
This post was first posted on my blog. Please read K-nearest neighbor algorithm with Sklearn and upvote on Reddit and hackernews.
KNN also known as K-nearest neighbor is a supervised and pattern classification learning algorithm which helps us to find which class the new input(test value) belongs to when k nearest neighbors are chosen and distance is calculated between them.
It attempts to estimate the conditional distribution of
YgivenX, and classify a given observation(test value) to the class with highest estimated probability.
It first identifies the k points in the training data that are closest to the test value and calculates the distance between all those categories. The test value will belong to the category whose distance is the least.
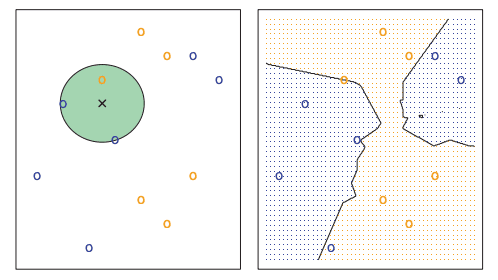
Probability of classification of test value in KNN
It calculates the probability of test value to be in class j using this function
Ways to calculate the distance in KNN
The distance can be calculated using different ways which include these methods,
- Euclidean Method
- Manhattan Method
- Minkowski Method
- etc...
For more information on distance metrics which can be used, please read this post on KNN.
You can use any method from the list by passing metric parameter to the KNN object. Here is an answer on Stack Overflow which will help. You can even use some random distance metric.
Also read this answer as well if you want to use your own method for distance calculation.
The process of KNN with Example
Let's consider that we have a dataset containing heights and weights of dogs and horses marked properly. We will create a plot using weight and height of all the entries.
Now whenever a new entry comes in from the test dataset, we will choose a value of k.
For the sake of this example, let's assume that we choose 4 as the value of k. We will find the distance of the nearest four values and the one having the least distance will have more probability and is assumed as the winner.
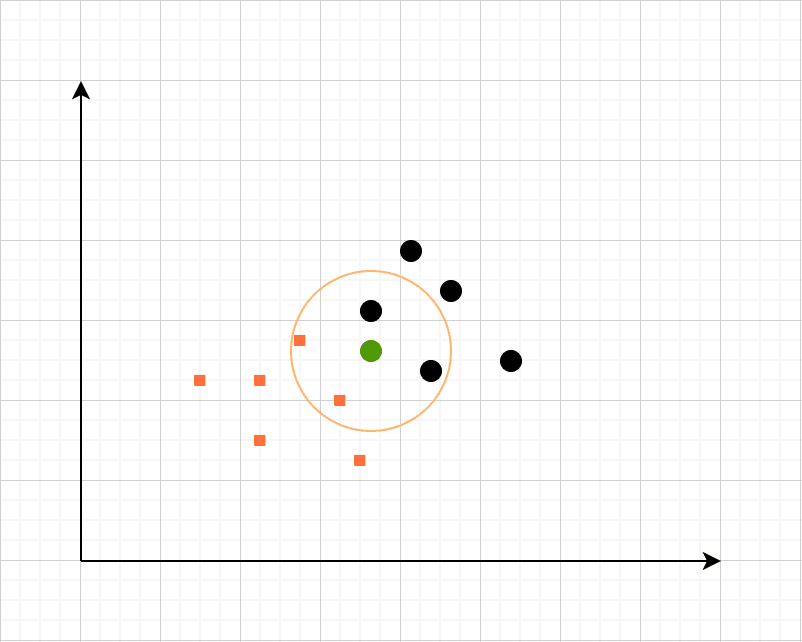
KneighborsClassifier: KNN Python Example
GitHub Repo: KNN GitHub Repo
Data source used: GitHub of Data Source
In K-nearest neighbor algorithm most of the time you don't really know about the meaning of the input parameters or the classification classes available.
In the case of interviews, this is done to hide the real customer data from the potential employee.
# Import everything
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# Create a DataFrame
df = pd.read_csv('KNN_Project_Data')
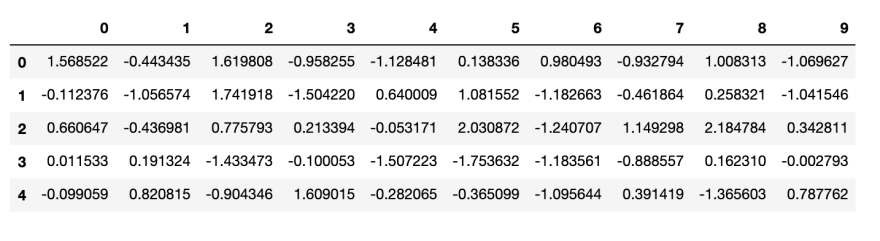
# Print the head of the data.
df.head()
KNN algorithm Head of dataframe
The head of the data clearly says that we have a few variables and a target class that contain different classes for given parameters.
Why normalize/ standardize the variables for KNN
As we can already see that the data in the data frame is not standardized, if we don't normalize the data the outcome will be fairly different and we won't be able to get the correct results.
This happens because some feature has a good amount of deviation in them (values range from 1-1000). This will lead to a very bad plot producing a lot of defects in the model.
For more info on normalization, check this answer on stack exchange.
