
In the previous post, we saw how Parameterised Tests help write more focused, concise and scalable tests. However, Parameterised Tests belong to the so-called Example-Based Tests: the tests run only with the input and expected values we choose to pass as examples. And this arises the question: what if the tests would not pass with any other valid examples we have not picked?
Back to the Password Validator Example
One of the reasons to write tests is that they protect us against regression bugs. They serve as a tool to detect code changes that cause a feature that worked correctly to stop working. If that happens, the corresponding tests turn red and point out what got broken.
Coming back to the PasswordValidator of my previous post, the final Parameterised Test looked like this:
val passwordValidator = PasswordValidator(
ContainsUpperCaseLetterValidator(),
MinCharsValidator(6),
ContainsDigitValidator(),
ContainsLowerCaseLetterValidator(),
NoBlanksValidator()
)
@DisplayName("PasswordValidator for invalid passwords")
@ParameterizedTest(name = "When password is \"{0}\", the error contains \"{1}\"")
@CsvSource(
"123456, no upper case letters",
"ABCDEF, no digits",
"HELLO, no lower case letters",
"1234A, contains less than 6 chars",
"12 3 456, contains blanks"
)
fun testPasswordValidatorRight(password: String?, expectedError: String?) {
val actualError = passwordValidator.validate(password)
assertThat(actualError).contains(expectedError)
}
Let's imagine now that you need to make some adjustments in the Validators. You finish it and push your code. However, It turns out that another teammate has also touched the Validators, and you are having some conflicts. You solve the conflicts and push the code again. Finally, your tests run green in your CI, so you are confident enough to merge your code.
But, before that happening, your teammate reviews the code and requires you to do some code changes. He found out that the ContainsUpperCaseLetterValidator implementation is incorrect.
So you take a look...
class ContainsUpperCaseLetterValidator : RequirementValidator {
override val keywordOnError: String? = "no upper case letters"
override fun isValid(password: String?): Boolean =
password?.contains("[a-z]".toRegex()) == true
}
You can see the code snippet of this broken validator here
Yes, it turned out that it now validates lower case (i.e. "[a-z]") instead of upper case chars (i.e. "[A-Z]").
On the other hand, you feel confused. All tests ran green on the CI. What could be wrong? So you run the test again locally.
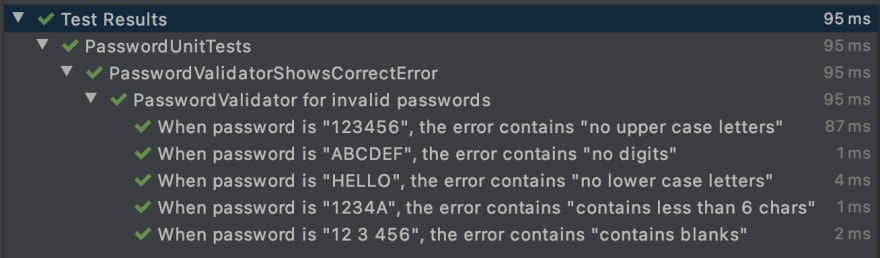
Still green. We know it should run red since we have detected the error in the implementation itself.
But take a closer look at the ContainsUpperCaseLetterValidator first Example-based Test.
There we input the password "123456", so passwordValidator.validate("123456") should return an error message, not only for ContainsUpperCaseValidator, but also for ContainsLowerCaseValidator as well, since it does contain neither upper case nor lower case chars, just digits.
In this case, we can fix the test (but not the implementation) by adding an extra example for ContainsUpperCaseValidator containing a lower case char in the password input, for instance "a23456". In doing so, the test runs red, as expected.
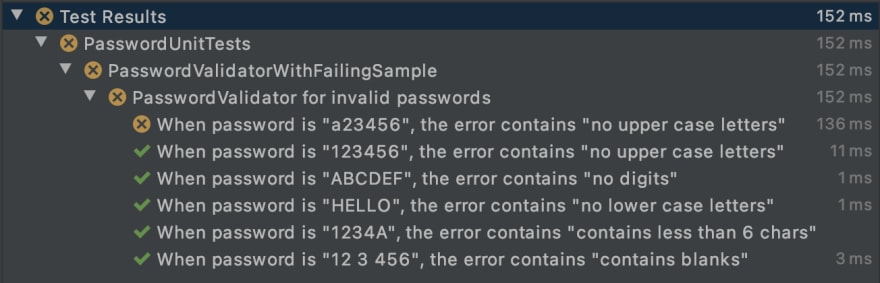
Click on this link to see the code of all the Parameterised Tests
This proves that choosing the right examples is very important to catch regression bugs, as well as tricky. How reliable is our test suite? How can we be sure that we have covered all the necessary cases with this extra example? what if we missed some edge cases? how many examples do we need to be confident enough?
