
Today more and more websites are using Ajax for fancy user experiences, dynamic web pages, and many more good reasons.
Crawling Ajax heavy website can be tricky and painful, we are going to see some tricks to make it easier.
Prerequisite
Before starting, please read the previous articles I wrote to understand how to set up your Java environment, and have a basic understanding of HtmlUnit Introduction to Web Scraping With Java and Handling Authentication.
After reading this you should be a little bit more familiar with web scraping.
Setup
The first way to scrape Ajax website with Java that we are going to see is by using PhantomJS with Selenium and GhostDriver.
PhantomJS is a headless web browser based on WebKit ( used in Chrome and Safari). It is quite fast and does a great job to render the Dom like a normal web browser.
- First you'll need to download PhantomJS
- Then add this to your pom.xml :
<dependency>
<groupId>com.github.detro</groupId>
<artifactId>phantomjsdriver</artifactId>
<version>1.2.0</version>
</dependency>
and this :
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>2.53.1</version>
</dependency>
PhantomJS and Selenium
Now we're going to use Selenium and GhostDriver to "pilot" PhantomJS.
The example that we are going to see is a simple "See more" button on a news site, that perform a ajax call to load more news.
So you may think that opening PhantomJS to click on a simple button is a waste of time and overkilled ? Of course it is !
The news site is : Inshort
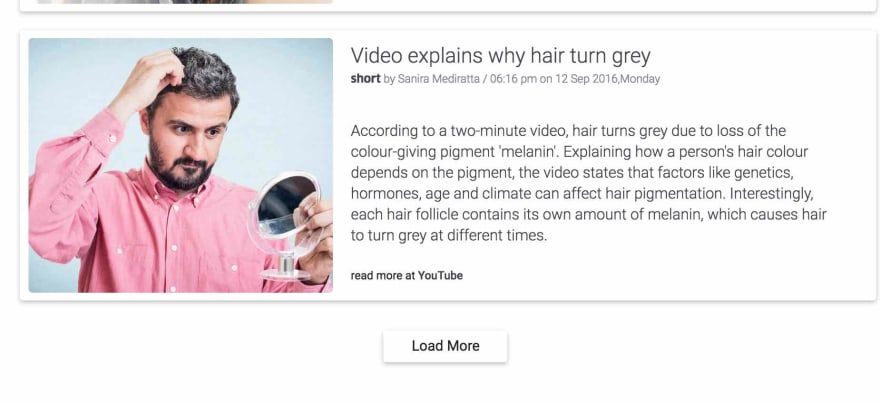
As usual we have to open Chrome Dev tools or your favorite inspector to see how to select the "Load More" button and then click on it.

Now let's look at some code :
private static String USER_AGENT = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36";
private static DesiredCapabilities desiredCaps ;
private static WebDriver driver ;
public static void initPhantomJS(){
desiredCaps = new DesiredCapabilities();
desiredCaps.setJavascriptEnabled(true);
desiredCaps.setCapability("takesScreenshot", false);
desiredCaps.setCapability(PhantomJSDriverService.PHANTOMJS_EXECUTABLE_PATH_PROPERTY, "/usr/local/bin/phantomjs");
desiredCaps.setCapability(PhantomJSDriverService.PHANTOMJS_PAGE_CUSTOMHEADERS_PREFIX + "User-Agent", USER_AGENT);
ArrayList<String> cliArgsCap = new ArrayList();
cliArgsCap.add("--web-security=false");
cliArgsCap.add("--ssl-protocol=any");
cliArgsCap.add("--ignore-ssl-errors=true");
cliArgsCap.add("--webdriver-loglevel=ERROR");
desiredCaps.setCapability(PhantomJSDriverService.PHANTOMJS_CLI_ARGS, cliArgsCap);
driver = new PhantomJSDriver(desiredCaps);
driver.manage().window().setSize(new Dimension(1920, 1080));
}
That's a lot of code to setup phantomJs and Selenium !
I suggest you to read the documentation to see the many arguments you can pass to PhantomJS.
