What a beautiful code I just finish to create… Let’s skip the tests… Put it in a Prod environment and hope for the best. Booommmmmmmmm!
Well, not so frequently nowadays, but, in a rush, is still happening, right!? You don’t need to answer… Even though you tend to say that it’s a lie, it still happens. I know!
To get even worst, the above, it’s quite complex to anticipate the process concurrency on the SQL side when our queries are being triggered from Business Central, but let’s give you an example of how to mitigate these potential locking issues, pandemic is affecting us in so many ways :), and help you with some examples where you can avoid, or at least investigate if your code is the one increasing the locks on the Prod Environment.
Business Central is a friendly environment for the developers, if you look at the queries that it generates and request to the SQL side, you’ll be able to see frequently on data consults/reads, the (WITH READUNCOMMITTED) that allows dirty reads of data, even that you are with any locking transaction affecting the table that you’re reading. The NOLOCK, with argument, is the equivalent to the READUNCOMMITTED.
Let’s see an example of it…
Imagine that I want to log some integrations executions on my business central solution and I’ve created the following table structure to store my data.
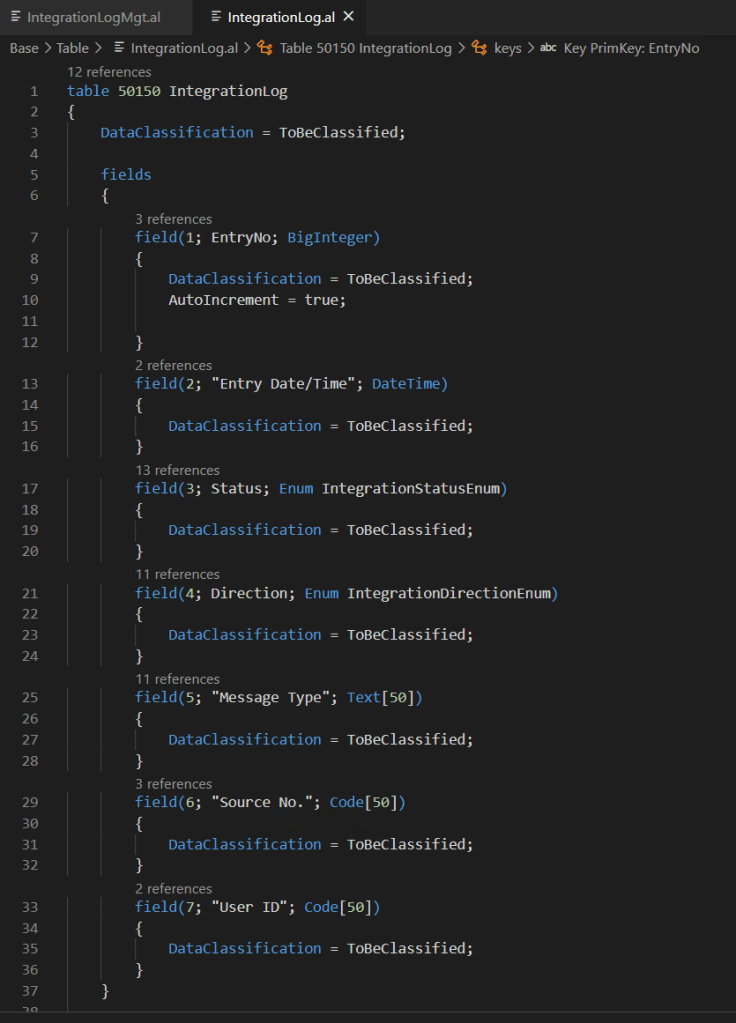
Table Structure
Attached to this table object, I’ve created a listing page to show the data on it, and a codeunit with some functions to manipulate the data and “imitate” common data processing on this sort of table/entity.
