Introduction to Google's Gemma 3
Google's Gemma 3, launched in March 2025, is a revolutionary AI model designed to bring powerful AI capabilities to everyone. Unlike conventional AI models that rely on expensive, high-performance hardware, Gemma 3 has been optimized to deliver excellent performance across a variety of devices, from smartphones to workstations.
Running on Low-End Devices and Consumer-Level Graphics
For low-end devices like smartphones, the 1 billion parameter model is ideal. At only 529MB in size, Gemma 3 1B runs at up to 2585 tok/sec on prefill via Google AI Edge's LLM inference.
For users with consumer-level graphics cards, such as those in typical laptops or desktops, the 4 billion parameter model can be run on a GTX 1650 4GB or better. Optimizations like 4-bit quantization and tools like Llama.cpp help it perform well on standard hardware, making AI practical for personal computers.
Prerequisites:
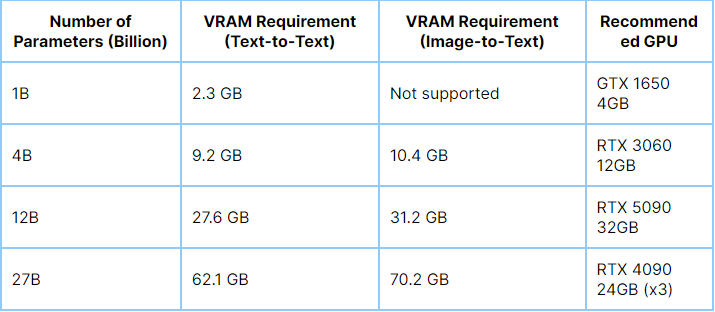
Hardware Requirements:
Ensure your system has a compatible GPU. For instance, the Gemma 3 27B model requires a GPU with at least 24 GB of VRAM, such as the NVIDIA RTX 3090.
Software Requirements:
A 64-bit operating system (Windows 10/11, macOS, or Linux).
Administrative privileges to install software.
Check your VRAM:
Step 1: Install Ollama
Ollama is a platform that facilitates the running of AI models locally. It supports various operating systems and simplifies the deployment process.
Download Ollama from the official website here:
https://ollama.com/
For Linux:
Open the terminal.
Run the following commands:
sudo apt-get update
sudo apt-get install pciutils -y
curl -fsSL https://ollama.com/install.sh | sh
For macOS:
Open the Terminal application.
Run the following command to install Ollama:
curl -fsSL https://ollama.com/install.sh | sh
Step 2: Install Gemma 3 Model
Once Ollama is installed, you can proceed to install the Gemma 3 model.
Open your terminal or command prompt.
Run one of the following commands to install the Gemma 3 model suitable for your computer:
ollama run gemma3:1b
ollama run gemma3:4b
ollama run gemma3:12b
ollama run gemma3:27b
This command downloads the Gemma 3 model to your local machine.
Step 3: Run Gemma 3 Locally
After the model is installed, you can start using it for various AI tasks.
In your terminal or command prompt, enter the following command:
ollama run gemma3:4b
Step 4 (Optional): Install Page Assist - A Web UI
The browser extension enables you to use your locally running AI models to assist you in your web browsing.
Page Assist for Chrome:
https://chromewebstore.google.com/detail/page-assist-a-web-ui-for/jfgfiigpkhlkbnfnbobbkinehhfdhndo?pli=1
Page Assist for Firefox:
https://addons.mozilla.org/en-US/firefox/addon/page-assist/
Page Assist for Edge:
https://microsoftedge.microsoft.com/addons/detail/page-assist-a-web-ui-fo/ogkogooadflifpmmidmhjedogicnhooa
For other browsers, please check out the Page Assist Github page:
https://github.com/n4ze3m/page-assist?tab=readme-ov-file
Page Assist UI:
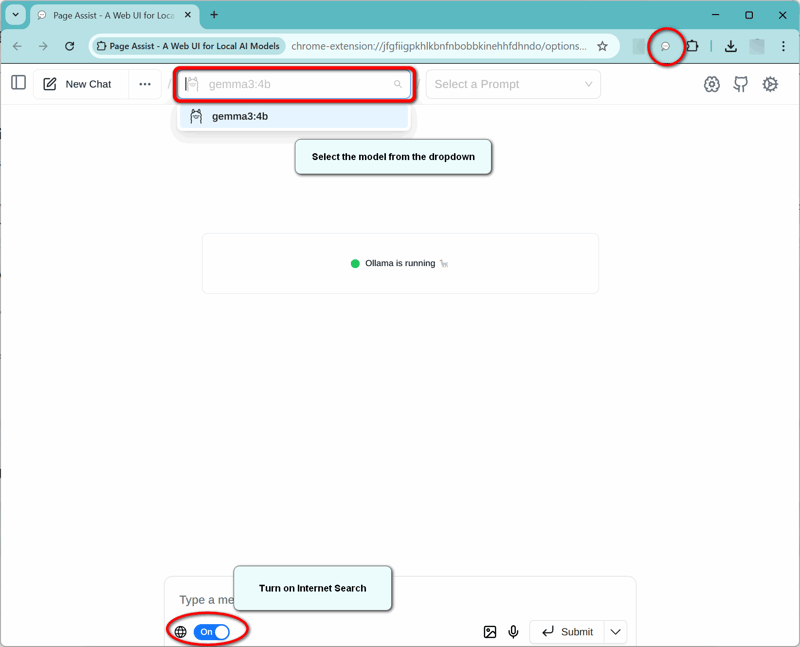
Page Assist UI Settings:

Top comments (0)