—categories. (The hardest problem in computer science, naming things, has been solved by librarians, y’all.) I saw how information stored in databases affected the client-side user experience. If you search for “database schema” images and “classification scheme” images, you’ll notice how much they look alike.
Consider the types of database models listed in Wikipedia’s database model article (left image below) and the KOS concepts listed in my class’s syllabus (right image below):

The words “hierarchical”, “semantic”, “graph”, and “network” appear in both. We even covered flat structures in an earlier module in class (not pictured above). And XML databases have a strong correlation with metadata.
In short, this class was revelatory.
Data played a huge part in my last role even though I have no background in data science. Our database was built with Airtable—our base had an impressive 20+ tables—and I was responsible for database administration and more. I was responsible for access management and database design, data modeling, data cleaning, and data analysis. I do not possess the same vocabulary as professionals from data fields, and I was not working under the tutelage of a data professional. I relied heavily on my knowledge of KOS and information architecture to help me undertake my data-related activities. My mental model of a database comes from library science, a field that is centuries old, and one which has produced a lot of research about how people think of information.
Since finishing grad school, I’ve occasionally looked at Masters and Ph.D. programs in Information Science. (Turns out I couldn’t wait to graduate—only to want to go back to school.) To my pleasant surprise, many iSchools (what many universities in the U.S. call their Library and Information Science departments) have Data Science programs or Data Science concentrations. It makes so much sense; modern databases are applications of KOS. The way database administrators and librarians approach data/information are different, and they use different terms for similar concepts. But the way we look at relationships, classification, and organization are not that different. It’s helped me think about data in a whole new way.
Resources:
- KOS Primer by Marcia Lei Zeng, PhD (Kent State University)
- Metadata Basics by Marcia Lei Zeng, PhD (Kent State University)
- The Pocket Data 101 List
This post was originally published on my blog.
I'm Stephanie, a Content Strategist and Technical PM. Visit developersguidetocontent.com to learn more about my work!

Top comments (0)