
Freshworks’ IT service management tool, Freshservice, enables organizations to simplify their IT operations. Freshservice provides ITIL-ready components that help administrators manage incidents, problems, changes and releases, and the asset management component helps organizations exercise control over their IT assets.
What happens when your application’s core S3 bucket is marked as dangerous by Google’s safe browsing feature and your web application is displayed as suspicious when accessed on Chrome/Firefox? We will talk about how we reacted to a similar incident that happened with us, and how we reduced the impact it had on our customers. We will also delve into design changes made to further reduce the impact of such events in the future.
Default Attachment Processing
Freshservice is powered by Ruby on Rails. Nginx passenger-backed servers are hosted on the EC2 instances of AWS. The servers are hosted in four AWS data centers — US East (US), Europe Central (EUC), India (IND), and Australia (AU).
Freshservice uses AWS’s S3 (Simple Storage Service) for file storage. S3 + paperclip forms the crux of our attachment storage and processing engine. Customers use this service for various purposes like uploading their logo or favicon for branding, enabling their end users upload avatars, attaching supporting files or images on tickets, uploading the signed contract in the contracts module, etc. Upon upload, the files are scanned for viruses and uploaded to a unique path in our S3 bucket. To ensure our customers’ data is never lost, we also have a DR (Disaster Recovery) setup in place**. The attachments bucket is replicated in near real-time to another bucket in a different region within the same geography.
Attachments are protected by a set of standard security measures. The first check, for example, is tenancy — customers can only access their own attachments. Attachments are always fetched using pre-signed URLs that expire within a short interval, typically 5 minutes, but this interval may vary on a per use-case basis. The URLs generated are of the format:
https://s3.amazonaws.com/bucket_name/path_to_file.extension?signature.
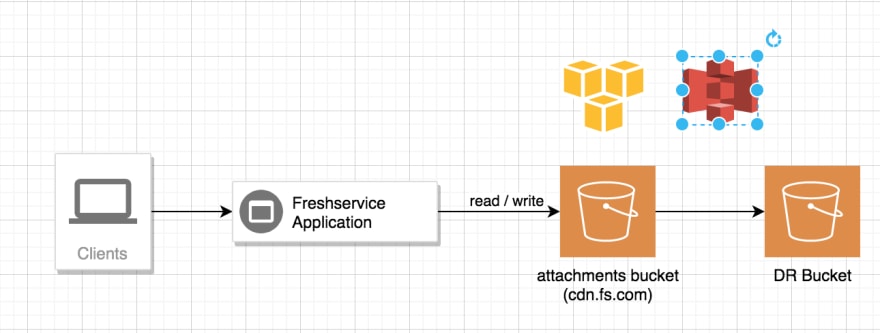
AU and IND regions currently do not have a secondary region for us to have a DR setup. US and EUC have a DR setup in place.
The Unexpected service outage
To ensure secure browsing for its users on the internet, Google safe browsing scans websites for dangerous & deceptive content. When a site is found to be in breach of its guidelines, they are marked unsafe by Google Safe Browsing. A security warning is then displayed on browsers when a user tries to visit the site in question.
Sometime in the middle of January 2020, Google Safe Browsing decided to mark our attachments bucket’s root URL ( https://s3.amazonaws.com/bucket_name ) as unsafe. This rendered the web application unusable as most pages included some form of attachment on the page. This affected all our customers hosted in that region.

First Response
As a first line of defense, to ensure customers are able to login into the system and use it, we temporarily disabled attachment-backed branding like logo and favicon. We also disabled loading user avatars to ensure customers are able to view and process at least the tickets that did not carry any attachments. Unfortunately, a vast majority of tickets had attachments and there was no easy way to support them.
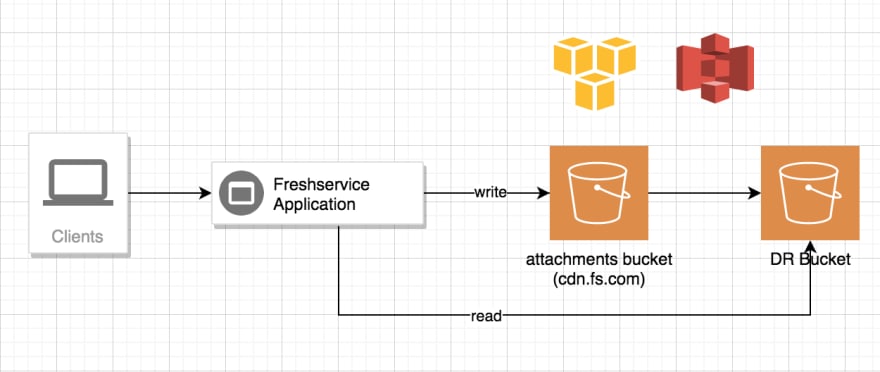
We considered creating a new bucket where all new attachments would be uploaded while syncing older attachment data into this new bucket using S3 sync. This turned out to be a non-starter due to the size of our bucket, as the sync would end up taking days if not weeks. This would be unacceptable for us as our customers would be unable to support their end users without essential information like screen shares or contract documents while the sync completes. We therefore decided to use our DR bucket which was already in sync with the original bucket. The challenge was that the DR bucket was hosted in a different region and accessing it across two AWS regions would introduce an additional network latency overhead to both read and write operations. We were, therefore, uncomfortable going all in with this as our new bucket. Instead, we decided to move the reads alone to the DR bucket, temporarily, until Google addressed the blocking of our bucket caused by false positives in their system.
We quickly prepared code changes to start reading from the DR bucket and deployed them. We also reverted all the previously made temporary changes related to customer branding and user avatars. The application was now fully in use.
After multiple attempts in reaching out to Google to sort the problem from their end, we finally had some luck and were able to get them to mark the bucket URLs as safe. They even guaranteed that this wouldn’t happen in the future.
But we were skeptical enough to decide we did not want to rely on this guarantee. We decided to keep the fallback available in production so we could easily switch back if we were blocked inadvertently again. To achieve this, we moved the "reads-from-dr" logic under a flag stored in Redis. To avoid hitting Redis for each request, we wrapped this around MemoizeUntil with 1-minute refreshes. This would make us future-proof if such an event reoccurred. All we would need to do is to flip the flag in Redis to fall back to reading from the DR bucket.

