
If you’ve built anything with LLMs in the last couple of years, you’ve built a RAG pipeline. Embed the query, search a vector store, stuff the top chunks into a prompt, let the model talk. It’s the “Hello World” of grounding LLMs in real data – and for a long time, it was enough.
It isn’t anymore.
The moment your use case involves multi-hop reasoning, tool calls, or relationships between entities scattered across thousands of documents, naive RAG starts cracking. That’s given rise to two evolutions worth understanding deeply: Agentic RAG and Graph RAG. They solve different problems, and confusing them will cost you weeks of rebuilding. Let’s walk through all three, step by step.
1. Classic RAG: Fast, Simple, and Blind to Nuance
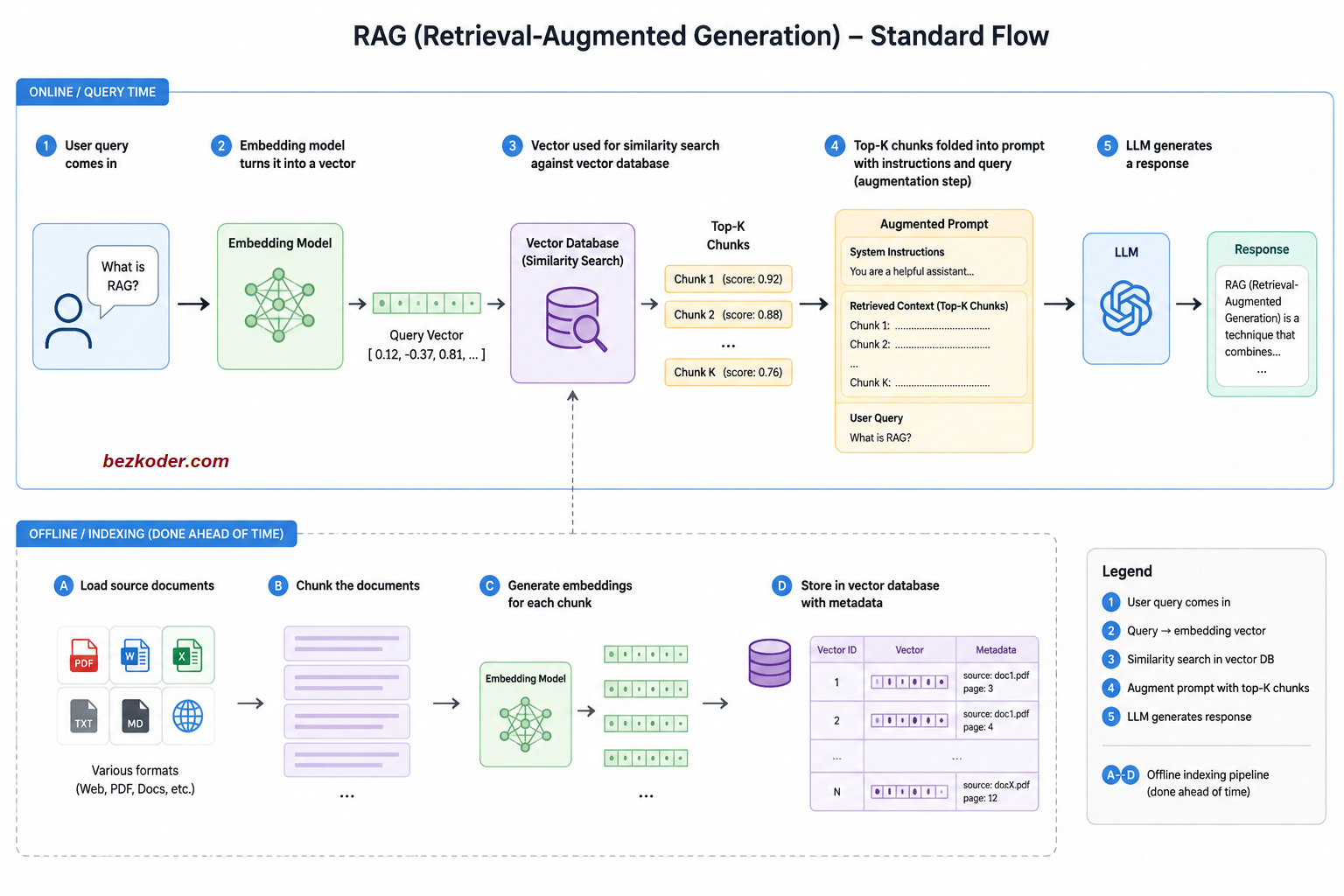
The original recipe is almost suspiciously simple:
- User query comes in.
- An embedding model turns it into a vector.
- That vector is used for a similarity search against a vector database that was populated ahead of time through offline indexing (your documents, chunked and embedded, sitting in an index with metadata).
- The system pulls back the top-K chunks - the pieces of text that are mathematically "closest" to the question.
- Those chunks get folded into a prompt alongside the system instructions and the original query - this is the augmentation step.
- The LLM generates a response from that augmented prompt.
