
Parsing real estate data will be useful for realtors as well as large estate companies. It can be used both to analyze the situation on the market and to find the most profitable offers.
For businesses, this information can be vital. In order to stay at the top of sales, one needs to always have up-to-date prices and know the conditions offered by competitors. Manual collection and analysis of such data is extremely difficult, but scraping will come in handy.
Tool for Scraping Real Estate Data
Choosing a scraping tool is an important step in real estate data parsing. The required fields for data collection may differ for each platform and for each individual case.
Let's say the task is to collect data from a public real estate listing platform. The purpose of data collection is to find out the dependence of the value of real estate on the distance to the station or public transport stop. In this case, the following fields will be required: property type (for each type, the dependence will be built separately), property address, distance to a public transport stop or station, and price. For every city it will also be necessary to build separate dependencies.
Of course, the presence of a station is not the only indicator that affects the change in cost. Therefore, in real projects, the number of such criteria can reach dozens. And the amount of data collected in such samples can reach thousands and hundreds of thousands. It is extremely difficult to do this manually, but the following options can be used to automate this process:
- Creation of a scraper. This option requires some knowledge in the field of programming and time to implement it. The advantage of this approach is that it is completely free. And the downside is the need to perform all the settings, interact with sites and provide the necessary level of protection against blocking.
- Using tools for web scraping (plugins and applications). This approach will be very expensive. In addition, such a tool isn't flexible and sometimes it's impossible to parse the data in the right form.
- Using the web scraping API . This option is optimal and combines the features of the two above. And that is why it is worth stopping on this method in detail.
In case the use of web scraping for business still seems not attractive and important enough, read about all the benefits of web scraping for real estate.
API for Scraping Real Estate Data
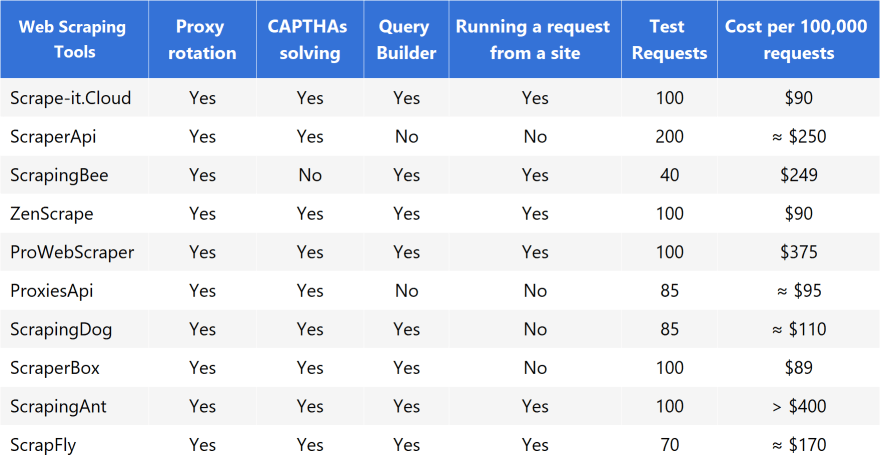
There are many APIs that offer their services to perform scraping. The most popular ones: Scrape-It.Cloud, ScraperAPI, Scrapingbee, ZenScrape, Prowebscraper, Proxiesapi, Scrapingdog, Scraper Box, Scrapingant, Scrapfly.
The choice is proposed to be made according to some criteria:
- Proxy rotation. This means that the service offers to use proxies belonging to the same region as the site from which the data is scraped. That is, if it collects data on New York real estate, the proxy will also be New York. This is very important and worth paying attention to.
- CAPTCHAs solving. In the process of scraping data, the site may suspect that the activity doesn't belong to a real person, but to a bot. In this case, the site may offer the scraper to solve the captcha to make sure that this isn't a bot. And if the service can't solve captchas, this can affect the scraper for the worse.
- Query builder. In order to build requests to the API, it isn’t necessary to have special knowledge if the site has a query builder. It is enough to select the necessary criteria and use a ready-made query.
- Running a request from a site. Before using a query, it is advisable to check it. In this case, the availability of such an option on the site will be a plus.
- Test Requests. To decide to buy something, first it is worth testing and the presence of test requests can be critical in this case.
- Cost of requests. The price of queries is often the main factor when choosing a tool for collecting real estate data.
For easy comparison, the data for the above services has been entered into a comparison table, which allows to determine the most suitable API for collecting real estate data for business.
It is worth noting that most services have an internal currency and the cost of a request may vary depending on the parameters, so for a convenient comparison, the cost of 100,000 requests was chosen at the average price of one request.
 An example of data parsing will be based on the scrape-it.cloud service. However, the actions will be similar for most of the listed services.
An example of data parsing will be based on the scrape-it.cloud service. However, the actions will be similar for most of the listed services.
Service for Scraping Data
First, decide on a data collection service. As a rule, the real estate business will be tasked with scraping data on one of the following options:
- Real estate markets (Zillow, Trulia, Redfin, Airbnb and etc.).
- Real estate listing sites (Zoopla, RightMove, Realtor and etc.).
- Property management sites (Appfolio, TennantCloud, Yardi and etc.).
- Real estate aggregators (Nestoria, LoopNet, Apartments.com and etc.).
Let's take a look at data scraping from the Zoopla real estate listing site.