Sklearn provides a very simple way to standardize your data.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(df.drop('TARGET CLASS', axis=1))
sc_transform = scaler.transform(df.drop('TARGET CLASS', axis=1))
sc_df = pd.DataFrame(sc_transform)
# Now you can safely use sc_df as your input features.
sc_df.head()
Test/Train split using sklearn
We can simply split the data using sklearn.
from sklearn.model_selection import train_test_split
X = sc_transform
y = df['TARGET CLASS']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
Using KNN and finding an optimal k value
Choosing a good value of k can be a daunting task. We are going to automate this task using Python. We were able to find a good value of k which can minimize the error rate in the model.
# Initialize an array that stores the error rates.
from sklearn.neighbors import KNeighborsClassifier
error_rates = []
for a in range(1, 40):
k = a
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
preds = knn.predict(X_test)
error_rates.append(np.mean(y_test - preds))
plt.figure(figsize=(10, 7))
plt.plot(range(1,40),error_rates,color='blue', linestyle='dashed', marker='o',
markerfacecolor='red', markersize=10)
plt.title('Error Rate vs. K Value')
plt.xlabel('K')
plt.ylabel('Error Rate')
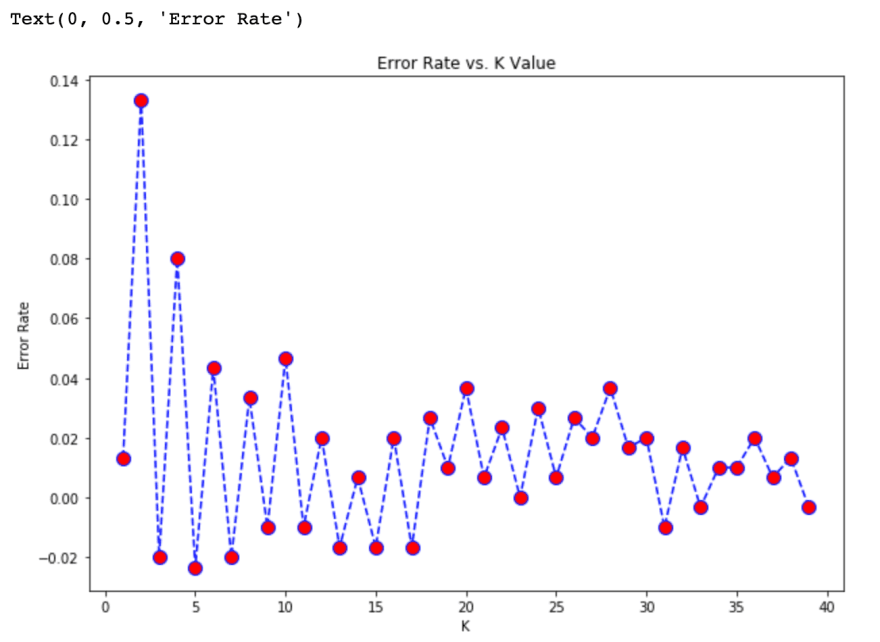
Seeing the graph, we can see that k=30 gives a very optimal value of error rate.
k = 30
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
preds = knn.predict(X_test)
Evaluating the KNN model
Read the following post to learn more about evaluating a machine learning model.
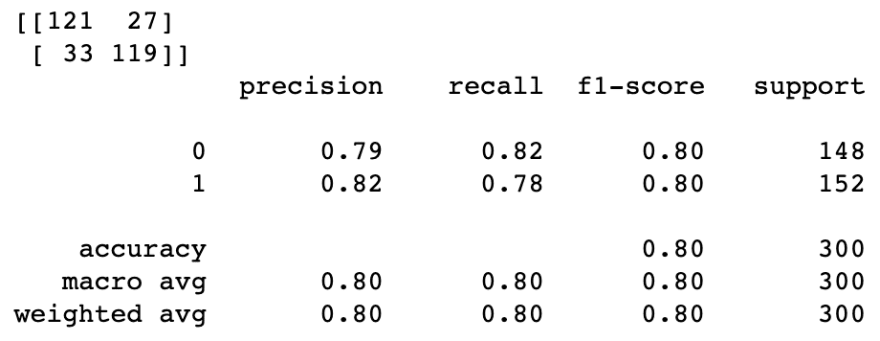
from sklearn.metrics import confusion_matrix, classification_report
print(confusion_matrix(y_test, preds))
print(classification_report(y_test, preds))
Benefits of using KNN algorithm
- KNN algorithm is widely used for different kinds of learnings because of its uncomplicated and easy to apply nature.
- There are only two metrics to provide in the algorithm. value of
kanddistance metric. - Work with any number of classes, not just binary classifiers.
- It is fairly easy to add new data to algorithm.
Disadvantages of KNN algorithm
- The cost of predicting the
knearest neighbors is very high. - Doesn't work as expected when working with a big number of features/parameters.
- Hard to work with categorical features.
A good read that benchmarks various options present in sklearn for Knn
Hope you liked the post. Feel free to share any issues or any questions that you have in the comments on the original article.

{kind=link}
Top comments (1)
Your blog post on KNN is incredibly insightful! The way you explained the intuition behind the KNN algorithm and provided practical examples makes it easy for beginners to understand.
I also write a blog on KNN please visit it and provide your valuable thoughts: - KNN