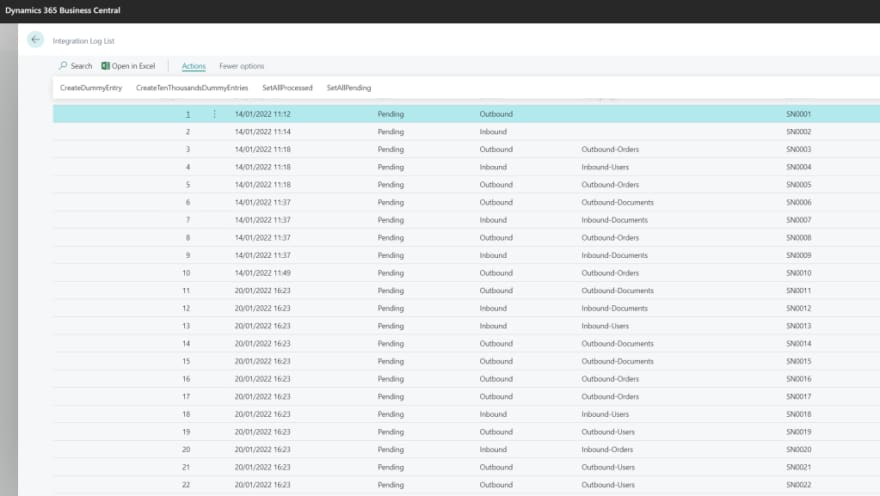
Page View – with some actions
I have now my scenario prepared and I have added, through the functions attached to my page, a big combo of entries to increase my available dataset.
Potential scenario:
I have this dataset and I have set a job to process these pending entries. This job will look for datasets based on Direction, Message Type, and Status fields. To simulate this potential scenario I have created the following procedure.
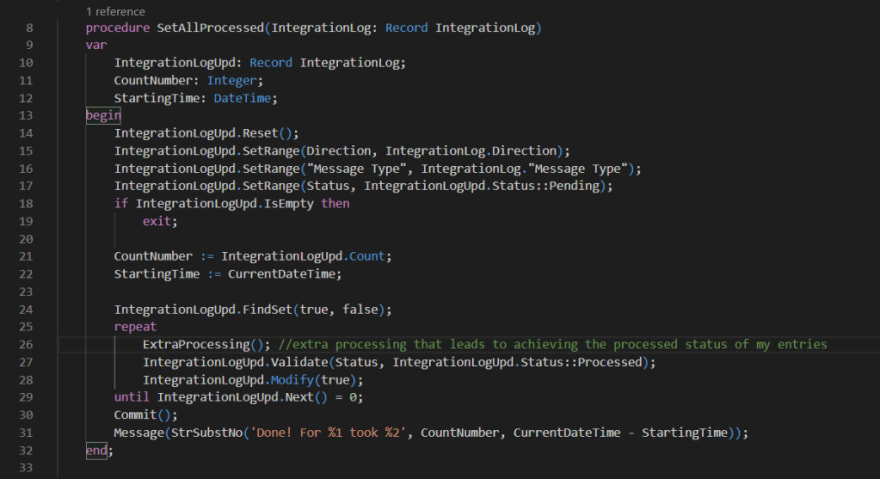
Set All Processed – Procedure
If you look carefully at my procedure, you’ll be able to see that I’ve used the Findset method with the boolean ForUpdate parameter set as true. It’s a fact that I’m intended to update my data, so should be harmless to use, isn’t it?
In all the deals, we should always pay attention to all the small letters, to avoid surprises, and even that in here they are not in small size, the letters of course, if you look carefully on the Microsoft documentation for Findset parameters you’ll find that if the ForUpdate parameter is set to true, promising us that will reach the optimal performance for our loop, but in parallel, the parameter will immediately run the LOCKTABLE method.
Now, let’s see this in action… I’ve chosen an entry and I’ve triggered for the first time the SetAllProcessed action. Let’s see the results:
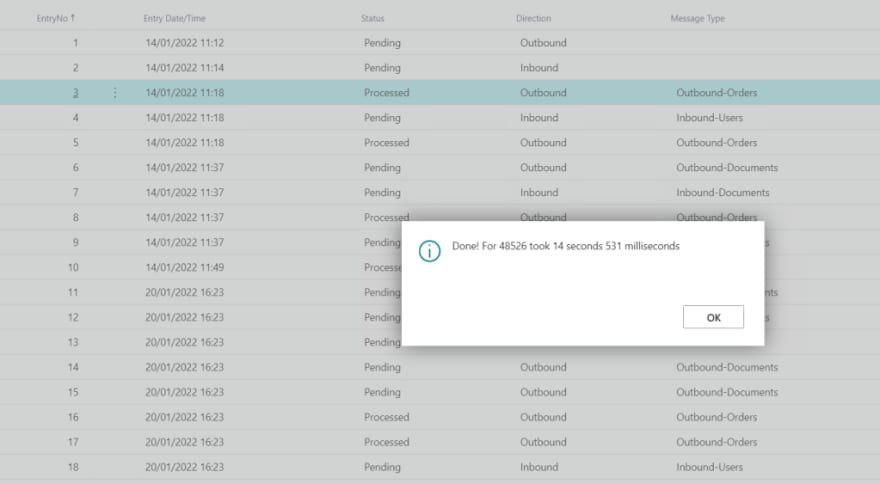
Since the LOCKTABLE method was active on our loop what will happen if we query our table on the SQL side in the meantime?
