Ever wondered about how retailers are doing

The answer is simple, Association Rule Learning. This technique is used by retailers across the globe to understand customer buying patterns by finding co-relation between the products that customers have bought.
Association Rule Learning involves two steps:
- Finding all frequent itemsets
- Generating strong association rules from the frequent itemsets
Finding frequent itemsets can be done either by using the Apriori algorithm or FP Growth algorithm. In this part, we will see how the Apriori algorithm works. Apriori works on the assumption that
"All nonempty subsets of a frequent itemset must also be frequent".
Here is the sample dataset consisting of 9 transactions containing items I1, I2, ..I5.

In order to have a proper understanding of association rule learning, it's better if we know the following metrics:
-
Support: Support of an item I1 is nothing but the number of transactions containing I1 to the total number of transactions
Support (I1) = Transactions containing I1 / Total transactions = 6 / 9 = 0.66 -
Confidence: How likely a customer is to purchase item I3 when I1 is purchased.
Confidence (I1 => I3) = Transactions containing both I1 and I3 / Transactions containing I1 = 4 / 6 = 0.66
Now that we are familiar with these terms, let's try to understand the apriori. For this example, I'm taking minimum support count = 2
Step 1: Find 1-frequent itemsets (all the items) and calculate their support counts (nothing but the number of times itemsets have appeared in our transactions)
Step 2: Compare each item support with the minimum support and remove the items having support less than minimum support. Here all the items satisfy the minimum support.
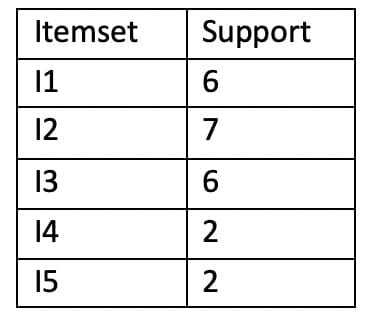
Step 3: From the result we got from table, find 2-frequent itemsets

Step 4: Compare each itemset support with the minimum support and remove the itemsets having support less than minimum support.

Step 5: From the result we got from table, find 3-frequent itemsets and calculate their support counts

Step 6: Compare each itemset support with the minimum support and remove the itemsets having support less than minimum support.

Step 7: From the result we got from table, find 4-frequent itemsets

Step 8: Compare each itemset support with the minimum support and remove the itemsets having support less than minimum support.
Repeat the steps until you get an empty set. Since the 4-itemset is not satisfying our minimum support count, we are not generating itemsets anymore.
Once the frequent itemsets are generated, now is the time to generate strong association rules from the itemsets. Association rules can be generated as follows:
- For each frequent itemset l, generate all non-empty subsets s
- For every non-empty subset s, output the rule "s => (l-s)"
For this, I'm taking minimum confidence value = 60%
Step 9: Generating all non-empty subsets of an itemset. Here, I am generating all non-empty subsets for an itemset {I1, I2, I5}

Step 10: Generating rules from the non-empty subsets
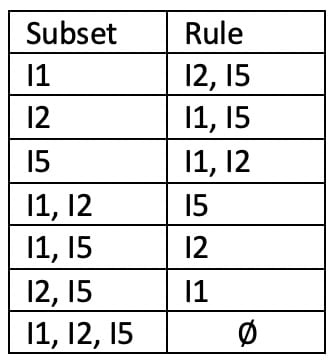
Step 11: Which rules to consider? For this, we have to take calculate the confidence value for each rule
Consider the first rule in the table I1 => I2∩I5
Confidence = Support count of (I1, I2, I5) / Support Count of I1
= 2 / 6 * 100 = 33.3%
Calculate the confidence for all subsets

After considering the minimum confidence value, rules 3,5 & 6 are strong rules for the itemset {I1, I2, I5}
Step 12: Take the itemset {I1, I2, I3} and follow-through steps 10 & 11
This series consists of
- Apriori algorithm working (Current Post).
- Python implementation of apriori.
- FP Growth algorithm working.
- Python implementation of FP growth.

Top comments (0)