![Cover image for Reduce Rebalance Downtime (by x450) for Stateless Kafka Streams Apps [Simple Steps]](https://media2.dev.to/dynamic/image/width=1000,height=420,fit=cover,gravity=auto,format=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fuploads%2Farticles%2F3r2gpr1bojlha51dqadz.png)
In this post, we’ll learn how Kafka Streams Consumers behave differently from regular Kafka Consumers, the consequences for the application, as well as steps to minimise downtimes in event processing when consumer group members change.
With the default configuration, a containerised stateless Streams app pauses processing for >45s when one app instance (group member) is removed or restarted.
For real-time data streaming workloads with a low e2e latency as an NFR (non-functional requirement), such a long ‘rebalance downtime’ often is unacceptable.
Fortunately, there’s a simple yet efficient solution to address this problem.
(i) As a bonus, we will look under the hood of Kafka Consumer Groups, the Group Coordinator & Rebalance Protocol, and measure, analyse and evaluate a simulation of a group member (replica) re-creation running on Kubernetes.
...TLDR? here's a spoiler:
props.put("internal.leave.group.on.close", true);
Theory
Regular Consumer Behaviour
Let’s briefly recap on Kafka Consumers and Consumer groups.
An Apache Kafka® Consumer is a client application that subscribes to (reads and processes) events.
A consumer group is a set of consumers which cooperate to consume data from some topics. The partitions of all the topics are divided among the consumers in the group. As new group members arrive and old members leave, the partitions are re-assigned so that each member receives a proportional share of the partitions. This is known as rebalancing the group.
(…) One of the brokers is designated as the group’s coordinator and is responsible for managing the members of the group as well as their partition assignments.
(…) When the consumer starts up, it finds the coordinator for its group and sends a request to join the group. The coordinator then begins a group rebalance so that the new member is assigned its fair share of the group’s partitions. Every rebalance results in a new generation of the group.
Each member in the group must send heartbeats to the coordinator in order to remain a member of the group. If no heartbeat is received before expiration of the configured session timeout, then the coordinator will kick the member out of the group and reassign its partitions to another member.
(Source: Kafka Consumer | Confluent Documentation)
When a consumer leaves a group due to a controlled shutdown or a crash, its partitions are reassigned automatically to other consumers. Similarly, when a consumer (re) joins an existing group, all partitions are rebalanced among the group members. This dynamic group cooperation is facilitated by the Kafka Rebalance Protocol.
For a rebalance scenario where one instance is stopped, the Consumer sends a LeaveGroup request to the coordinator before stopping (as part of a graceful shutdown, Consumer#close()), which triggers a rebalance.
During the entire rebalancing process, i.e. as long as the partitions are not reassigned, consumers no longer process any data. Fortunately, rebalancing is very fast, typically between anything from 50ms to seconds. It may vary depending on different factors, such as load on your Kafka cluster or the complexity of your Streams topology (no. of input topics, streams tasks := partitions, and state stores, … -> total no. of consumers).
!= Streams Consumer Behaviour
For Kafka Streams, some config properties are overridden via (StreamsConfig.CONSUMER_DEFAULT_OVERRIDES). One of those properties is "internal.leave.group.on.close", set to false (enabled by default for regular Consumers).
Please note it’s a non-public config, which may change without prior notice with new releases.
Reference: ConsumerConfig.LEAVE_GROUP_ON_CLOSE_CONFIG.
This means Consumers will not send LeaveGroup requests when stopped but will be removed by the coordinator only when the Consumer session times out (ref. session.timeout.ms).
The default Consumer session timeout is 45s (note: was 10s before the Kafka 3.0.0 release, ref
KIP-735). Consequently, no data is processed for more than 45 seconds for tasks assigned to the Consumer that had been stopped.
It even worsens if a new Consumer (re) joins the group while suspected dead (no more heartbeats received), where all consumers shut down, and task assignment is blocked until the timeout is exceeded. The coordinator evicts the old Consumer that had been stopped from the group. Until then, processing comes completely to a halt for all tasks, also known as ‘stop-the-world’ rebalancing. While the ‘incremental cooperative rebalancing protocol’ introduced with Kafka 2.5 avoids ‘stop-the-world’ rebalancing for regular Consumers, the mentioned Kafka Streams overrides nullify some aspects.
