
Browser caching is one of the best ways to take care of your users while also speeding up your website… so why is it so hard?
This article was originally published on 19 October, 2014 at Trezy.com.
Browser caching is a magical thing. Every time you visit a website, the files that make up that site are downloaded to your computer by your browser, which then uses those files to render it for you. This takes time and valuable bandwidth, especially on slower connections. The next time you visit that same site, however, the files needed to render it are already downloaded to your computer. Your browser will use the files it already has to render the site, preventing you from having to waste your bandwidth and wait for the files to download.
Now, this is what happens in a wonderful, magical fairy tale land where all web developers do the right thing and make sure the browser caching is set up on their site. Unfortunately, this is rarely the case. In the spirit of making up statistics, I estimate that somewhere between 30–90% of websites don’t just leverage browser caching, they’re actively working against it.
😞
See, there are a couple of ways to implement browser caching. You can use what’s called a cache-control header, which tells the browser how long it can hold on to the file. If you look at my own website, you can see that the Google Analytics script I’m downloading from Google has this header set.

Two hours isn’t bad. If I revisit my site sometime within the next two hours, my browser will still use the version of that file that I just downloaded. The cool part is that since it’s being served by Google instead of by my server, that file will be cached for every website that uses it, including mine!
However, if Google updates that file within the next 2 hours, I won’t get those changes.
😞😞
This is also a great example of where a lot of websites use a technique called cache busting. Cache busting is where you fool the browser into thinking something like this Google Analytics script is a different file than it previously downloaded, guaranteeing the user always gets the latest version of the file. Developers achieve this by adding something like ?timestamp=2017-10-19T13:04:29.423Z to the end of the filename. It’s just a parameter that uses the current date and time, so the browser always thinks that this file is different and, thus, always downloads a new version. Now, every time I go to that site I’ll have to download a new copy of that file.
😞😞😞
So… is there a better way?
Remember when I said there are a couple of ways to implement browser caching? Let’s talk about that second one, which is called ETags. ETags are something that the server generates and sends along when a browser tries to retrieve a file for the first time. Here’s an example of a fresh request for one of the files served from my website.
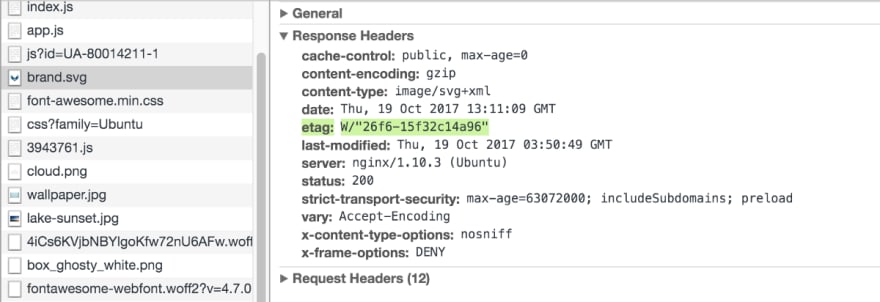
This is my logo, which has an etag header set. This header contains a calculated hash of the file that I’m downloading. The server created that hash for me and sent it up with the file. Now let’s take a look at the second time I request that file.

Since the browser received an etag header when it first downloaded this file, it made sure to send that ETag back to the server in the if-none-match header. The server will compare that ETag against what it calculates for its version of the file. If they don’t match, the server will send a new copy of the file to the browser.
However, if they do match it won’t send back a file at all. Instead it will send back a 304 Not Modified response, telling the browser nothing has changed. The Trezy.com server has just saved me time and bandwidth. Just how much has it actually saved me, though?
On a fresh visit to Trezy.com, the website downloads 781KB of files and takes around 1.34 seconds to finish. That’s just for my very tiny website. For other websites that you visit regularly, you can imagine that those numbers will be much larger.
On a second, cache-friendly visit to my website, though, it only downloads 46.1KB of files and takes 1.05 seconds to finish. That’s a 94% savings in bandwidth, and 22% savings in response times. Again, this is just on my very, very tiny website. Imagine what those savings could look like on a larger website like Facebook or Twitter!
🤔
Let’s take a look at some implementation
We’ll look at the very simple implementation of ETags I used for my website, which runs on a Koa.js server. Below is the core of what koa-etag does. It takes care of making sure that your server’s response have ETags calculated and attached to the responses.
function etag(options) {
return function etag(ctx, next) {
return next()
// `getResponseEntity` checks to see if the response has a body, and
// stringifies it depending on what kind of body it has (JSON, HTML,
// image, etc)
.then(() => getResponseEntity(ctx))
// `setEtag` calculates the ETag from the response body if it exists,
// then sets that ETag as a header
.then(entity => setEtag(ctx, entity, options));
};
}
This isn’t all we need to do, though. The response from the server will still contain the contents of the rest and it will respond with a 200 OK, telling the browser that it’s basically getting a new file. Here’s the missing piece of the puzzle.
function conditional() {
return function conditional(ctx, next) {
return next().then(() => {
if (ctx.fresh) {
ctx.status = 304;
ctx.body = null;
}
});
}
}
Alright, what’s going on here? ctx.fresh is a Koa.js-specific property, but it’s basically checking if the old and new ETags match. This middleware, koa-conditonal-get, uses this property to determine how to proceed. If they do match, the information the browser has is fresh and we don’t need to send anything new along, so we’ll set the status to that nifty little 304 Not Modified and delete the response body, eliminating the need to send who knows how much gobbledy-gook across the wire. If the ETags don’t meet up to Will Smith’s standards, we’ll need to send along the new content.
Make it real!
If you work on one of the 30–90% of websites that don’t implement browser caching, there’s no better time than now to fix it! This is a stupid simple implementation of ETags that may not cut the mustard for a lot of systems, but it’s a great start. It’s not just for websites, either! APIs can leverage ETags to make developer’s lives easier, too. If you have arguments about scalability, I’ll just go ahead and point out to you, Mr. or Mrs. Smarty Pants, that Github implements ETags in their API, so there.
😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁😁

Top comments (0)