
This post is not a tutorial. I omitted a lot of implementation details to keep it as short as possible.
I play Ultimate once a week. It's a sport I really enjoy. One stupid thing I struggle with is remembering what time this week's game is. My local Ultimate organization has this website where I can log in and see all that stuff, but the "remember me" feature of the login page, actually doesn't remember me at all.
So, as a classic lazy ass developer, I saw an opportunity to turn this irritant into a neat lifehack experiment.
What I want
So I have this HTML table with all games on the schedule. What I want is to have it all in an ICS file that would ideally:
- update itself automatically
- be served on the web so I can subscribe to it
Pick the tools
I chose Apify for data scraping. This product allows you to crawl pages, extract data from them, and expose this data through an API endpoint.
To crunch that data into ICS files, I decided to use Azure Function as my serverless platform.
The files generated are stored in Azure Blob Storage.
Collect the data
So, the table looks like this:

Now, I won't go to great lengths to explain how Apify works. Just know that once I figured out how to setup crawler login and cookies retention, I was able to setup the start/pseudo URLs and clickable elements. What I needed to do after that was to code what they call the "page function", i.e. the function that extracts the data on each page crawl. It looks like this :
function pageFunction(context) {
var $ = context.jQuery;
var req = context.request;
var result = null;
function getTeam(row, order) {
var teamLink = row.find("td.team a");
var team = {};
team.name = $(teamLink[order]).text();
team.url = "http://www.ultimatequebec.ca" + teamLink.attr("href");
return team;
}
function getPlace(row) {
var placeLink = row.find("td.place a");
var place = {};
place.name = placeLink.text();
place.url = placeLink.attr("href");
return place;
}
var calendar = req.loadedUrl.match(/calendriers/);
if (calendar) {
var games = [];
var date = "";
$("table.calendar").each(function () {
$(this).find("tr").each(function (index) {
if (index === 0) {
date = $(this).text();
return;
}
var row = $(this);
var game = {};
game.date = date;
game.hour = row.find("td.hour").text();
game.place = getPlace(row);
game.team1 = getTeam(row, 0);
game.team2 = getTeam(row, 1);
game.url = "http://www.ultimatequebec.ca" + row.find("td:last-child() a").attr("href");
games.push(game);
});
});
result = {
games: games
};
}
return result ? result : {};
}
Pretty ugly basic jQuery bits, right?
Once the crawler has run, its results API endpoint returns the scraped data as expected:
"games": [
{
"date": "lundi, 09 avril 2018",
"hour": "19h30",
"place": {
"name": "Marc-Simoneau, C- Bord",
"url": "https://www.google.ca/maps/place/Centre+sportif+Marc-Simoneau/@46.8616686,-71.2080988,15.5z/data=!4m5!3m4!1s0x0:0x30df80932f5ceacb!8m2!3d46.8617603!4d-71.209124"
},
"team1": {
"name": "Cut in the End Zone",
"url": "http://www.ultimatequebec.ca/members/teams/cut-in-the-end-zone"
},
"team2": {
"name": "Les muppets",
"url": "http://www.ultimatequebec.ca/members/teams/cut-in-the-end-zone"
},
"url": "http://www.ultimatequebec.ca/members/games/14332"
}
]
I configured the crawler to run twice a day, so I can have fresh data all the time.
Great! Now, how about some data crunching?
Transform the data
Since Azure Function now runs .NET Core 2.0, I decided to give it a shot. I took the approach of creating a function as a class library.
It is triggered by POST HTTP calls. The Apify crawler has a webhook configuration that pokes the function at the end of each successful run.
Once again, I spare you the ins and outs of the implementation, but the function's Run method looks like this :
public static async Task Run(
[HttpTrigger(AuthorizationLevel.Function, "post")] HttpRequest req,
[Blob("uq-schedule", Connection = "TFD_STORAGE")] CloudBlobContainer container,
TraceWriter log)
{
var teamsDict = new Dictionary<string, GameCalendarWriter>();
var fullScheduleBlob = container.GetBlockBlobReference("uq-full-schedule.ics");
var fullScheduleBlobStream = await fullScheduleBlob.OpenWriteAsync();
var apiToken = FunctionHelpers.GetEnvironmentVariable("TFD_APIFY_TOKEN");
var userId = FunctionHelpers.GetEnvironmentVariable("TFD_APIFY_USERID");
IApifyClient apifyClient = new ApifyClient(apiToken, userId);
var result = await apifyClient.GetLastRunResultsAsync("ultimateqc_schedule");
var games = result
.Where(r => r.PageFunctionResult.Games?.Any() ?? false)
.SelectMany(r => r.PageFunctionResult.Games)
.ToList();
using (var fullCalendarWriter = new GameCalendarWriter(fullScheduleBlobStream))
{
foreach (var game in games)
{
await fullCalendarWriter.WriteGame(game);
await (await GetTeamWriter(container, teamsDict, game.Team1)).WriteGame(game);
await (await GetTeamWriter(container, teamsDict, game.Team2)).WriteGame(game);
}
}
foreach (var writer in teamsDict)
writer.Value?.Dispose();
}
This piece of code will generate a global ICS file of all games across all teams, as well as one for each team. All these files will be stored in an Azure Blob Storage container, accessible publicly by their URLs. Here's a snippet of what I get :

Finally, subscribing
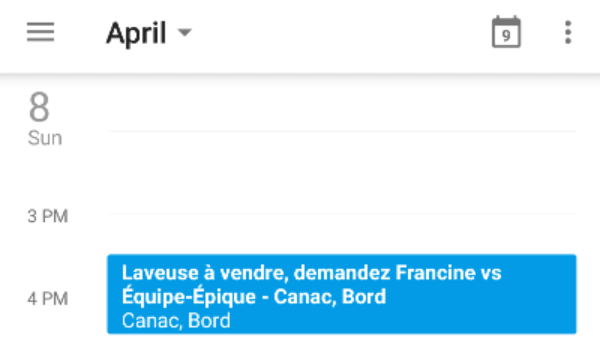
I can now log into my Google Calendar and subscribe to my team's ICS file via its URL. Google will keep up to date with changes to that file's content.
I'm all set! I now have access to all my upcoming games in my calendar app. I can setup custom reminders and live a happier, lazier life!
Thanks for reading, hope you enjoyed it :)
English is my second language, so please tell me if you spot a typo, a grammar error or anything that could make this post hard to read. I'm constantly trying to get better at it.

Top comments (0)