Example Scenario: Kubernetes Pod Evicted … and Replaced
Running your apps on Kubernetes takes a long way to achieve a robust, highly-available deployment. Kubernetes monitors your containers’ health, allows you to scale, and ensures all desired replicas are up and running according to your spec.
But still, to be truly elastic and minimise downtime of your data stream processing, your application must be able to handle Pods (/container) to be restarted, evicted, and re-created gracefully.
There are many potential causes, e.g. application upgrades (CI/CD), k8s cluster security patching, (auto-)scaling, resource shortage, or k8s nodes running on Spot instances being interrupted.
Next, we look at a simple yet common example.
Example infrastructure setup: Stateless Kafka Streams app, 6 streams tasks, running on Kubernetes as Deployment, with 3 replicas.


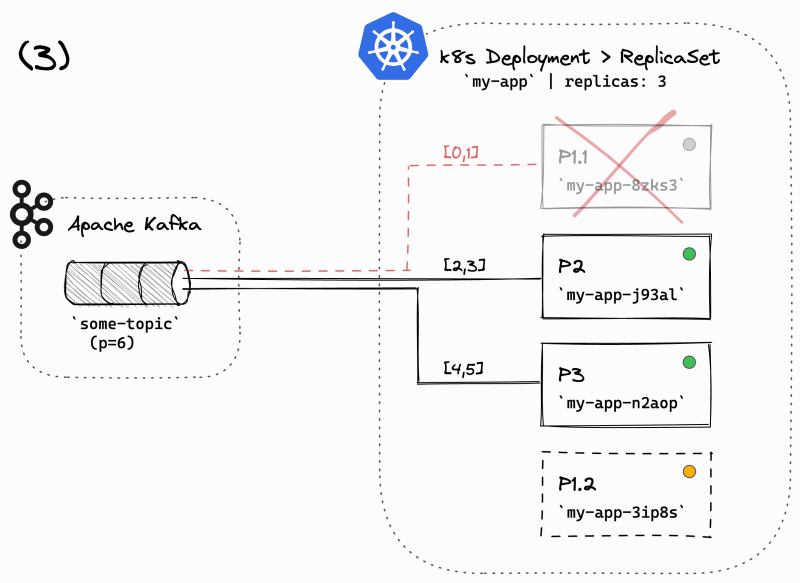

Scenario: One pod is terminated and successively replaced.
- Initial state, all 3 pods are running & healthy, the streams app is processing, balanced task assignment
- Pod (P1.1) terminated (deleted) by k8s, shutting down gracefully
- A replacement Pod (P1.2) is scheduled & placed
- Final state, the replacement Pod is running & healthy, the streams app is processing, balanced task assignment
I would like to share a screenshot depicting the consumer lag metrics, rendered in Grafana, for a simulation of our scenario.
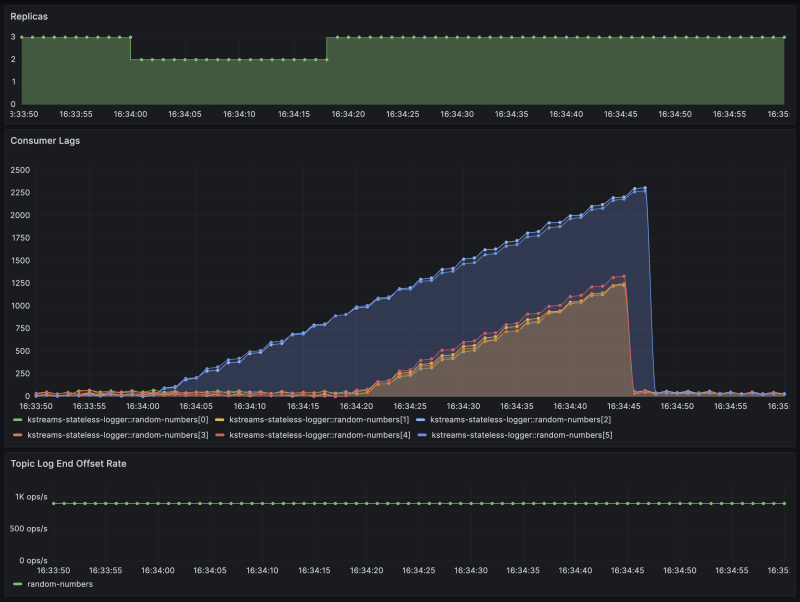
Let’s walk through the results and explain the behaviour:
-
18:34:00: the Pod (P1.1) is terminated and stops processing. The consumer lag of partitions
[1,4]starts to build up -
18:34:20: the replacement Pod (P1.2) has come up; the streams task sends a
JoinGroupto the group coordinator - 18:34:21: rebalancing triggered, assignments revoked, pauses - due to no heartbeats received from (P1.1)
- 18:34:21: all consumers pause processing, waiting for assignment; lag starts to build up for all partitions
- 18:34:45: rebalancing continues, new assignment, processing continues
- 18:34:48: all consumers caught up; consumer lags are back to healthy jitter
To better illustrate everything that is happening over time, here’s a time bar diagram highlighting all important steps:

Here are the belonging application logs for the rebalancing, which occurred at 16:34:44.988 and took 92ms.
