Disclaimer! I am a student learning Datascience, Machine Learning. What I write here might have mistakes, do point them out in comments or reach out directly to me at my linkedin account.
What is K-Means Clustering?
k-means clustering is a method of vector quantization, originally from signal processing, that aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean (cluster centers or cluster centroid), serving as a prototype of the cluster. This results in a partitioning of the data space into Voronoi cells. - Wikipedia
If you did not understand this wikipedia definition like me, let me explain it in simpler terms.
In K-means clustering we divide n number of observations into k groups/clusters in such a way that the observations similar to each other are linked in one group.
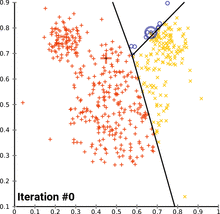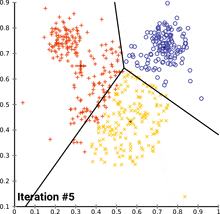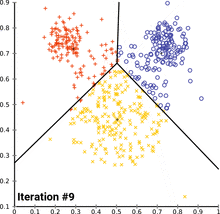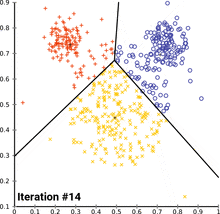
Image Credits: Wikipedia
Steps for K-Means Clustering
- Decide the value of k, which is the number of groups to divide your observations into.
- Select k random points C (aka centroids) for each cluster within your observations.
- Calculate absolute difference of each point from all centroids.
|X-C| - Put the observation in the cluster which has the closest centroid.
- Calculate new centroid for each cluster by taking average of all observations in that cluster.
- Repeat step 3-5 until the centroids stop changing.
- You have successfully organized n observations in k clusters.
I have also written the python code from scratch to implement k-means clustering for n-clusters, it currently works for 2-4 clusters(limited color values) but sometimes goes into infinite loop. if given n values of colors, it can work for n clusters
Github: https://github.com/TheAli711/datascience/tree/main/k-means-clustering
See you guys in the next article :)

Top comments (0)