SELECT * FROM [CRONUS$IntegrationLog$a84606c8-7725-4ecb-9237-4fb9bd1bf179]
The above code execution will be waiting until the Business Central SetAllProcessed action be completed because is blocked by the lock established for this table/entity. As proof of it, see the following result from sp_who2 SQL procedure.

Here is where Business Central is a friendly environment to the developer, let’s perform the same query, during SetAllProcessed action, but this time invoked by the Business Central, or more precisely from PowerShell… I’ve used this approach to have other session requesting processes actions on the table IntegrationLog. For that, I’ve created the following procedure and the following PowerShell script.
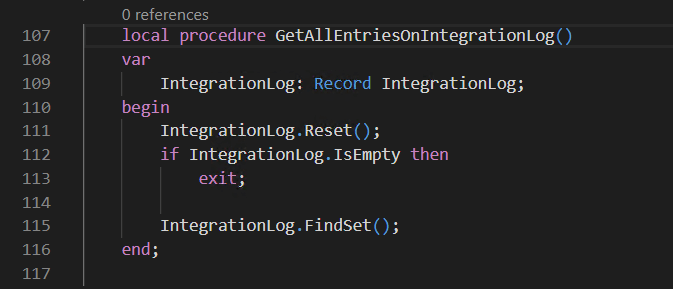
Get All Entries On Integration Log – Procedure
If you look for the SQL query created for the above invocation you’ll find that no lock occurred because…

The READUNCOMMITTED is part of your business central query.
The read is tested and it is “protected” against locks, which could potentially lead to other problems, like updating different data images, of the same entries on different transactions, but there is where Optimistic Concurrency will help the day… Another subject for another post.
Potential lock:
Now, what will happen if, instead of reading data we try to update entries during SetAllProcessed action execution? Let’s give it a new test, this time using the following two procedures…
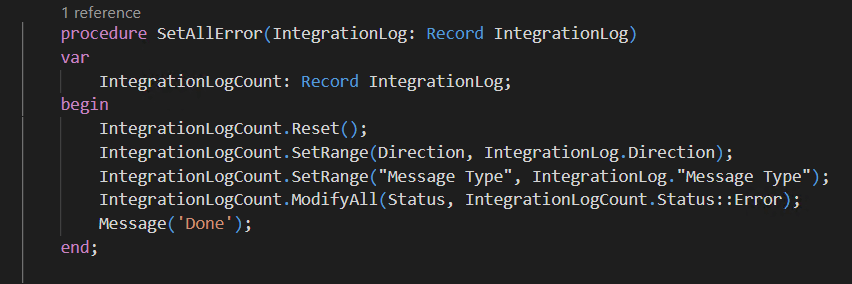
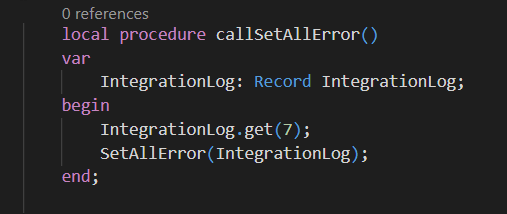
Both, are quite intuitive, the first is setting all the entries, with the same Direction and Message Type of the Record passed through a parameter, as these entries are in error. The second one, getting the entry to use as a model/parameter on my SetAllError.
Due to my default settings, that are remaining with the query timeout on 10 seconds, I’ll get the following results after the PowerShell invocation waited my defaulted 10 seconds…

The loop request made on SetAllProcessed is blocking any other update attempt.
