
An in-depth guide to building a minimal, robust web scraper for extracting structured data on the internets.
Node.js provides a perfect, dynamic environment to quickly experiment and work with data from the web.
While there are more and more visual scraping products these days (import.io, Spider, Scrapinghub, Apify, Crawly, ……), there will always be a need for the simplicity and flexibility of writing one-off scrapers manually.
This post is intended as a tutorial for writing these types of data extraction scripts in Node.js, including some subtle best practices that I’ve learned from writing dozens of these types of crawlers over the years.
In particular, we’ll be walking through how to create a scraper for GitHub’s list of trending repositories. If you want to follow along with the code, check out the repo scrape-github-trending.
Building Blocks
One of the best features of Node.js is the extremely comprehensive community of open source modules it has to offer. For this type of task, we’ll be leaning heavily on two modules, got to robustly download raw HTML, and cheerio which provides a jQuery-inspired API for parsing and traversing those pages.
Cheerio is really great for quick & dirty web scraping where you just want to operate against raw HTML. If you’re dealing with more advanced scenarios where you want your crawler to mimic a real user as close as possible or navigate client-side scripting, you’ll likely want to use Puppeteer.
Unlike cheerio, puppeteer is a wrapper for automating headless chrome instances, which is really useful for working with modern JS-powered SPAs. Since you’re working with Chrome itself, it also has best-in-class support for parsing / rendering / scripting conformance. Headless Chrome is still relatively new, but it will likely phase out older approaches such as PhantomJS in the years to come.
As far as got goes, there are dozens of HTTP fetching libraries available on NPM, with some of the more popular alternatives being superagent, axios, unfetch (isomorphic === usable from Node.js or browser), and finally request / request-promise-native (most popular library by far though the maintainers have officially deprecated any future development).
Getting Started
Alright, for this tutorial we’ll be writing a scraper for GitHub’s list of trending repositories.
The first thing I do when writing a scraper is to open the target page in Chrome and take a look at the how the desired data is structured in dev tools.
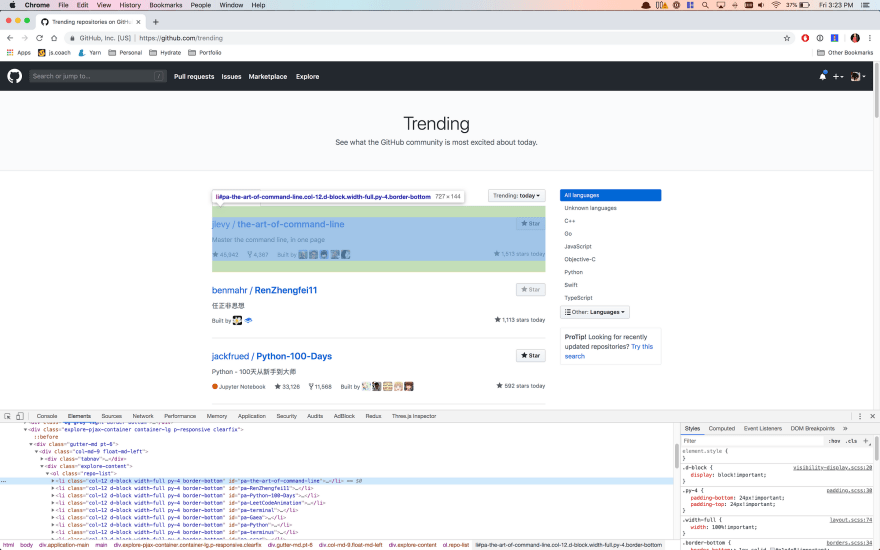
Switching back and forth between the Console and Elements tabs, you can use the $$(‘.repo-list li’) selector in the console to select all of the trending repos.
What you’re looking for in creating these CSS selectors is to keep them as simple as possible while also making them as focused as possible. By looking through the Elements tab and selecting the elements you’re interested in, you’ll usually come up with some potential selectors that may work. The next step is to try them out in the Console tab using the $$() syntax to make sure you’re only selecting the elements you intended to select. One rule of thumb here is to try and avoid using aspects of the HTML’s structure or classes that may change more often in refactors or code rewrites.
Let’s write a scraper!
Now that we have a good idea of some CSS selectors that will target our desired data, let’s convert them to a Node.js script:
Note that we’re using async / await syntax here to handle downloading the external web page asynchronously in a way that looks synchronous.
- Line 12: we download the remote page and extract it’s text
body(HTML). - Line 14: we load that HTML into cheerio so that it’s easy to traverse and manipulate.
- Line 15: we select all the repository
lielements using our previous CSS selector and map over them. - Lines 16–32: we extract the relevant portions of each trending repo into a plain JSON object.
- Line 33: here we’re filtering out any repos that failed to parse correctly or threw an error. These will be
undefinedin the array and[].filter(Boolean)is a shorthand syntax for filtering any non-truthy values.
At this point, we’ve succeeded in scraping a single web page and extracting some relevant data. Here’s some example JSON output at this point:
Crawling Deeper
Now that we’ve explored how to scrape a single page, the next logical step is to branch out and crawl multiple pages. You could even get fancy and crawl links recursively from this point on, but for now we’ll just focus on crawling one level down in this data, that is the repository URLs themselves.
We’ll follow a very similar approach to how we scraped the original trending list. First, load up an example GitHub repository in Chrome and look through some of the most useful metadata that GitHub exposes and how you might target those elements via CSS selectors.
Once you have a good handle on what data you want to extract and have some working selectors in the Console, it’s time to write a Node.js function to download and parse a single GitHub repository.
The only real difference here from our first scraping example is that we’re using some different cheerio utility methods like $.find() and also doing some additional string parsing to coerce the data to our needs.
At this point, we’re able to extract a lot of the most useful metadata about each repo individually, but we need a way of robustly mapping over all the repos we want to process. For this, we’re going to use the excellent p-map module. Most of the time you want to set a practical limit on parallelism whether it be throttling network bandwidth or compute resources. This is where p-map really shines. I use it 99% of the time as a drop-in replacement for Promise.all(…), which doesn’t support limiting parallelism.
Here, we’re mapping over each repository with a maximum concurrency of 3 requests at a time. This helps significantly in making your crawler more robust against random network and server issues.
If you want to add one more level of robustness here, I would recommend wrapping your sub-scraping async functions in p-retry and p-timeout. This is what got is actually doing under the hood to ensure more robust HTTP requests.
All together now
Here is the full executable Node.js code. You can also find the full reproducible project at scrape-github-trending.
And an example of the corresponding JSON output:
Conclusion
I have used this exact pattern dozens of times for one-off scraping tasks in Node.js. It’s simple, robust, and really easy to customize to practically any targeted crawling / scraping scenarios.
It’s worth mentioning that scrape-it also looks like a very well engineered library that is essentially doing everything under the hood in this article.
If your crawling use case requires a more distributed workflow or more complicated client-side parsing, I would highly recommend checking out Puppeteer, which is a game changing library from Google for automating headless Chrome. You may also want to check out the related crawling resources listed in awesome-puppeteer such as headless-chrome-crawler which provides a distributed crawling solution built on top of Puppeteer.
In my experience, however, 95% of the time a simple one-file script like the one in this article tends to do the job just fine. And imho, KISS is the single most important rule in software engineering.
Thanks for your time && I wish you luck on your future scraping adventures!

Top comments (1)
What an insightful guide to web scraping with Node.js! Your tutorial beautifully captures the power of Node.js in data extraction. If you're seeking to enhance your scraping efforts, consider exploring CrawlBase. With its advanced features, Crawlbase complements Node.js seamlessly.