
XPath is a technology that uses path expressions to select nodes or node- sets in an XML document (or in our case an HTML document). Even if XPath is not a programming language in itself, it allows you to write expressions that can access directly to a specific HTML element without having to go through the entire HTML tree.
It looks like the perfect tool for web scraping right? At ScrapingBee we love XPath!
Why learn XPath
- Knowing how to use basic XPath expressions is a must-have skill when extracting data from a web page.
- It's more powerful than CSS selectors
- It allows you to navigate the DOM in any direction
- Can match text inside HTML elements
Entire books have been written on XPath, and I don’t have the pretention to explain everything in-depth, this is an introduction to XPath and we will see through real examples how you can use it for your web scraping needs.
But first, let's talk a little about the DOM
Document Object Model
I am going to assume you already know HTML, so this is just a small reminder.
As you already know, a web page is a document containing text within tags, that add meaning to the document by describing elements like titles, paragraphs, lists, links etc.
Let's see a basic HTML page, to understand what the Document Object Model is.
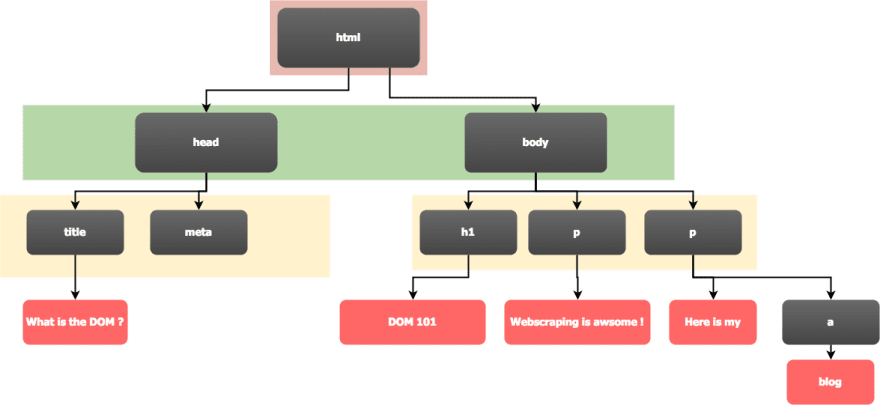
This HTML code is basically HTML content encapsulated inside other HTML content. The HTML hierarchy can be viewed as a tree. We can already see this hierarchy through the indentation in the HTML code.
When your web browser parses this code, it will create a tree which is an object representation of the HTML document. It is called the Document Object Model.
Below is the internal tree structure inside Google Chrome inspector :
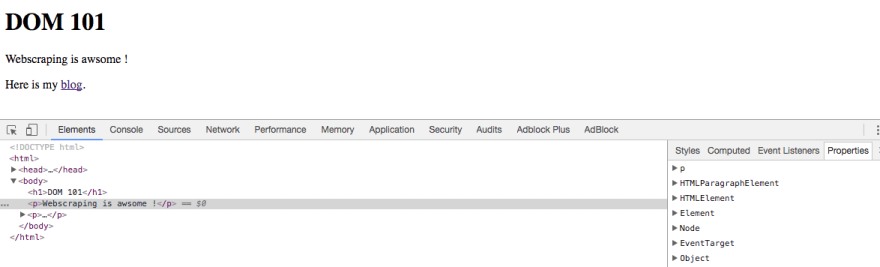
On the left we can see the HTML tree, and on the right we have the Javascript object representing the currently selected element (in this case, the <p> tag), with all its attributes.
The important thing to remember is that the DOM you see in your browser, when you right click + inspect can be really different from the actual HTML that was sent. Maybe some Javascript code was executed and dynamically changed the DOM ! For example, when you scroll on your twitter account, a request is sent by your browser to fetch new tweets, and some Javascript code is dynamically adding those new tweets to the DOM.
XPath Syntax
First let’s look at some XPath vocabulary :
• In Xpath terminology, as with HTML, there are different types of nodes : root nodes, element nodes, attribute nodes, and so called atomic values which is a synonym for text nodes in an HTML document.
• Each element node has one parent. in this example, the section element is the parent of p, details and button.
• Element nodes can have any number of children. In our example, li elements are all children of the ul element.
• Siblings are nodes that have the same parents. p, details and button are siblings.
• Ancestors a node’s parent and parent’s parent...
• Descendants a node’s children and children’s children...
There are different types of expressions to select a node in an HTML document, here are the most important ones :
You can also use predicates to find a node that contains a specific value. Predicates are always in square brackets: [predicate]
Here are some examples :
Now we will see some examples of Xpath expressions. We can test XPath expressions inside Chrome Dev tools, so it is time to fire up Chrome.
To do so, right-click on the web page -> inspect and then cmd + f on a Mac or ctrl + f on other systems, then you can enter an Xpath expression, and the match will be highlighted in the Dev tool.

Tip
In the dev tools, you can right-click on any DOM node, and show its full XPath expression, that you can later factorize.
