This post was originally posted in the newsletter GitBetter. If you are interested in leveling up your game in Git, you can subscribe to it
Before talking about Git, let’s talk about version control. Version control is a system that keeps tracks of changes to any source like files, folders, images, or anything digital at a particular point of time. So that you can visit those changes later.
Types of Version Control
So the first type of Version control that was used was Local Version Control. As the name specifies, these types of systems are present only in the dev’s local machine, s/he can’t share the system with other peers. This is the very basic version of version control systems.
With the Local version control, the cons are very clear. Devs can’t collaborate with others. This was initially solved by Centralized Version Control systems. These systems have a common database that has all those changes. So at any point in time, anyone can get the latest version of the code and the collaboration was also easy. But one downside is that what will happen if multiple people are working on the same file and pushed them. So someone has to manually resolve the conflict in the server. And another important issue is how to handle if the centralized server was down then no one can collaborate.
All the above cons are solved by the Distributed Version Control. This system has a server where all the version control history is maintained. And if someone wants to work on the project, then they take an entire snapshot or copy of the system in their local machine. In this way, everyone can collaborate with anyone who is working on the same project simultaneously. This is the big advantage of Distributed version control.
So, I think you would have guessed which type of Version control is used by Git. Of course, it’s Distributed version control.
So how Git was born

Git was written by Linus Torvalds and by the Linux community in 2005.
Long story short. Linux community was building an open-source Linux kernel. And they were using version control from BitKeeper. Later when the BitKeeper decided to make their tool a paid service, the Linux community decided to build their own tool. This is how Git was born. Git was made in mind to be simple, secured, fast, to be distributed, and also in handling larger projects.
How Git works
Git, unlike other systems, will think about data rather than changes. It means that, whenever there is a commit, Git takes a snapshot of the entire file system and bundle it. It won’t just save the file changes. This is a major difference.
Then Git uses a hashing mechanism called SHA-1 which helps Git to generate a checksum (a unique 40-char long string) based on the content of files and directory structure. So each commit in Git will have a unique hash with directly constitutes to the changes in the system. So there is no way to change the content without Git knowing it.
And if you are using Git for a while, you should know that it has three states.
- Modified - Some changes are there, but it’s not saved to the Git database yet.
- Staged - User has marked some files as changed. So it can be saved to the DB.
- Committed - The changed files are saved in the database.
As I said, for each commit, Git takes the entire snapshot of the file system. So How Git handles it.
You can take a look at the following image.
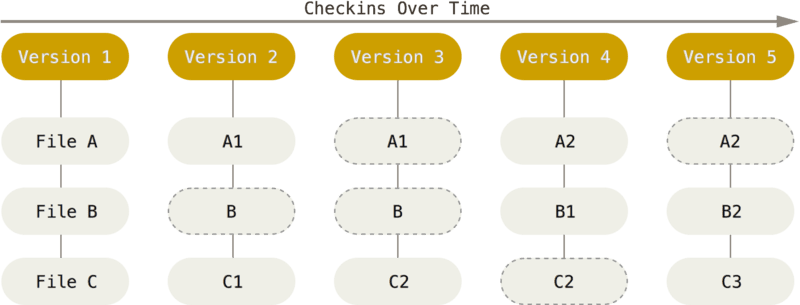
In the above image, it’s clear that Git gets the snapshot of all the three files (A, B, C) in all the versions.
In Version 2, File B hasn’t changed so Git will not save the file again, it will just point to the older version of File B (which is Version 1).
So only files that have changed are newly created in the newer version and all the unmodified files are just pointed back to the older version. This is one of the main distinguished factors of Git.
If you have come this much, then I think you are much interested in Git. You can subscribe to GitBetter to get tricks, tips, and advanced topics of Git.
Thank you for reading :)

Top comments (0)