Property-Based Tests to the rescue
Following the previous example, we could conclude that any password without at least 1 upper case char, must show the error message "does not contain upper case chars". This combination of preconditions and qualities that must be valid at every time is called property.
What if instead of just providing concrete valid examples through Parameterised Tests, we would also generate random valid values for the precondition (no upper case chars) that must always fulfil the quality (shows "does not contain upper case chars" in the error message)? This is called Property-Based Testing (PBT).
In my opinion, the most powerful PBT engine for JVM languages out there is Jqwik. I find it much more flexible than Kotest or QuickUnit when it comes to writing custom value generators. Moreover, it provides unique features such as collecting statistics for the generated inputs, what comes in handy to ensure that the generated random values are among those expected.
Therefore, all the examples of this article will be written with Jqwik.
Configuration
Jqwik is very easy to configure and can run together with Junit4 and Junit5. In an Android project you just need to add the following to your project gradle file.
android {
...
testOptions {
unitTests.all {
useJUnitPlatform {
//this config supports Jqwik, Junit4 and Junit5
includeEngines 'jqwik', 'junit-jupiter', 'junit-vintage'
}
include '**/*Properties.class'
include '**/*Test.class'
include '**/*Tests.class'
}
}
}
dependencies {
...
testImplementation "net.jqwik:jqwik-api:1.5.1"
testImplementation "net.jqwik:jqwik-engine:1.5.1"
}
For other java/jvm projects you can check the Jqwik doc .
Our first Property-Based Test
Property-Based Tests require to provide a Generator that creates the constrained values programatically or through an annotation.
In Jqwik, you can create a Generator with @Provide, which must return a Jqwik Arbitrary<String> for our arbitrary password.
Our generator, which must generate random strings without upper case chars, is as follows
@Provide
fun noUpperCase(): Arbitrary<String> =
Arbitraries.strings().ascii().filter { it.matches("[^A-Z]".toRegex()) }
Nevertheless, this does not ensure us that the generated input is among the values we expect. As I mentioned before, one of the special features of Jqwik is collecting statistics for the generated inputs. In doing so, we ensure the correctness of the generated inputs. I strongly recommend to always add them to your Property-Based Tests.
According to our "strong password" rules, makes sense to watch for digits, as well as lower and upper case chars in our tests. The corresponding methods might look like this in Jqwik.
fun statsUpperCase(password: String?){
val withUpperCase = password?.contains("[A-Z]".toRegex())
Statistics
.label("Upper case")
.collect(if (withUpperCase == true) "with upper case" else "without upper case")
}
...
fun collectPasswordStats(password: String?){
statsUpperCase(password)
statsLowerCase(password)
statsDigits(password)
...
}
See the full implementation of the stat collectors here
By adding statistics on the generated inputs you feel more confident about testing the right thing. The reports will contain those statistics as you'll see later.