XPath with Python
There are many Python packages that allow you to use XPath expressions to select HTML elements like lxml, Scrapy or Selenium. In these examples, we are going to use Selenium with Chrome in headless mode. You can look at this article to set up your environment: Scraping Single Page Application with Python
E-commerce product data extraction
In this example, we are going to see how to extract E-commerce product data from Ebay.com with XPath expressions.
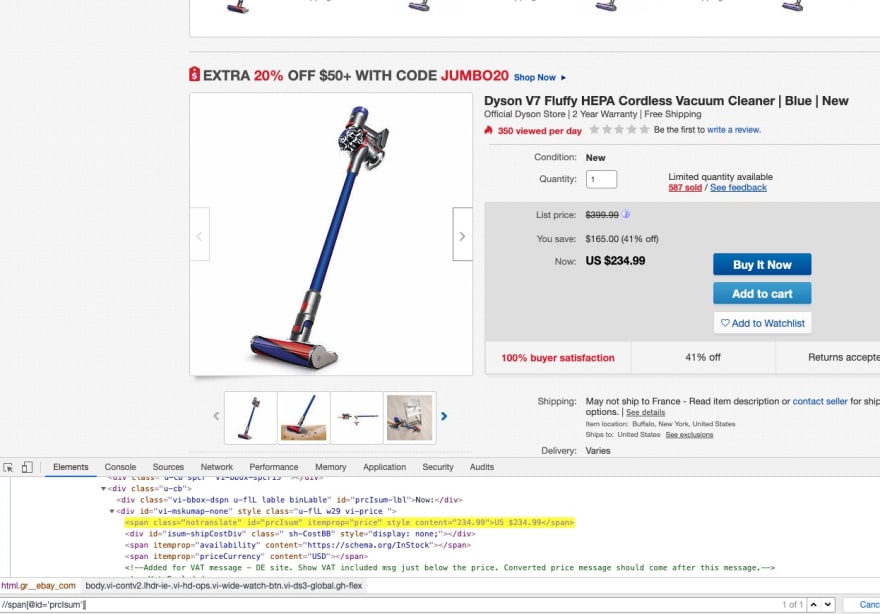
On these three XPath expressions, we are using a // as an axis, meaning we are selecting nodes anywhere in the HTML tree. Then we are using a predicate [predicate] to match on specific IDs. IDs are supposed to be unique so it's not a problem do to this.
But when you select an element with its class name, it's better to use a relative path, because the class name can be used anywhere in the DOM, so the more specific you are the better. Not only that, but when the website will change (and it will), your code will be much more resilient to changes.
Automagically authenticate to a website
When you have to perform the same action on a website or extract the same type of information we can be a little smarter with our XPath expression, in order to create generic ones, and not specific XPath for each website.
In order to explain this, we're going to make a "generic" authentication function that will take a Login URL, a username and password, and try to authenticate on the target website.
To auto-magically log into a website with your scrapers, the idea is :
GET /loginPage
Select the first tag
Select the first before it that is not hidden
Set the value attribute for both inputs
Select the enclosing form and click on the submit button.
Most login forms will have an <input type="password"> tag. So we can select this password input with a simple: //input[@type='password']
Once we have this password input, we can use a relative path to select the username/email input. It will generally be the first preceding input that isn't hidden: .//preceding::input[not(@type='hidden')]
It's really important to exclude hidden inputs, because most of the time you will have at least one CSRF token hidden input. CSRF stands for Cross Site Request Forgery. The token is generated by the server and is required in every form submissions / POST requests. Almost every website use this mechanism to prevent CSRF attacks.
Now we need to select the enclosing form from one of the input:
.//ancestor::form
And with the form, we can select the submit input/button:
.//*[@type='submit']
Here is an example of such a function:
Of course it is far from perfect, it won't work everywhere but you get the idea.
Conclusion
XPath is very powerful when it comes to selecting HTML elements on a page, and often more powerful than CSS selectors.
One of the most difficult task when writing XPath expressions is not the expression in itself, but being precise enough to be sure to select the right element when the DOM will change, but also resilient enough to resist DOM changes.
At ScrapingBee, depending on our needs, we use XPath expressions or CSS selectors for our ready-made APIs. We will discuss the differences between the two in another blog post!
I hope you enjoyed this article, next time we will talk about ... CSS selectors :)
Happy Scraping!
Discuss on HN: https://news.ycombinator.com/item?id=21452310

Top comments (2)
How much more powerful are they? I know they can be used to select based on node content, which is not possible with CSS. Any other advantages?
Edit: I did some more research and CSS is not able to select a parent, so XPath is more powerful in that regard too. Interesting.
stackoverflow.com/questions/101486...
Amazing! This blog provides a concise yet comprehensive guide to using XPath for web scraping. It explains XPath's significance, syntax, and practical applications effectively. For robust scraping solutions, consider platforms like Crawlbase, which streamline data extraction tasks. Happy Scraping!