Exploring Solutions on this hypothetical scenario…
The first thing that occurs me right now is… Well, if the ForUpdate parameter on the Findset is locking the table, let’s get rid of it on my procedure. So, my new approach for the procedure can be found on the next image (if you remember earlier we saw that with the LOCKTABLE enabled, we should expect the optimal approach, therefore, with this new way of doing the things we must expect worst efficiency)…
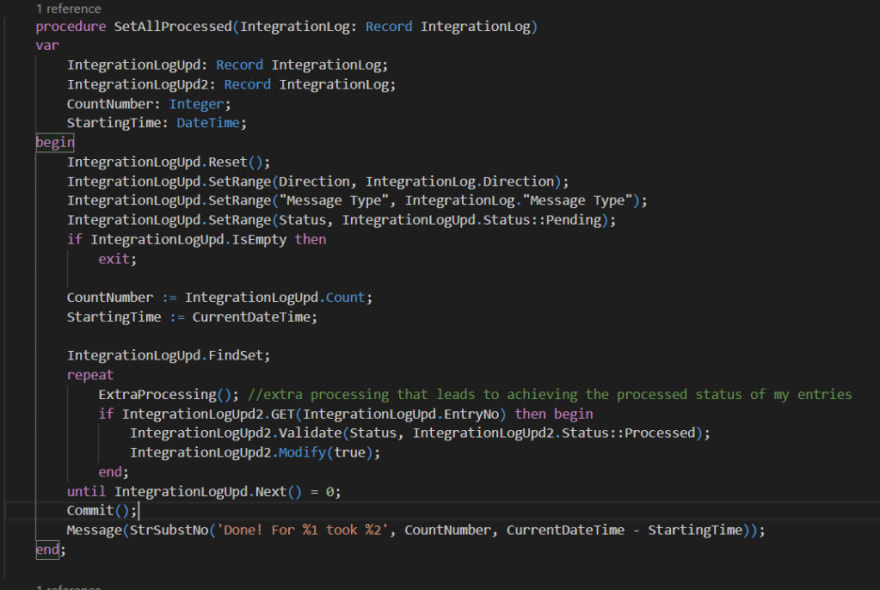
Set All Processed – Procedure – new approach
Let’s see the execution time results for this new approach…
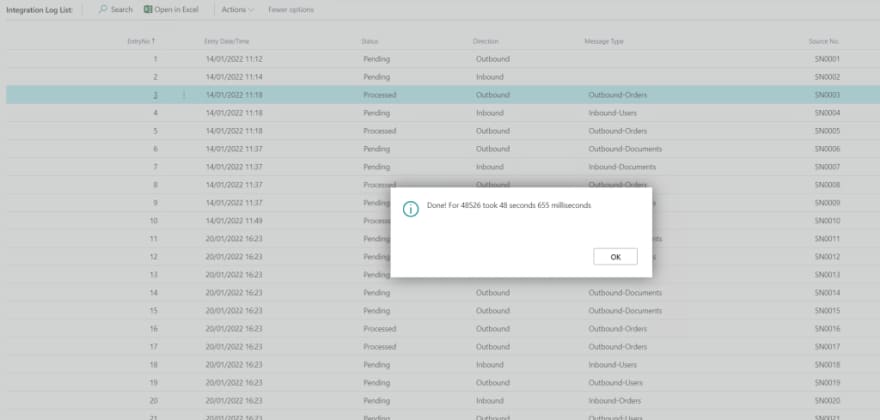
More than 3 times slower, if we compare with when we locked the table. But wait, I can perfectly set this routine to be performed on a background session and live with this slowness, if this resolves my locking issue. Let’s give a new trial on the above execution and also execute another update transaction from the PowerShell invocation.
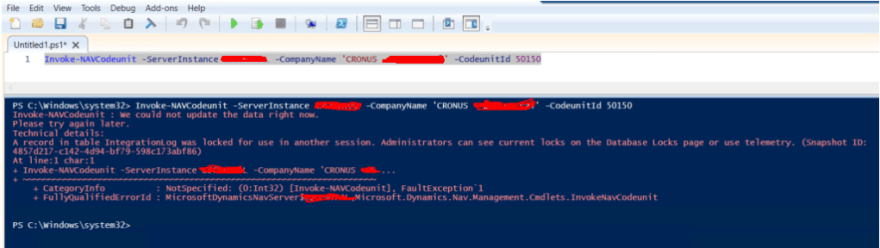
Wait, wait, wait… What the heck!? Facing the same locking issue as before!? But I’m not with LOCKTABLE on… How is this possible?