Once we have the generator and the statistics, our tests would look like this
@Label("If password without upper case chars," +
"the error message contains 'no upper case letters'"
)
@Property
fun testPasswordValidatorRight(@ForAll("noUpperCase") password: String?) {
collectPasswordStats(password)
val actualError = passwordValidator.validate(password)
Truth.assertThat(actualError).contains("no upper case letters")
}
You can find the full test suite with PBT examples for all the validators as well as the random value generators here
And if we run it, we get a report similar to the one below

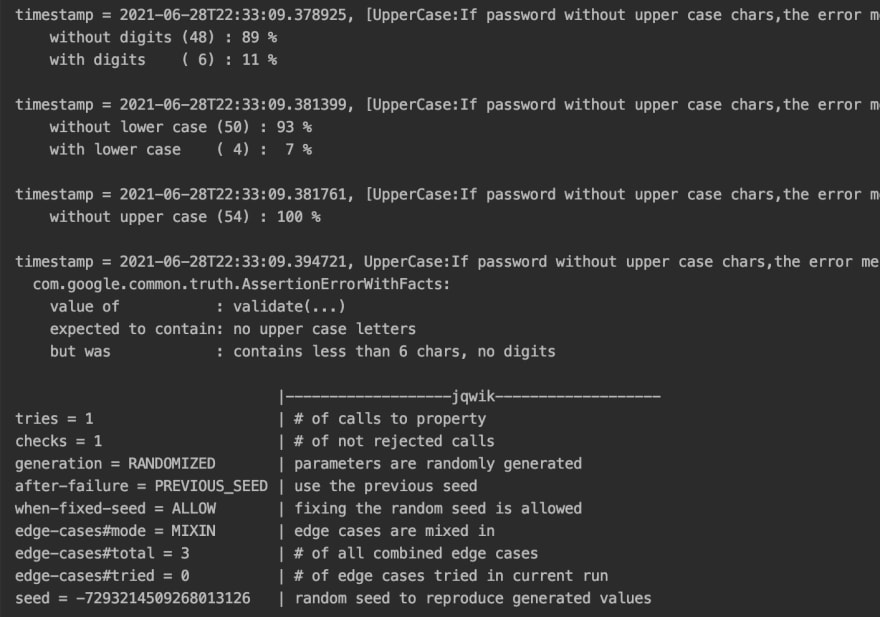
Great! The test fails as expected, and 100% of the generated values are upper case free. As you can see, Jqwik Generators take edge cases into account as well (more about edge cases here ) by default.
Why flaky tests is not an issue in PBT
You might be thinking... the test fails, but the values are being generated randomly on every run... So if I run the test again, new values are generated, and could happen that the test does not fail for those new random values. Non-reproducible tests decrease reliability on your test suite and need to be avoided.
But do not worry.
First of all, Jqwik reuses the same seed to generate random values until a green run by default.
Secondly, if you need to reproduce the tests with the same values at any time, just add the seed shown in the previous report, at the very bottom, to the test
@Label("If password without upper case chars," +
"the error message contains 'no upper case letters'"
)
@Property(seed = "-7293214509268013126")
fun testPasswordValidatorRight(@ForAll("noUpperCase") password: String?) {
collectPasswordStats(password)
val actualError = passwordValidator.validate(password)
Truth.assertThat(actualError).contains("no upper case letters")
}
Now you can run the test continuously with the same values that made it fail.
Do not forget to remove the seed once fixed. That way the generators will continue generating new random values on every run. In doing, so you might find out other values for which the implementation is incorrect.
Congratulations, your tests have become more robust to regression bugs! You are officially ready to catch'm all!
Conclusion
Let's take a look at the Pros and Cons of Property-Based tests.
Pros
- Tests become more robust, and give you more confidence on your code.
- Tests are deterministic. It's possible to reuse the seed that made them fail, so that errors can be reproduced.
- Explores edge cases by default, which we might forget otherwise.
Cons
- Some properties are hard to find, especially while initiating in PBT. You can take a look at this interesting post by Scott Wlaschin on how to find properties.
- Property-Based Tests run more slowly since they execute 1000 times by default. However, most engines allow you to change that value if desired.
- Properties are not always sufficient to test correctness. Take a look at the wrong implementation of
String?.reversed()and its test below
fun String?.reversed() : String? = this //forgot to reverse it?
@Label("Reversing a reversed String returns the original")
@Property
fun reverseStringTest(@ForAll originalString: String?) {
assertTrue(
originalString?.reversed()?.reversed() == originalString
)
}
The test would pass though, giving us the false impression that the method functionality is correct. On the other hand, this is the kind of error that Example-Based Tests spot quickly.
Therefore, getting the best of both worlds with a combination of Example-Based and Property-Based Tests work the best in most cases.
All the code examples used in this article, as well as those of the first article of this series - Better Unit Tests with Parameterized Tests - are available under this repo.
Did you like this post?
You might also like to take a look at other articles I've written
Cover photo by Brett Jordan on Unsplash

Top comments (0)