
¿Que es LightGBM?
GBM = Gradient Boosted Machines
Es un framework que usa algoritmos basados en arboles con la eficiencia como objetivo principal.
Puede ser utilizado tanto para clasificación como para regresión (mas info en el parámetro objective).
¿Cómo funciona?
A diferencia de XGBoost (entre otros) que utiliza algoritmos basados en la clasificación previa, LightGBM usa algoritmos basados en histogramas (es decir, que agrupa los valores de atributos continuos en bins discretos) para agilizar el entrenamiento y reducir el uso de memoria.
Ademas, esta optimizado para que el arbol crezca en la dirección de los mejores nodos (ayudando a una mejor administración de memoria).

(algunos) Parámetros
LightGBM tiene más de 100 parámetros, pero aquí haré un resumen de los más importantes:
max_depth: Este parámetro previene que los arboles crezcan muy profundo. Los arboles poco profundos tienen menos probabilidad de overfitting. Configurar este parámetro es muy importante si el dataset es pequeño.
num_leaves: Controla la complejidad del modelo. El valor debe ser menor a 2^
max_depthpara prevenir overfitting. Si se lo ajusta con un valor grande puede aumentar la precisión a riesgo de aumentar el overfitting.min_data_in_leaf: Configurar este parámetro con un valor grande puede ayudar a prevenir que los arboles crezcan demasiado profundo. Este es otro parámetro que ayuda a controlar el overfitting del modelo. Si es un valor demasiado grande puede provocar underfitting.
max_bin: como ya vimos, LightGBM agrupa los valores de atributos continuos en bins discretos usando histogramas. Configura
max_binpara especificar el numero de bins en los que los valores pueden ser agrupados. Un valor bajo puede ayudar a controlar el overfitting y a mejorar la velocidad del entrenamiento, mientras que un valor grande mejora la precisión del modelo.feature_fraction: Este parámetro habilita el submuestreo de atributos.
feature_fractionespecifica las fracciones de los atributos que se seleccionaran aleatoriamente en cada iteración. Por ejemplo,feature_fraction = .75seleccionará al azar el 75 % de los atributos en cada iteración. Configurar este parámetro puede aumentar la velocidad de entrenamiento y ayuda a prevenir el overfitting.bagging_fraction:
bagging_fractionespecifica las fracciones de los datos que se seleccionaran aleatoriamente en cada iteración. Por ejemplo,bagging_fraction = .75seleccionará al azar el 75 % de los datos en cada iteración. Configurar este parámetro puede aumentar la velocidad de entrenamiento y ayuda a prevenir el overfitting.num_iteration: Fija el número de iteraciones de boosting. El valor predeterminado es 100. Para clasificación multi-clase, LightGBM crea
num_class*num_iterationarboles. Configurar este parámetro influencia en la velocidad de entrenamiento.objective: Como en XGBoost, LightGBM soporta multiples objetivos. El objetivo predeterminado esta configurado en regresión. Ajusta este parametro para especificar el tipo de tarea que tu modelo quiere llevar a cabo. Para tareas de regresión, las opciones son
regression_l2,regression_l1,poisson,quantile,mape,gamma,huber,fair, otweedie. Para tareas de clasificacion, las opciones sonbinary,multiclass, omulticlassova. Es importante configurar este parámetro correctamente para evitar resultados impredecibles o baja precision.

Ejemplo Practico
En el pasado cree un proyecto usando LightGBM pero esta vez lo voy a utilizar con un dataset diferente.
En este caso estare clasificando a diferentes aplicantes a un préstamo. No voy a hacer un analisis de los datos, directamente iré al desarrollo del modelo.
Resultados
Luego de una busqueda de parámetros, evalué el modelo y dió estos resultados:
The accuracy of prediction is: 0.9078853557678597
The roc_auc_score of prediction is: 0.9115936285698222
The null accuracy is: 0.653429345501212
Confusion Matrix

Importancia de los atributos
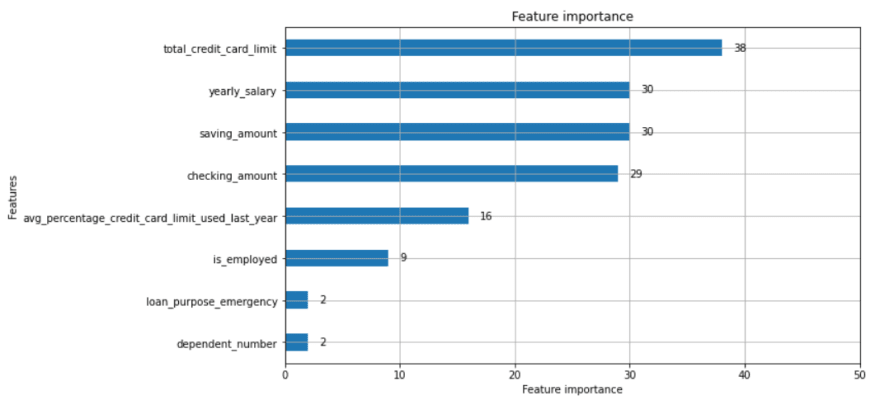
Como podemos ver, LightGBM es un algoritmo confiable incluso en este dataset de tamaño mediano (46751 filas).

Top comments (0)