Performing Data Scraping
Let’s collect location data for one-bedroom apartments for sale in London. Let's assume that this is necessary for further analysis by the number of apartments for sale in each of the districts.
To get started, go to the Zoopla website and search for the given criteria. This can be written programmatically, however, to simplify the task, the search will be performed on the site.
 After that, find exactly where the necessary data is stored. To do this, go to DevTools (F12 key, or right-click on an empty area of the page and select Inspect).
After that, find exactly where the necessary data is stored. To do this, go to DevTools (F12 key, or right-click on an empty area of the page and select Inspect).
 Press the element selection key and click on the string containing the address of the property. Hover over the selected code fragment and right-click on it.
Press the element selection key and click on the string containing the address of the property. Hover over the selected code fragment and right-click on it.
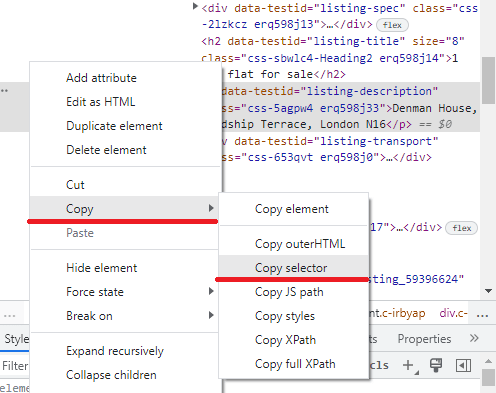 After that, copy the selector. It needs to be written down and saved - it will be needed later.
After that, copy the selector. It needs to be written down and saved - it will be needed later.
Go to the Scrape-It.Cloud website and sign up. New users receive 1,000 credits, which allows them to learn more about the service.
After registration, the user enters the personal account. Next, go to the Request Builder.
 By default, the cost of a request is 10 credits. In order to scrape a Zoopla page, a request must be configured. Enter the address of the search page in the URL field.
By default, the cost of a request is 10 credits. In order to scrape a Zoopla page, a request must be configured. Enter the address of the search page in the URL field.
 Specify the request rules, that is, what data should be collected. To do this, use the CSS Selector copied above:
Specify the request rules, that is, what data should be collected. To do this, use the CSS Selector copied above:
# listing_62147486 > _ div > div . css -1 pjvtfc . erq 598 j 1 >
div . css -10 zzqy 2. erq 598 j 9 > a . erq 598 j 10. css -1 gdcbd
8- StyledLink - Link . e 33 dvwd 0 > p
And take only its last significant part:
a.erq598j10.css-1gdcbd8-StyledLink-Link.e33dvwd0>p
It can be found by taking the CSS Selectors of two lots and comparing them, their common part from the end will be significant. Now specify what to select and from where. To collect the text part, use titles. That is, the Extraction rules field should contain:
{"titles": "a.erq598j10.css-1gdcbd8-StyledLink-Link.e33dvwd0 > p"}
If one specifies a full CSS selector, the query will return a single title. Optionally, also specify the use of a proxy:
 After that, try to execute the request - click Run script. The received data can be copied by pressing the copy key.
After that, try to execute the request - click Run script. The received data can be copied by pressing the copy key.
 Execution result:
Execution result:
[
"\"Kempton Apartments\" at Smithy Lane, Hounslow TW3",
"Denman House, Lordship Terrace, London N16",
"Vernon Road, London E3",
"Akerman Road, London SW9",
"Hatherley Court, Hatherley Grove, London W2",
"Waterside Apartments, White City Living, London W12",
"Flat 17 Sumner Road, Sumner Road, London SE15",
"The Atlas Buildings, 149 City Road, Old Street, Aldgate , Londom EC1V",
"Whitehouse Apartment, 9 Belvedere Road, Waterloo, Southbank, Southwark, London SE1",
"North Bloack , Belvedere Road, Waterloo, London SE1",
"Elm Court, Admiral Walk, London W9",
"Everard House, Boyd Street, London E1",
"Darnley Road, Hackney, London E9",
"Sandringham House, Earls Way, London SE1",
"Ivy Court, 20-21 Leighton Grove, Kentish Town, London NW5",
"Hallam Street, Marylebone, London W1W",
"West Green Road, London N15",
"55 Victoria Street, London SW1H",
"Elm Bank Mansions, The Terrace, London SW13",
"Boss House, 2 Boss Street, London SE1",
" Chestwood Grove, Uxbridge UB10",
"Springfield Place, Tooting SW17",
"Springfield Place, Tooting SW17",
"Springfield Place, Tooting SW17",
"Springfield Place, Tooting SW17"
]
After that, also add JavaScript so that after collecting all the records on the current page, the transition to the next one is performed, and so on until all the data is collected.
For more convenience, the received request can be imported, for example, into Postman:

Conclusion
Real estate data scraping is easy enough even for those who have never experienced it before, and the web scraping API is quite a flexible and inexpensive tool.
Extracted data can be used for various purposes: price tracking, market, and competitive intelligence, website upgrades, news monitoring, or content performance analysis.

Top comments (1)
Cool guide on scraping real estate data! Tools like Scrape-It.Cloud are great for effective scraping. And if you want to streamline data collection and stay ahead, check out Crawlbase. It's got advanced features that fit modern business needs.