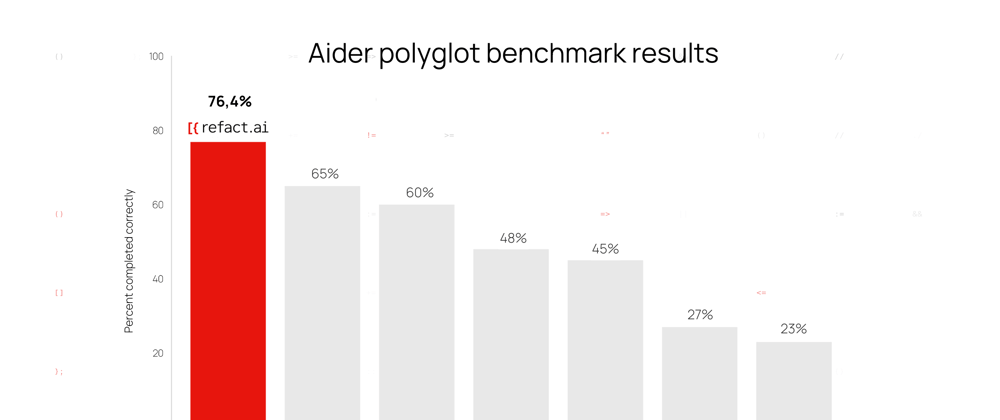
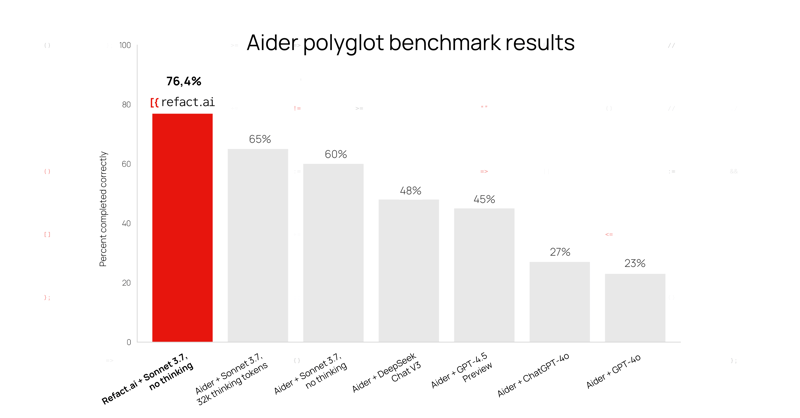
Refact.ai Agent, powered by Claude 3.7 Sonnet, has achieved an impressive 76.4% score on Aider’s polyglot benchmark — without thinking capabilities enabled.
This puts Refact.ai Agent at the top of the LLM leaderboard, surpassing Aider’s own score of 60.4% with the same model, as well as with DeepSeek Chat V3, GPT-4.5 Preview, ChatGPT-4o, and others.
The key is our iterative approach to solving programming tasks. In your IDE, Refact.ai doesn’t just generate code — it ensures it works by iterating until it achieves a successful result. This guarantees highly accurate, production-ready outcomes with minimal human intervention.
About Aider’s polyglot benchmark
The benchmark evaluates how well AI can handle real-world programming challenges across multiple languages. It consists of 225 of the hardest coding exercises from Exercism, covering C++, Go, Java, JavaScript, Python, and Rust.
Polyglot measures not only raw code generation, but also for reasoning, precision, and execution:
- Can AI write new code that integrates seamlessly into existing codebases?
- Can AI successfully apply all its changes to source files without human intervention?
The full test set in the Aider polyglot benchmark repo on GitHub.
Why Polyglot > SWE Bench
TL;DR: We at Refact.ai see Polyglot as a better choice for evaluating the real-world scenarios of AI agent application and determining their usefulness.
SWE Bench is popular and often seen as a key benchmark for AI coding agents. However, it has significant limitations:
- Only tests Python
- Relies on just 12 repositories (e.g., Django, SymPy)
- Benchmarked models are often pre-trained on these repos (skewing results)
- Only one file is changed per task (unrealistic for typical development work)
- Human-AI interaction is oversimplified (in reality, devs adjust how they collaborate with AI).
Because of these constraints, SWE Bench doesn’t truly measure an AI agent’s efficiency in software engineering workflows, not in a controlled environment.
In contrast, Polyglot is much more representative and realistic — it imitates the environments developers work in every day and reflects actual needs. It measures how well AI can autonomously interact with diverse, multi-language projects.
So, we’d like to thank Aider for introducing this comprehensive benchmark! It provides great insights into AI coding tools and helps drive better solutions.
Our approach: How Refact.ai achieved #1 in the leaderboard
Many AI Agents rely on a single-shot approach — get a task, generate code once and hope for the best. But LLMs aren’t all-knowing — they have limits and make mistakes, so their first attempt often isn’t accurate and reliable.
Sure, you can pre-train models to ace specific tasks that trend on X… But what’s the point? This doesn’t translate to real-world performance.
At Refact.ai, we do things differently. Our AI Agent uses a multi-step process: instead of settling for the first attempt, it validates its work through testing and iteration until the task is done right.
We call it a feedback loop:
- Writes code: The agent generates code based on the task description.
- Fixes errors: Runs automated checks for issues.
- Iterates: If problems are found, the agent corrects the code, fixes bugs, and re-tests until the task is successfully completed.
- Delivers the result, which will be correct most of the time!
This drives the real value of AI — actually solving problems, not just scoring well on benchmarks.
Read more about the tech side in our blog.
Key features of Refact.ai’s autonomous AI Agent
Refact.ai’s advanced AI Agent thinks and acts like a developer, handling software engineering tasks end-to-end.
- Autonomous task execution: Breaks tasks into steps, plans solutions, executes, and deploys code — all with minimal human input.
- Deep contextual understanding: Analyzes your entire environment, generating highly accurate and relevant code.
- Tool integration: Connects with essential dev tools like GitHub, Docker, PostgreSQL, MCP Servers, autonomously interacting with them for completing tasks.
- Memory and continuous improvement: Learns from every interaction, becoming better over time.
- Human-AI collaboration: When faced with obstacles, the Agent can self-correct, and if it requires human input, it natively hands control back to the user.
- Open source: Fully transparent and verifiable for trust.
Get Refact.ai for your IDE
Vibe coding is the future of software development: get 10x productivity with Refact.ai Agent by your side. It works like a senior developer in your IDE:
🚀 Works inside your workflow & with your dev tools
📈 Boosts productivity x10 with real automation
🛠 Handles coding while you focus on core work
✅ Available to everyone in VS Code and JetBrains.
We'd be happy if you test Refact.ai Agent for your software developmebnt tasks and share you opinion!

Top comments (0)