Since my scenario is operating a quite heavy dataset, the SQL tends to escalate the LockMode, when it is operating massive records, and if it reaches the X of exclusive it’ll behave exactly as if we set the LOCKTABLE. With the help of the following query lets check if this is the case:
--#############################################
--# Transaction With LockMode Exclusive #
--#############################################
SELECT DISTINCT(SessionData.session_id) as spid,RIGHT(obj.name,LEN(obj.name) - charindex('$',obj.name)) as object,tranLocks.request_mode as LockMode, RequestsData.logical_reads as HowManyRows, RequestsData.command as XclusiveLockForCommand,
RequestsData.transaction_id, SessionData.[host_name],RequestsData.text
FROM sys.dm_tran_locks tranLocks
INNER JOIN (SELECT session_id, [program_name],login_name,[host_name],login_time, last_request_end_time
FROM sys.dm_exec_sessions) SessionData ON SessionData.session_id = tranLocks.request_session_id
LEFT JOIN (SELECT session_id,command,[status],blocking_session_id,objectid,transaction_id,logical_reads,text
FROM sys.dm_exec_requests
CROSS APPLY sys.dm_exec_sql_text(sql_handle)) RequestsData ON RequestsData.[session_id] = tranLocks.request_session_id AND RequestsData.transaction_id = tranLocks.request_owner_id
LEFT JOIN (SELECT name,object_id FROM sys.objects) obj ON obj.object_id = tranLocks.resource_associated_entity_id
WHERE RequestsData.command IS NOT NULL AND tranLocks.resource_type = 'OBJECT' AND tranLocks.request_mode = 'X'

And my guess was right, the SQL server was escalating the lock until be exclusive for my first update query that was triggered by my Business Central procedure SetAllProcessed.
What we should look for, as the next step!? Well, we should pursue two things here… Increasing performance and a way to the SQL Server manage concurrency and be able to process more than one request for the same table.
Increase Performance
Here we can switch a little bit of the code by isolating our ExtraProcessing effort from the update, avoiding a few calls to the SQL side… See one possible suggestion:
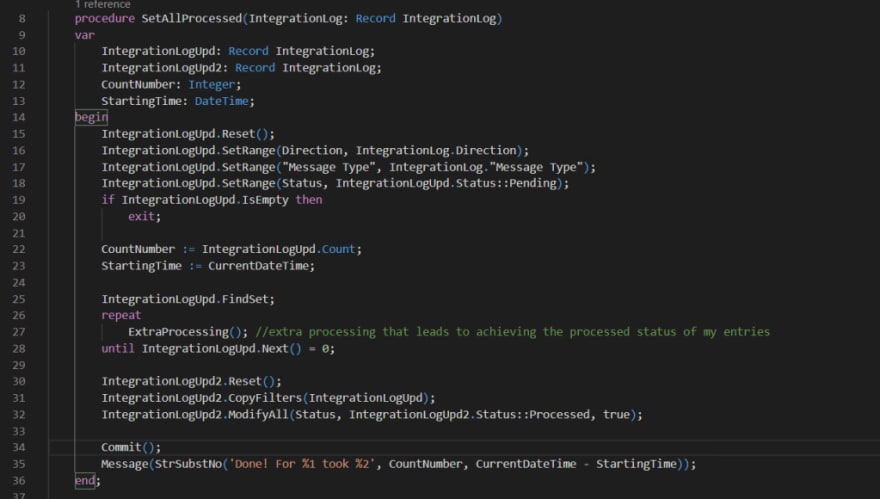
Even with this approach, we are processing everything in one transaction and only committing it at the end, ensuring that the data integrity will remain even if an error occur on one of the steps – an error and all data changes will be rollbacked.
Also batching better the number of entries that are being processed, is a good way of avoiding lock escalation.
Helping SQL Server manage the concurrency
You should be guessing by now how we can do this… by using indexes! Are we missing any!? Well, when I’ve created my table on Business Central, I didn’t concern with the creation of other than the index automatically generated for the primary key (if you missed the post about indexes, it is a good time to jump into it and give it a look).
Let’s check, by using the following code, if the SQL execution plan suggests any missing index.
