
Original post: https://thanhle.blog/blog/write-lean-state-management
Why should you read this article?
- Improve your level of state management
- Code state in a leaner way
- There is another way to approach the problem on the frontend
I had a chance to meet a few friends when they first started working as a frontend and I found that most of them had the same problem: Writing logic in state management was too complicated, leading to code that was both confusing and difficult to debug.
Usually, after such reviews, I'm the guy who deletes all that code to have a leaner version, so hopefully, through this article, everyone will learn a few skills when writing state-management code.
UI = f(state)

Legendary Formula for Frontend Developer
State - the particular condition that someone or something is in at a specific time.
Cambridge
In a nutshell, the state of your application will be mapped through the respective UI through a mapping function. So, clean state management (now called clean state management) means designing the state in the application in a neat way to:
- Mapping via UI is easier 💨
- Less code means fewer bugs 🐹
- Less code means easier to maintain 😌
When does the state change?
To write a clean state, you must first find out what causes the state to change

In an application, there are 2 things that can change your state
- Event from user interactive with App
- Event from 3rd party (Here I define everything that triggers events into the app that doesn't come from the user as 3rd party, it can be a response from backend, an event from WebSocket, or... power outage, network failure. )
Normally, the flow of writing the state that I often see will follow a structure like this:
- Event is triggered (User or 3rd party)
- The code that handles that event get called
- Save the processed data to state
- UI render according to the new state
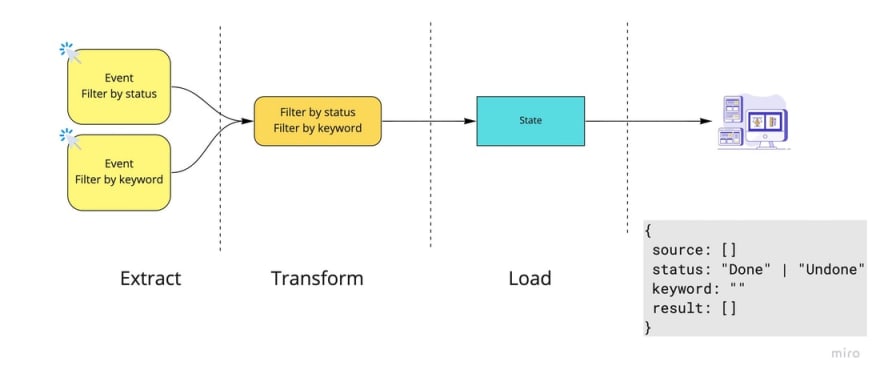
It is possible to re-example that flow in the case: Filter the list of Done tasks as follows
- User triggers filter done task
- Get event from user, filter the done task
- Save the result into state
- Render result into the UI
If people learn about the data maker, it will call this flow: ETL - (Extract - Transform - Load). You Extract data from the event, transform it into the required data, then load it into the state

ETL explained
What's the problem with doing ETL in the front-end?
When there are multiple events combined to produce the same UI output.
Imagine with the original Todo list example, I need to do more Search todo list features. Now our state will be
{
"source": [], // List todo raw
"status": "Done" | "Undone",
"keyword": "",
"result": []
}
Since most of the software build process will follow Agile, which means creating incremental by each iteration, the case of completing the todo list with the Done/Undone filter and then adding the feature search todo is a common thing ☺️ . Don't blame any guy for not telling you to do it from the beginning.
Now you will see it is quite simple:
- When users inputs search keyword
- Get the source data, filter by status, then filter again by keyword
- Then save it back to the state
Now Todo list will have the following 2 flows

Do you see the problem here? Flow filter by status will be wrong because it only filter by status and drops filter by keyword. You are new to the project, you only know the task to do is add more flow search by keyword, but you do not know that the old flows also change the output when adding a new state this is also understandable! You only care the flow you just did: Search by keyword!
Ok, I saw the bug 🤡 so now it's good to combine it into a function. After that, if you need to add filter by XYZ, put it in that function and it's done, how many QA guys come in and poke 😎.
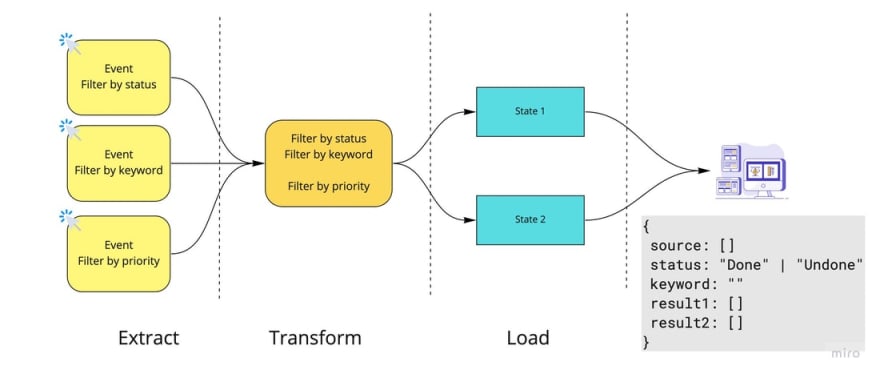
No, not that easy! Now add a case like this: In addition to the filtered todo list as required above, the user also wants to have an additional list containing only the todos whose priority is Important.
I'll call the flow I've been working on is flow 1 and the flow we gonna do next is flow 2
Now the flow code will look like in the picture. You need to calculate a new list to filter by priority according to the filtered results, there are 2 ways:

