
What we'll look into
It is important to know different aspects of system designing in order to create a rigid system with characteristics such as availability, redundancy and scalability. Most of the topics discussed in this post are related to web applications.
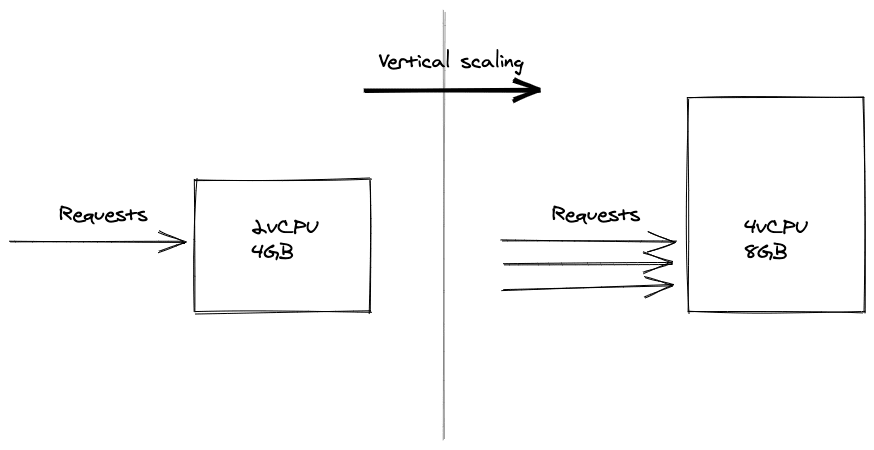
Vertical Scaling
Vertical scaling refers to adding resources to the underlying machine. Once the traffic to web site or application increases, the first instinct is to increase the amount of resource to add to the running machine. Adding more memory and CPU power usually copes with the performance requirements. However adding resources can be costly and at some point there will be a limit to adding resource continuously to cater the high amount of requests.
Horizontal Scaling
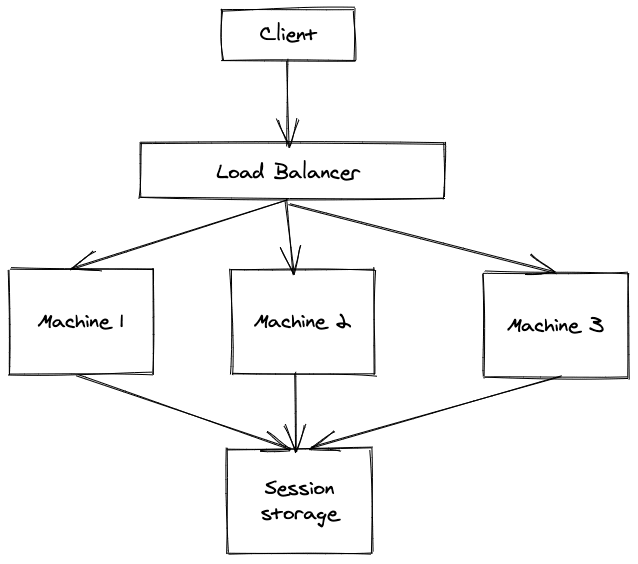
Horizontal scaling as the name implies is the opposite of vertical scaling, where more machines are added instead of adding more resources to a single machine. One of the advantages is the cost can be minimized if the cheaper machines are added compared to adding high cost resources as in the case of vertical scaling. With cloud computing adding more machines is quite easy with virtual machines or containers. However, if the server side code implemented sessions with a single server, these might get broken as many machines are added and user can be directed to different machines for different requests. To fix a common database can be introduced to store session data, but this adds a single point of failure.
Alternatively sticky sessions can be implemented. Sticky sessions make sure that the requests of a particular user gets directed to the same machine. This can be implemented in many different ways. A common method is to use cookies with the unique id of the server.
Once many machines are introduced, a load balancer has to be added to the design to redirect the requests to different machines.
Load balancer
Load balancer is responsible to sit in-front the multiple worker machines, and redirect the requests to the corresponding machine. The redirection is dependent upon the algorithm implemented. Round-robin algorithm is used for basic scenarios to distribute the requests evenly. However in cases where the requests must be redirected to a certain machine, different strategies such as sticky sessions with cookies might be used.

RAID
When a system makes use of separate box to store centralized data such as sessions, there would be risks such as single point of failure and not having a fault tolerant solution. To overcome this RAID (Redundant Array of Independent Disks) can be used as a strategy. RAID can solve different types of issues such as redundancy, fault tolerance, performance and data recovery. Depending on the requirement, a type of RAID level should be selected for the solution. This post explains few of the RAID levels with their pros and cons.
Caching
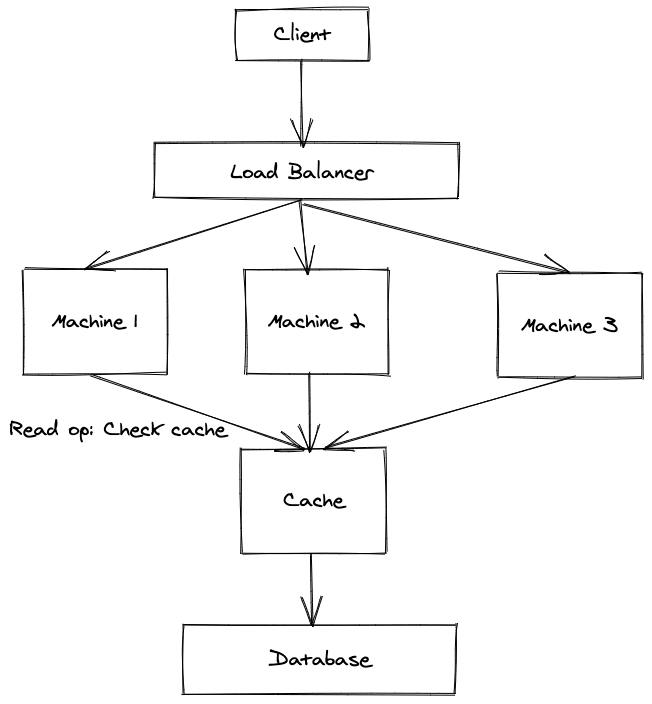
As we expand our solutions to to include databases, and eventually there will be bottlenecks with the queries specially if the application is read heavy. If the same query is made 100000 time to the databases, these round trips can cost some serious issues in terms of the performance. Thus caching comes into the picture. In the case of read heavy operations, the first step is to identify the bottlenecks. Once the read heavy queries are identified, a read-through cache can be applied. In this way before actually doing the query to the database, the cache is checked. If the cache contains the necessary record, it is returned and the query never makes the round trip to and from the database. Similarly there are many other caching mechanisms.
Cache servers
To implement caching there are different methodologies. Simply a custom in memory cache can be implemented based on the requirements. This can be done using in the same runtime context of the application itself, using the same programming language. However when the work-load increases, a caching server can be used. A caching server bundles many of the common features required by applications when integrating a cache such as invalidation, scaling, and fault tolerance. Redis, and memcached are few examples of widely used caching solutions.

Top comments (0)