Note that you will have to replace /usr/local/bin/phantomjs with your own phantomJs executable path
Then in a main method :
System.setProperty("phantomjs.page.settings.userAgent", USER_AGENT);
String baseUrl = "https://www.inshorts.com/en/read" ;
initPhantomJS();
driver.get(baseUrl) ;
int nbArticlesBefore = driver.findElements(By.xpath("//div[@class='card-stack']/div")).size();
driver.findElement(By.id("load-more-btn")).click();
// We wait for the ajax call to fire and to load the response into the page
Thread.sleep(800);
int nbArticlesAfter = driver.findElements(By.xpath("//div[@class='card-stack']/div")).size();
System.out.println(String.format("Initial articles : %s Articles after clicking : %s", nbArticlesBefore, nbArticlesAfter));
Here we call the initPhantomJs() method to setup everything, then we select the button with its id and click on it.
The other part of the code count the number of articles we have on the page and print it to show what we have loaded.
We could have also printed the entire dom with driver.getPageSource()and open it in a real browser to see the difference before and after the click.
I suggest you to look at the Selenium Webdriver documentation, there are lots of cool methods to manipulate the DOM.
I used a dirty solution with my Thread.sleep(800) to wait for the Ajax call to complete.
It's dirty because it is an arbitrary number, and the scraper could run faster if we could wait just the time it takes to perform that ajax call.
There are other ways of solving this problem :
public static void waitForAjax(WebDriver driver) {
new WebDriverWait(driver, 180).until(new ExpectedCondition<Boolean>() {
public Boolean apply(WebDriver driver) {
JavascriptExecutor js = (JavascriptExecutor) driver;
return (Boolean) js.executeScript("return jQuery.active == 0");
}
});
}
If you look at the function being executed when we click on the button, you'll see it's using jQuery :
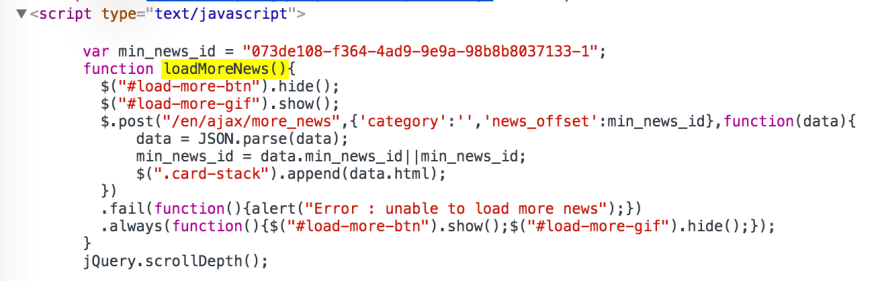
This code will wait until the variable jQuery.active equals 0 (it seems to be an internal variable of jQuery that counts the number of ongoing ajax calls)
If we knew what DOM elements the Ajax call is supposed to render we could have used that id/class/xpath in the WebDriverWait condition :
wait.until(ExpectedConditions.elementToBeClickable(By.xpath(xpathExpression)))
Conclusion
So we've seen a little bit about how to use PhantomJS with Java.
The example I took is really simple, it would have been easy to simulate the request.
But sometimes when you have tens of Ajax calls, and lots of Javascript being executed to render the page properly, it can be very hard to scrape the data you want, and PhantomJS/Selenium is here to save you :)
Next time we will see how to do it by analyzing the AJAX calls and make the requests ourselves.
As usual you can find all the code in my Github repo
Rendering JS at scale can be really difficult and expensive. This is exactly the reason why we build ScrapingBee, a web scraping API that take care of this for you.
It will also take car of proxies and CAPTCHAs, don't hesitate to check it out, the first 1000 API calls are on us.

Top comments (1)
Wow, what a helpful guide on dealing with tricky Ajax websites using Java! Thanks for breaking it down so clearly. If you're into web scraping like me, this is gold. Oh, and if you need a hand with scraping tasks, check out Crawlbase. It could be your ultimate companion.