(originally published August 9, 2019)
When it came time to make my first application using Ruby, I knew pretty quickly what I wanted to do.
My partner and I run a homebrew Pokémon Tabletop RPG, so a generator app to give our players three randomized choices of Pokémon partner was something I was interested in, fit within the scope of the app I wanted to build, and was something I could actually use in real life!
When it came time to actually put this together though, the biggest problem I ran into was scraping.
Scraping was something I fumbled through in the Flatiron labs on the subject but didn’t really feel like I had learned. I knew enough to make the rspec tests pass and, well, I didn’t have the time to dive further in at the time.
Scraping an actual webpage for data I actually wanted to use didn’t leave me much choice, I had to go a lot deeper—and that ended up being a good thing!
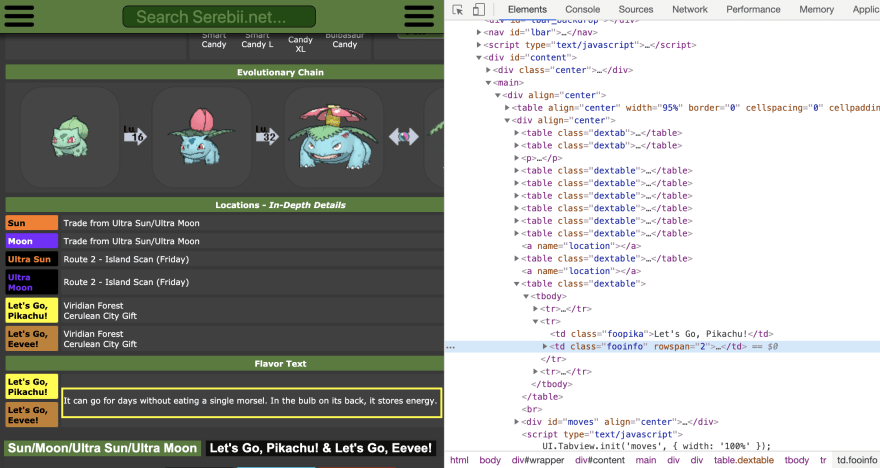
The website I was trying to scrape, with relevant section indicated in yellow.
As of the current series of Pokémon games, there are 809 Pokémon. Since the games are rather complex, each Pokémon has a lot of information on it. For the website I was scraping, this meant pages with a very nested table structure with some very genericly named CSS selectors to look through.
While looking only at the CSS selectors closest to the data I wanted might have worked for the examples used when I was learning scraping, it would not work here. I had to get creative, and dive a lot further in.
I started by refreshing my memory of CSS selectors using the wonderful CSS Diner app, complete with helpful pictures, and then went into my console and typed out exactly what I wanted, which looked something like:
index_page.css('table:nth-of-type(2) tr:nth-of-type(2) td:nth-of-type(2) div:nth-of-type(2) div p tbody tr:nth-of-type(2) td:nth-of-type(2) td.fooinfo.
Yeaaaaah. It’s a lot. And it didn’t work, either.
A few results of an empty array later, I knew I was going to have to take it one step at a time to figure out where the problem was.

Writing out all the CSS selectors in my notebook to keep track of them.
As I've been learning, this is a good way to look at a coding problem in general. If something's broken, go through it bit by bit to see where. I ran the method again, and again, each time with one more CSS selector than before, each time looking carefully through the site's HTML in the inspector to see how it matched up with the Nokogiri object output by my terminal. If the element in my terminal had the same attributes as the element in the website inspector, I went down another level.
And so on, and so forth.
Eventually, I ran into an element that returned the empty array when I included it in my CSS selectors, but luckily, ignoring that one in my list and going down to its child elements instead got me the result I needed. And I had it!
"table:nth-of-type(2) tr:nth-of-type(2) td:nth-of-type(2) div:nth-of-type(2) div td.fooinfo td.foopika" (try saying that five times fast!)
Or, I thought I had it.
While most of the Ruby learning I’d been doing up to this point involved making prewritten rspec tests pass, this app was a different animal. I was free-falling! And with a program that was going to go through three randomized Pokémon pages out of 809, I knew I had better test out this part of the program as much as I could to make sure it didn’t go splat on the pavement. I didn't know what the edge cases would be here, if there were any, so this meant running the scraper again and again.
After 6th time, I got an empty array again. And when I went to the URL that returned it, I figured out why. Because of the way the website was set up, my Pokémon page scraper was working—but only 152 out of 809 entries had the data I wanted!
Without getting into the really specific Pokémon worldbuilding reasons for this (and they exist!), I was able to use a slightly different individual Pokémon page to get the info I needed, and because the data was roughly in the same place, I only had to change the very last bit of my long chain of CSS selectors to do it:
"table:nth-of-type(2) tr:nth-of-type(2) td:nth-of-type(2) div:nth-of-type(2) div td.fooinfo td.ruby"
As a side effect of this, my app was only able to randomly generate from a list of 721 Pokémon instead of 809, but I’m still considering it a win. That is a lot of Pokémon!
Going through this process I learned a lot about how scraping with Nokogiri works, and became a lot more comfortable digging through raw data to find what I wanted. Scraping this way, step by step through all of the elements on the page, is definitely the long way around, but for complex websites you really want to grab some data from, it’s worth it!

Top comments (0)