- Run the transform function again in the
flow 1. The downside is that this transform function has to be run twice - Get the results in State 1for further calculation. The downside is that your app will have to re-render 2 times, first rendering according to the first flow, then getting the results from state 1, and then running again with flow 2 leading to the 2nd rendering to get the desired results.
🚫 Don't try to attach Filter by Priority to flow 1 and always produce state 1 and state 2 because doing so will make your app even more confusing 🙃 because:
- The code is not self-explanatory to show the flow of the app well
Flow expects will be described: Get the output of the flow 1, filter by priority to get the flow 2 output. However, if you look at the code you combine both detailed processing of flow 1 and detailed processing of flow 2 into one function. Please don't
A good flow is one that clearly shows:
- What is the required input
- What is the desired output
- When will this flow be run
The problem in general

In general, you are handling the event independently, and for each UI need, you save a separate state for it. Doing so makes your code more difficult to extend, and also has to save more state like the example I mentioned earlier, but the more code, the more bugs 🐞
A better way with ELT (Extract - Load - Transform)
Now let's try to flip the steps between load and transform. Instead of transforming and then load it to the state, we can do the opposite. Load the state first and then transform it to render the UI

At this point, have you noticed that our state is a billion times more compact? By changing the order of running the flow, namely the transform to the last step and then taking that output to render to the UI, I don't need to save anything.
Let's go back to the original example and see it:
-
Flow 1, when users trigger an event filter by status or filter by keyword, save event data status or keyword into the state. Then there is a transform function with input as- Source data
- Status
- Keyword
Every time one of the 3 inputs of the state above changes, the render function will run again transform function will calculate new result UI is updated
-
Flow 2, when the user has an event filter by priority. There will be a transform function corresponding to the input- Priority
- The output of transform function in the
flow 1
Very clear without sacrificing performance right?
FAQ
-
Performance? Every time the app renders, does the transform function rerun as well?
As I said above, the state of the app only changes when an event is fired. So whether you run the transform function when there is an event and then save the result to the state or save the state and run the transform, it makes no difference, you have to run the transform again.
So what if an unrelated event causes the component to re-render ⇒ it has to run the transform function again while the input of that transform function doesn't change anything?
I find it's easy to fix if you use it
react, put it inuseMemowith the dependencies as the listinputof the transform, invueit's even more easier, just put it intocomputedand now you done. If you use other frameworks, the keyword to solve ismemorized function -
Is it possible to scale in a large application?
Yes, absolutely! Imagine that source data is unique - a source of trust, any component that consumes data will have a different way of looking at that data.
For eg: Todo list is the source of trust that is saved from the backend. The Todo component will filter from that source of trust Undone tasks. The history component will filter from that source of trust past tasks.
So each component will have a different way of viewing data, and that view will, along with the component's lifecycle, be created when the component is created and deleted when the component is destroyed.
-
isloading?To put it simply, there are 2 events that will change
isLoading. The first is the user triggering request, and the other is when the response returns the result. This is a sub-state to represent the UI. And certainly, this type must be saved, but this type of state usually has nothing to do with other UI outputs, so I'm still ok when I put it in the state. Actually, I don't know any other way to handle these cases -
State normalization is better?
Actually, it's not very relevant, state normalization is a way to deal with redundancy in the state. So it blends well with ELT. Now the flow will be ETLT
- Extract - data from API (Run once)
- Transform - normalize data (Run once)
- Load - save to state (Run once)
- Transform - depending on how the component consumes state, transform the way it wants
Summary
The change from ETL through ELT will make your code lean more and this also changes the Mindset of physician employment state: From thinking how to handle the event to ***the calculated output based on the current state (Computed state)*
Applying ELT is super simple, just apply the spell.
🪄 Only save the data coming from the event to the state, and do not save anything else in the state.
Original post: https://thanhle.blog/blog/write-lean-state-management

Top comments (0)