SELECT mid.equality_columns,
mid.inequality_columns,
mid.included_columns,
RIGHT(mid.statement,LEN(mid.statement) - charindex('$',mid.statement)) AS table_name,
(SELECT Max(rowcnt)
FROM sysindexes
WHERE id = mid.object_id
AND status IN ( 0, 2066 ))
AS [rowcount],
migs.user_seeks,
migs.avg_total_user_cost,
migs.avg_user_impact
FROM sys.dm_db_missing_index_details mid WITH (nolock)
INNER JOIN sys.dm_db_missing_index_groups mig WITH (nolock)
ON mid.index_handle = mig.index_handle
INNER JOIN sys.dm_db_missing_index_group_stats migs WITH (nolock)
ON mig.index_group_handle = migs.group_handle
WHERE database_id = Db_id()
AND user_seeks > 5
ORDER BY avg_user_impact DESC,
user_seeks DESC,
user_scans DESC,
last_user_seek DESC

Missing Indexes Query – Results
Looking at the query results, we have one suggestion to be added. Let’s use the index creation suggested and add a new key for my table.
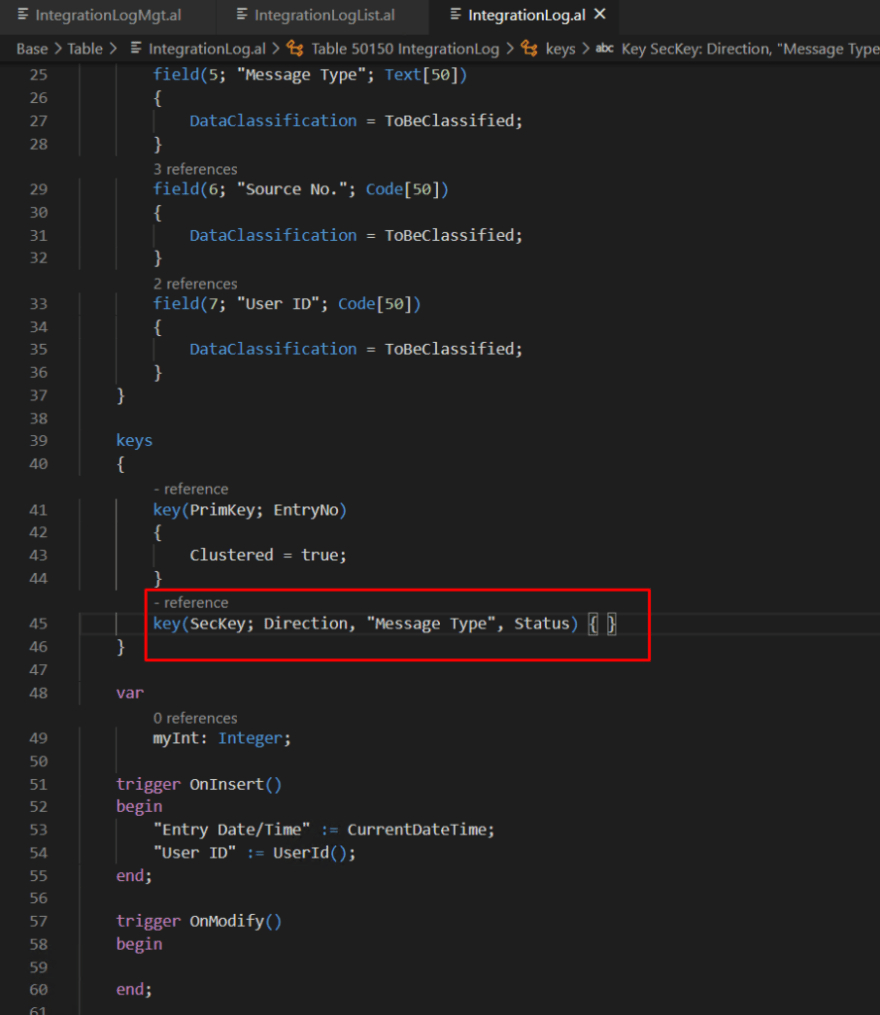
My new key – as suggested by SQL query.
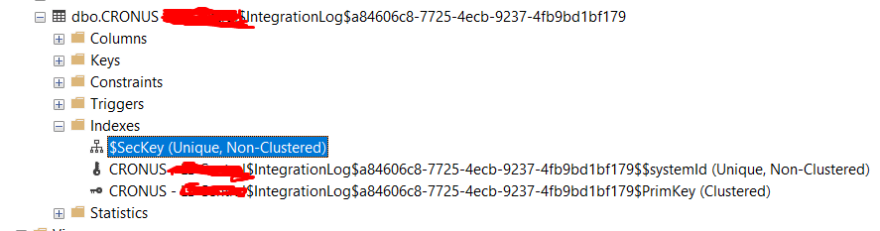
If we give it a look to the SQL side we’ll be able to find the index that was automatically created for this new key, as a non-clustered unique.