Second incident
Cut forward to the middle of April 2020 and Google marked the bucket as insecure once again. This time though, we could control the impact duration by toggling the flag in redis and customers were able to access their portal shortly after the problem was detected. We also realised that although this solution worked, there were a few issues, notably:
- We support both inline and regular attachments. Regular attachments can afford to have delays in loading as they are not expected to appear immediately. But inline attachments have to appear realtime. The "read-from-dr" solution that we had was "near-real time", not real time. Customers on faster networks would have noticed broken image uploads when, actually, the upload was successful in the backend. This is because the time taken to process and respond to the upload request would be shorter than the S3 sync. Hence the image would not be found when read from the DR bucket right after it was uploaded.
- If there happened to be a delay in S3 sync during this period, we would be caught completely off guard and wouldn’t have an alternative solution in place. This would make us too dependent on AWS than we would like to.
The Final Solution
At first, we considered building a reverse proxy solution as a gateway barrier for our S3 accesses. This proxy would be responsible for maintaining all our secure access processes while also reducing the blast radius in case of future incidents. We wanted to host our proxy under attachments.freshservice.com. With our sharded multi-tenant architecture, which serves each tenant under a unique subdomain on our root freshservice.com domain, this isolation would be rather straightforward. Each tenant would have its own subdomain, similar to their existing freshservice subdomain. for attachment processing under the root proxy URL — attachment.freshservice.com
This approach would solve all our problems but add another piece of infrastructure requiring additional provisioning, maintenance and monitoring. We were reluctant to add more infrastructure overhead for this problem and were looking for a readily available service that would solve this for us. That’s when we came across AWS Cloudfront’s signed private access feature. Secure access of attachments through pre-signed auto-expiring URLs was a core design principle in our current setup, giving security the highest priority. The signed private access feature from AWS Cloudfront allowed us to retain that design principle while giving us the leisure of not having to maintain another infrastructure component. We were immediately convinced and decided to go ahead with Cloudfront + S3 as our attachments service provider. We used trusted signers as our default signing strategy for generating signed private URLs. The new URL format for CDN enabled accesses would look like:
https://subdomain.attachments.freshservice.com/path_to_file.extension?signature.
However, with data localisation clauses from different governments, we could not leverage the default features of a CDN like cloudfront. Hence, we had to disable both default and edge caching on the distribution so that the customer’s data would reside in the same region as that of the origin. We can do this by setting minimum, maximum and default TTL to 0.

This would, however, lead to exorbitant CDN access costs. Moreover, we also noticed that during both the aforementioned incidents, there were some suspicious sign ups misusing freshservice for spamming. Google never gave us a valid reason for marking the site as unsafe in both the cases. They just mentioned that this would not happen in the future and that their algorithms were learning and getting better.
Hence, as a caution and to keep costs in check, we came up with a unique strategy to enable the "CDN+S3" approach only for suspicious-looking accounts while keeping the remaining accounts on the default S3 accesses. An account is deemed suspicious depending on various anti-spam measures that we have. Depending on the spam score of an account, its attachments will be served from either S3 directly or through CDN + S3. This is internally controlled via feature flags. We also kept default switches to both disable or enable CDN accesses at application level as well.
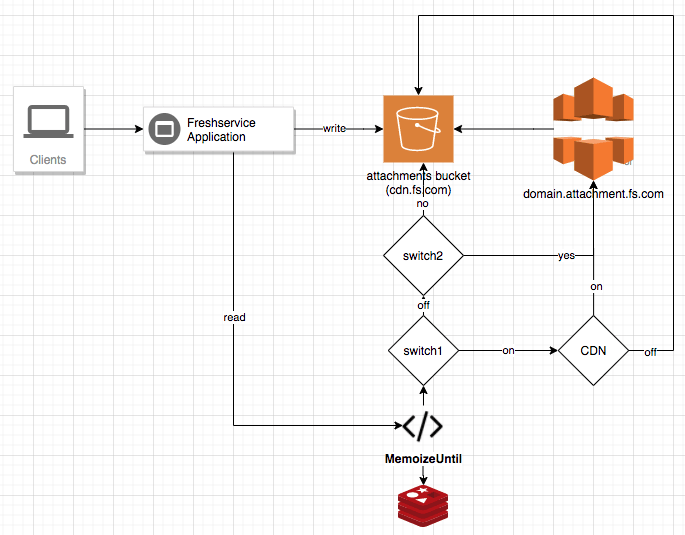
This would enable us to control the blast radius to each tenant and ensure we are able to serve our customers without any service interruptions.
Incidents like these, unavoidable to a certain extent, help us display our truly customer-first values that are ingrained in every individual within the organisation. After ensuring that the customers could resume their operations, we did what we do best — make informed engineering decisions to ensure that our customers do not get impacted again in future.
(This post was co-authored by Valarpiraichandran A)

Top comments (0)