2023-06-17 16:34:44,988 INFO State transition from RUNNING to REBALANCING
2023-06-17 16:34:45,080 INFO State transition from REBALANCING to RUNNING
So we can conclude the following downtimes:
- partitions
[2,5]: 48s - partitions
[0,1,2,3,4]: 25s While the actual rebalancing took only 92ms.
😵 Wait, 48s? Really???
Depending on your stream processing use case, 45s+ downtime might be no big deal, but for real-time low-latency data streams, it’s a massive breach of the NFR.
So let’s see what options we’ve got to mitigate:
Option 1: Lower consumer session timeout
Since the session timeout determines the downtime, one way to mitigate is to reduce session.timeout.ms.
Don’t forget to decrease the value of heartbeat.interval.ms to ensure three heartbeats plus a buffer can fit within the timeout period.
session.timeout.ms=6000
heartbeat.interval.ms=1500
Read the config here: Kafka Consumer Configurations
Option 2: Enable ‘leaveGroupOnClose’
…but why work with timeouts when it’s perfectly valid to have your stateless Streams Consumers notify the coordinator when closing down?!?
To enable ‘leaveGroupOnClose’ (overriding the override 😜), configure your Kafka Streams app with following property:
internal.leave.group.on.close=true
Warn: Please note it’s a non-public config, which may change without prior notice with new releases.
Reference: ConsumerConfig.LEAVE_GROUP_ON_CLOSE_CONFIG.
Re-do the Example with ‘leaveGroupOnClose’ 🚀
Drum roll 🥁 … and here, without further ado, the results:
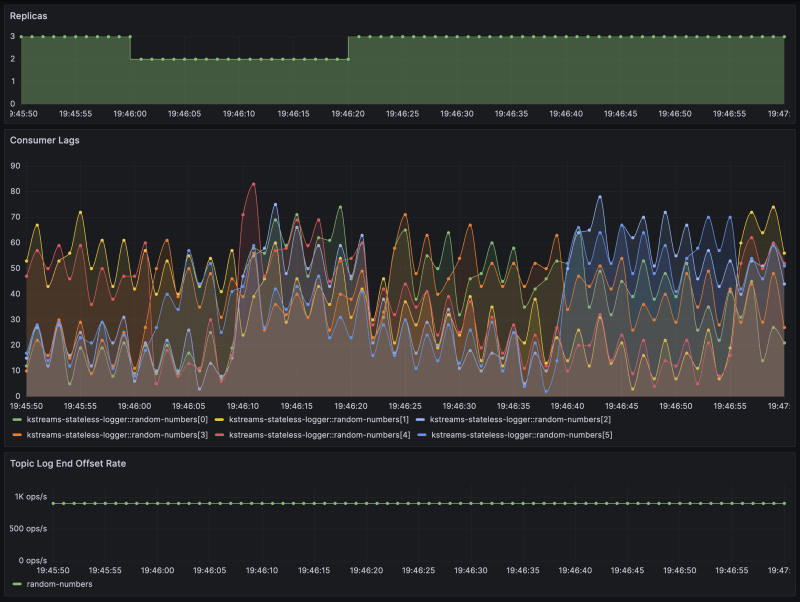
As we can (not) see - the two rebalancings complete so fast that there's not even the slightest consumer lag increase visible in the metrics.
