選定理由
chatGPTのリリース直後に出たドメイン特化型LLM。今後はこのようなドメイン特化LLMが数多く作られていくと思われる。Bloomberg Terminalに統合されており、利用可能。
Paper: https://arxiv.org/pdf/2303.17564.pdf
Code: N/A
Articles: https://www.itmedia.co.jp/news/articles/2304/07/news064.html
概要
[社会課題] 金融業界では、膨大な量の自然言語データを扱う必要がある。特に、財務報告書やプレスリリースなどの文書データは、ステークホルダーにとって重要な情報源であり、それらを適切に解釈することが必要となる。
[技術課題] 金融分野のテキストデータに適したLLMはまだ提案されていなかった。
[提案内容] アナリストが40年以上にわたって金融の文書を収集・管理し、3630億トークンデータセット "FinPile" を作成した。これに3450億トークンの一般的な公開データセットを加え、7000億トークンを超える大規模な学習用コーパスを作成した。この学習コーパスの一部を用い、500億パラメータのデコーダーのみの言語モデルをトレーニングした。
[効果] 金融分野のテキストデータに対する自然言語処理技術が大幅に向上した。具体的には、質問応答、文章要約、情報抽出、感情分析、投資ポートフォリオの構築など、金融分野の様々なタスクに対して高い精度での予測が可能で、情報収集や分析の効率化、投資判断の支援などに活用できる。
モデル
GPT系そのままでなく、特有のカスタマイズがある。
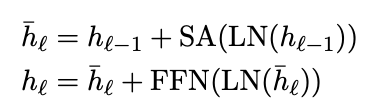
上記のようなSA(self-attension)層とLN(Layer Normalization)層とFFN(feed-forward network)のブロックを70層重ねたものである。
実験
実験では、BloombergGPTが多くの金融タスクにおいて、SOTAの結果を達成したことが示された。さらに、BloombergGPTの性能を向上させるために、金融に特化したトレーニングデータを用いることの重要性も示された。
学習環境は Amazon SageMaker にてp4d.24xlarge インスタンスを64個使用した。これは 40GB A100 GPUが512枚分に相当する。
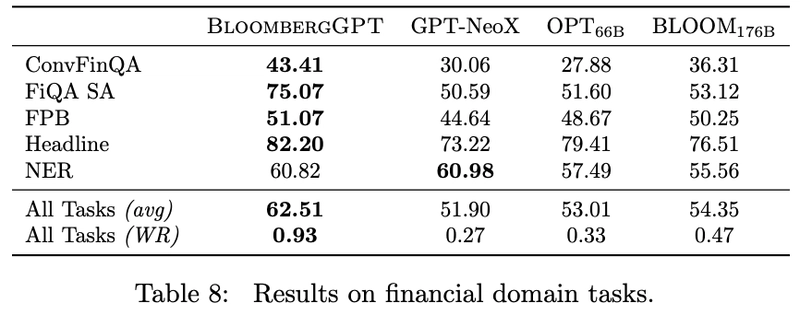
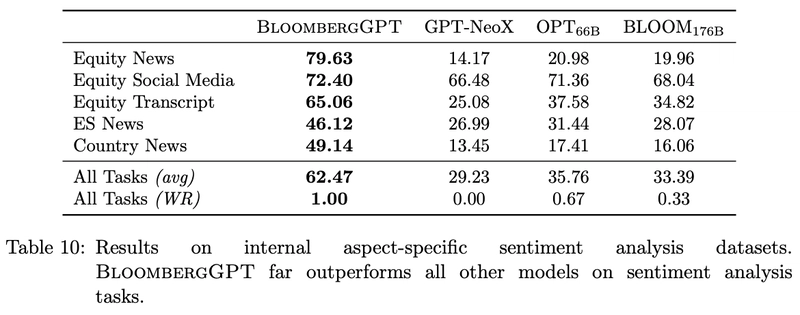
ファイナンス特化モデルであるため、金融ドメインのデータにはもちろん強い。
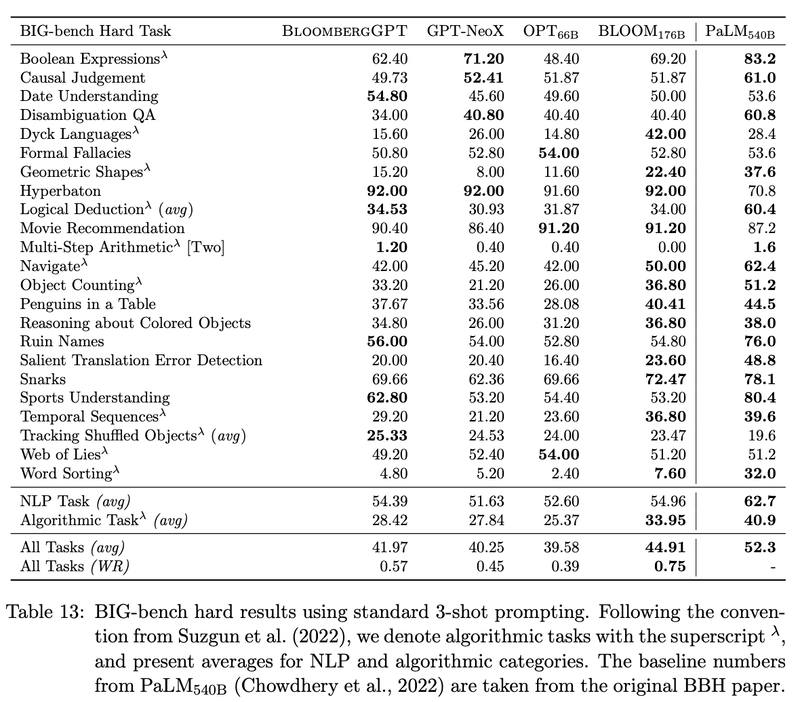
学習時にファイナンス以外のデータも一緒に学習しているため、破滅的忘却を起こさない。

Top comments (0)