That's it. One pass, no branching, no second-guessing. It's a straight line from question to answer.
The appeal is obvious: it's cheap, it's fast, and it's predictable. The catch is also obvious once you've used it long enough - it has no idea whether the chunks it retrieved are actually good. If the top-K results are irrelevant, outdated, or simply insufficient to answer the question, the pipeline has no mechanism to notice or correct course. It retrieves once and commits, for better or worse.
This works beautifully for narrow, well-scoped knowledge bases - internal FAQs, product docs, single-source Q&A. It starts falling apart the moment a question needs judgment about what to retrieve, or needs more than one source to answer properly.
2. Agentic RAG: Giving the Pipeline a Brain (and a Loop)
Agentic RAG doesn't replace the retrieval step - it wraps it in decision-making. Instead of a straight line, you get a loop with actual agents making choices along the way.
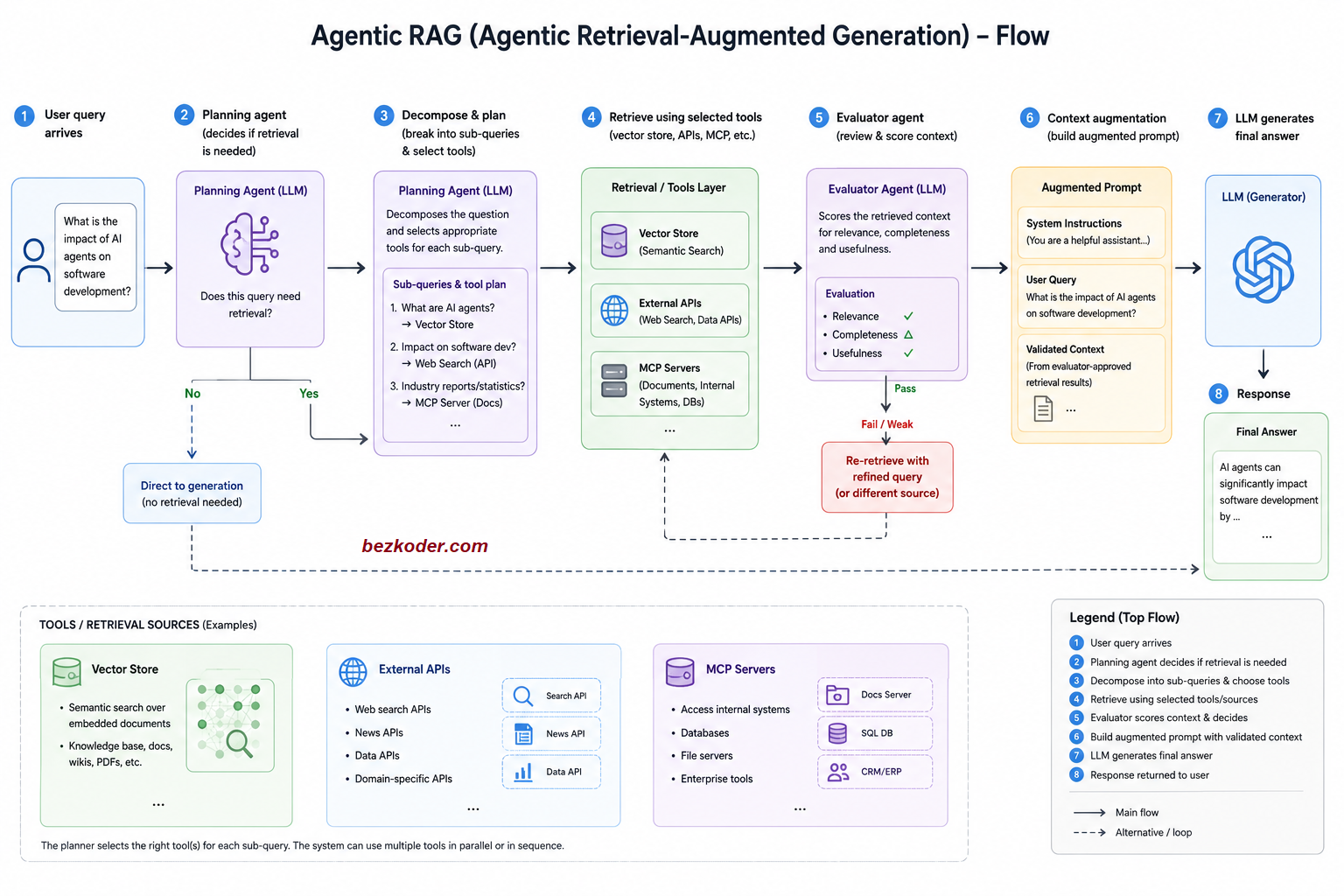
Read more:

RAG vs. Agentic RAG vs. Graph RAG: Which One Actually Fits Your Use Case? - BezKoder
A breakdown of three retrieval architectures: RAG, Agentic RAG, Graph RAG - why "just add RAG" stopped being good enough advice a while ago
 bezkoder.com
bezkoder.com

Top comments (0)