Here’s the visual explanation:

Finally, here are also the application logs showing the timings of the rebalancing, which happened twice. One at 17:46:00.332 that took 92ms, and the other at 17:46:21.361 in 98ms.
2023-06-17 17:46:00,332 INFO State transition from RUNNING to REBALANCING
2023-06-17 17:46:00,424 INFO State transition from REBALANCING to RUNNING
2023-06-17 17:46:21,361 INFO State transition from RUNNING to REBALANCING
2023-06-17 17:46:21,458 INFO State transition from REBALANCING to RUNNING
Pro Tips
Stateless <> Stateful
This post recommends setting internal.leave.group.on.close=true for stateless (!) Kafka Streams applications.
Before implementing internal.leave.group.on.close=true for stateful applications, it is crucial to understand all potential consequences.
Info: Unfortunately, my evaluation using internal.leave.group.on.close=true in combination with standby replicas was not very promising.
The expected fluent task re-assignment to hot standby while one replica "restarts" - and subsequent re-distribution of tasks, does not work.
The Kafka Streams specific HighAvailabilityTaskAssignor has known issues such as uneven task assignment, frozen warmup tasks ('task movement'), and not recognising caught-up standby tasks when the consumer group changes.
Please note there are plans to address those issues with the next version of the Consumer Rebalance Protocol (see footnotes).
Often the best plan to keep downtimes low during rebalance for stateful apps is to stick with RocksDB + StatefulSet + PersistentVolumes + restart within (!) the session timeout
=> re-join with previous assignment, re-use RocksDB state, and avoid rebalancing entirely...
Tip: Alternatively, take a look at kafka-streams-cassandra-state-store, introduced in an earlier blog post.
k8s Deployment .spec.minReadySeconds
Frequently rebalancing within a short timeframe can cause consumer delays and strain the Kafka cluster.
If your application/container has a quick restart time, such as when running as a GraalVM native executable, it’s worth considering the use of .spec.minReadySeconds to maintain control and ensure upgrades occur in a controlled manner. This will help prevent frequent rebalancing within a short timeframe.
Conclusion
By configuring your Kafka Streams app with internal.leave.group.on.close=true, a graceful shutdown immediately triggers a rebalancing process and tasks are re-assigned to other active members within the group.
The processing downtime is significantly reduced while also improving elasticity and resilience. As a result, your applications enables interruption-free CI/CD and can be auto-scaled.
Please note that this recommendation only applies to stateless streams applications.! Tread carefully for stateful topologies, and do your homework!
Remember that internal.leave.group.on.close is a non-public config, which may change without prior notice with new releases. Always check the source code for changes when upgrading the Kafka Streams dependency.
Footnotes
- When writing this blog post, the latest version of kafka-streams was 3.4.1.
- There’s a ticket KAFKA-6995 from June 2018 proposing to make the config public. The ticket is closed as ’Won’t Fix’. Concerns of the core developer team can be found in the discussion.
- Looking into the crystal ball: A Kafka Design Proposal (KIP) is in progress to introduce a new group membership and rebalance protocol for the Kafka Consumer and, by extensions, Kafka Streams. => KIP-848: The Next Generation of the Consumer Rebalance Protocol
- It was also introduced on Current 2022: The Next Generation of the Consumer Rebalance Protocol With David Jacot | UK
- The application + docker-compose setup that was put together for this article can be found on the thriving-dev GitHub Organisation: :icon{name="mdi-github" class="inline -mt-0.5 w-6 h-6"} https://github.com/thriving-dev/kafka-streams-leave-group-on-close
- Many thanks to @MatthiasJSax for proofreading the blog post! 🙇
References and Further Reading
- Kafka Consumer Group Rebalance (1 of 2)
- Kafka Consumer Group Rebalance (2 of 2)
- Kafka-streams delay to kick rebalancing on consumer graceful shutdown - Stack Overflow
- Cooperative Rebalancing in the Kafka Consumer, Streams & ksqlDB
- Apache Kafka Rebalance Protocol, or the magic behind your streams applications | by Florian Hussonnois | StreamThoughts | Medium
- KIP-812: Introduce another form of the
KafkaStreams.close()API that forces the member to leave the consumer group - Apache Kafka - Apache Software Foundation
This post was originally published on Thriving.dev.

Top comments (0)