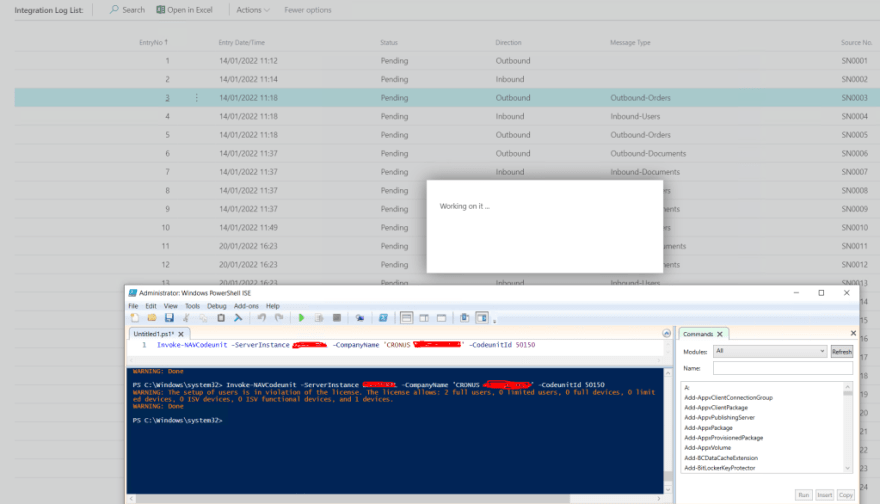
Now, what do you think will happen if I put the two concurrent processes running at the same time with this new key?
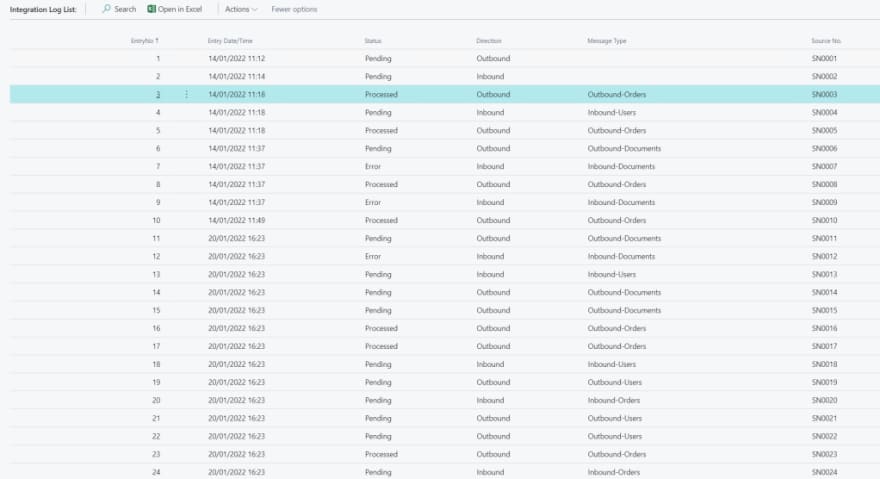
Our locking event is gone… And at same time I was able to set with status Processed all my Outbound-Orders entries and in error all my Inbound-Documents entries.
Conclusion
We, developers, should be careful with our code solutions and try to foresee some of the behaviors on Prod environment, to avoid a few surprises when our code is deployed. I’ve exemplified through a potential scenario of something that could escape from our radar during a development, but even if your challenge is not similar to the above one, you already have on this post some tools/ways to investigate the reason of why you’re getting some of the issues and solve them.
At last but not the least…
On this quite big post, I know that became extensive, you’ve been able to see why I’ve grown my passion on studying SQL Server better and also PowerShell scripting. With all together I was able to create a route map of how to test my Integration Log approach in a way to simulate concurrency transactions context and investigate the reason of errors. I hope that was helpful!
Stay safe!

Top comments (2)
Nice article, I enjoy It quite a lot.
Thank you.
Very Good Article!
Thank You.
PS: the link to the index post is not working.