EDIT :- For calculus go through my post on matrix calculus.
There are many reasons why mathematics is important for machine learning. Some of them are below:
- Selecting the right algorithm which includes giving considerations to accuracy, training time, model complexity, number of parameters and number of features.
- Choosing parameter settings and validation strategies.
- Identifying underfitting and overfitting by understanding the Bias-Variance tradeoff.
- Estimating the right confidence interval and uncertainty.

What are the best resources for learning?

I have tried to summarized mathematics taught in above both resources. So lets begin!
Scalars, Vectors, Matrices and Tensors :
- *Scalars * : A scalar is just a single number.
- *Vectors * : A vector is an array of numbers. The numbers are arranged in order. We can identify each individual number by its index in that ordering. x=[x1 x2 x3 …. xn]. We can think of vectors as identifying points in space, with each element giving the coordinate along a different axis. Sometimes we need to index a set of elements of a vector. In this case, we define a set containing the indices and write the set as a subscript. For example, to access x1, x3 and x6 we define the set S ={1,3,6} and write xs.
- *Matrices * : A matrix is a 2-D array of numbers, so each element is identified by two indices instead of just one.

The transpose of a matrix is the mirror image of the matrix across a diagonal line, called the main diagonal, running down and to the right, starting from its upper left corner.

We can add matrices to each other, as long as they have the same shape, just by adding their corresponding elements: C = A + B where Ci,j = Ai,j+ Bi,j.
We allow the addition of matrix and a vector, yielding another matrix: C=A+b, where Ci,j = Ai,j +bj. In other words, the vector b is added to each row of the matrix. This shorthand eliminates the need to define a matrix with b copied into each row before doing the addition. This implicit copying of b to many locations is called broadcasting.
- Tensors : An array of numbers arranged on a regular grid with a variable number of axes is known as a tensor.
Multiplying Matrices and Vectors:
The matrix product of matrices A and B is a third matrix C. In order for this product to be defined, A must have the same number of columns as B has rows. If A is of shape m × n and B is of shape n × p, then C is of shape m × p.
The product operation is defined by

The matrix multiplication is distributive, associative but not commutative (the condition AB =BA does not always hold), unlike scalar multiplication.
For learning more you can go through this course offered by MIT Courseware (Prof. Gilbert Strang).
Probability Theory:
Probability theory is a mathematical framework for representing uncertain statements. It provides a means of quantifying uncertainty as well as axioms for deriving new uncertain statements.
Let us understand some of the terminologies used in probability theory:-
- *Random Variables * : A random variable is a variable that can take on different values randomly. They may be continuous or discrete. A discrete random variable is one that has a finite or countably infinite number of states. A continuous random variable is associated with a real value.
- Probability Distributions : A probability distribution is a description of how likely a random variable or set of random variables is to take on each of its possible states. probability distribution over discrete variables may be described using a probability mass function (PMF) denoted by P(x). When working with continuous random variables, we describe probability distributions using a probability density function (PDF) denoted by p(x). A probability density function p(x) does not give the probability of a specific state directly; instead the probability of landing inside an infinitesimal region with volume δx is given by p(x)δx.
- Conditional Probability : In many cases, we are interested in the probability of some event, given that some other event has happened. This is called a conditional probability. We denote the conditional probability that y = y given x = x as P(y=y | x=x).

- The Chain Rule of Conditional Probabilities : Any joint probability distribution over many random variables may be decomposed into conditional distributions over only one variable
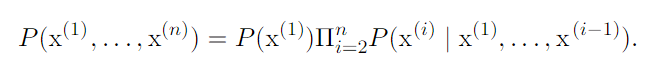
- Expectation : The expectation, or expected value, of some function f(x) with respect to a probability distribution P(x) is the average, or mean value, that f takes on when x is drawn from P.

- Variance : The variance gives a measure of how much the values of a function of a random variable x vary as we sample different values of x from its probability distribution.

- The square root of the variance is known as the standard deviation.
- Covariance : The covariance gives some sense of how much two values are linearly related to each other, as well as the scale of these variables:

High absolute values of the covariance means that the values change very much and are both far from their respective means at the same time. If the sign of the covariance is positive, then both variables tend to take on relatively high values simultaneously. If the sign of the covariance is negative, then one variable tends to take on a relatively high value at the times that the other takes on a relatively low value and vice versa.
- Bayes’ Rule : Bayes’ theorem is a formula that describes how to update the probabilities of hypotheses when given evidence. It follows simply from the axioms of conditional probability, but can be used to powerfully reason about a wide range of problems involving belief updates. We often find ourselves in a situation where we know P(y | x) and need to know P(x | y). Fortunately, if we also know P(x), we can compute the desired quantity

Common Probability Distributions:-
Some of the common probability distributions used in machine learning are as follows
- Bernoulli Distribution : It is a distribution over a single binary random variable. It is controlled by a single parameter φ ∈ [0,1], which gives the probability of the random variable being equal to 1.

- Multinoulli Distribution : The multinoulli, or categorical,distribution is a distribution over a single discrete variable with k different states, where k is finite. Multinoulli distributions are often used to refer to distributions over categories of objects.
- Gaussian Distribution : The most commonly used distribution over real numbers is the normal distribution, also known as the Gaussian distribution.

- The two parameters µ ∈ R and σ ∈ (0, ∞) control the normal distribution. The parameter µ gives the coordinate of the central peak. This is also the mean of the distribution : E[x] =µ. The standard deviation of the distribution is given by σ, and the variance by σ².
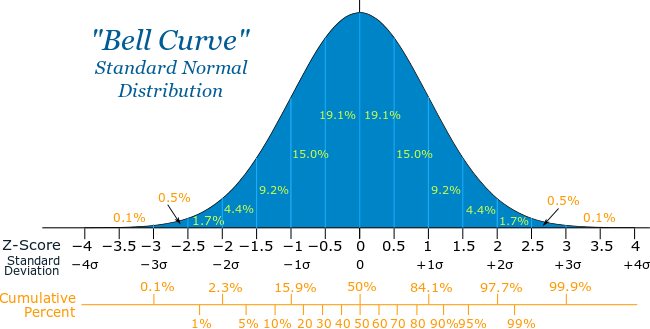
Khan Academy has got a very good course for statistics and probability.
Statistics and Probability | Khan Academy
I will wrap here. Hope this post helps you in revising some concepts which you learned in high school. 😄 Thank You for reading!

You can find me on Twitter @Rohitpatil5, or connect with me on LinkedIn.

Top comments (2)
While the bottom up approach to ML has its charm. Its hard to get to great results by trial an error that way.
So after Ng I suggest the fast.ai deep learning course which uses a top down approach. Much more practical if you actually want to get something meaningful done.
I agree.